
今天来分享一篇蚂蚁金服在WSDM2022中稿的重排序的文章,建模用户在浏览过程中自上而下的全局item相互影响以及局部视野范围内item的相互影响,一起来学习一下。
1、背景
信息流场景下,用户的行为会受到相邻展示的item的影响,如价格敏感的用户会对比相邻展示的item的价格,选择价格相对较低的item进行购买。而在精排阶段,出于耗时上的考虑,大都采用point-wise的建模方式,无法建模相邻item的相互影响,因此在精排之后,大都引入重排序(re-ranking)模块,来对这种item的相互影响进行建模,决策更好的item的展示顺序。
咱们先来简单回顾一下重排的一些做法(此处为个人总结,非论文中的内容,不妥当的地方可指出,相互交流),主要分为两类:直接生成最优序列和序列生成+序列评估两阶段。
1)直接生成最优序列如阿里的PRM,基于精排结果,使用transformer建模item之间的相互影响, 输出新的item打分,这种方法存在明显的缺陷,即evaluation-before-reranking问题,经过重排序后得到的顺序与最初的顺序是不同的,如果按照重排序的顺序输入到模型中,得到的预测结果可能不同。另一种直接生成最优序列的方法的方法如引入PG(policy gradient)模型,这类方法需要在训练过程中对生成序列进行合适的打分,通常需要引入预训练好的序列评估模型,因此在训练过程中往往也是两阶段的,但在线上预测的时候可以直接生成最优序列。
2)当前重排最常用的是序列生成+序列评估两阶段范式,序列生成方法可以采用启发式方法,也可以采用模型生成的方法如阿里的PRS,使用Beam-Search的方法生成多个候选序列。序列评估方法可以引入RNN,Transformer等建模相邻item的相互影响,做到更准确的序列评估。
本文感觉是阿里之前提出的PRM论文的延续,仍然存在evaluation-before-reranking的问题,但本身的创新点还是值得借鉴的。在信息流的浏览过程中,用户的浏览行为存在以下两种特性:
1)单向性(Unidirectivity):用户在信息流的浏览过程中大都是从上往下浏览,很少来回进行物品的对比。信息流中下文展示的item对上文展示的item的影响是十分有限的,但上文展示的item对下文展示的item却有非常大的影响,论文称具有锚定效应(anchoring effect ),即第一印象或第一信息更容易支配人们的判断。因此建模下文对上文的影响对于整体的模型效果可能是有损的。
2)局部性(Locality):当用户停下来观察某一个具体的item时,他们倾向于将其与局部视野下相邻展示的其他item进行对比。大多数用户行为,例如点击或购买,主要发生在一个狭窄的可视窗口中,如下图所示。而目前大多数论文,忽略了局部视野信息的建模。
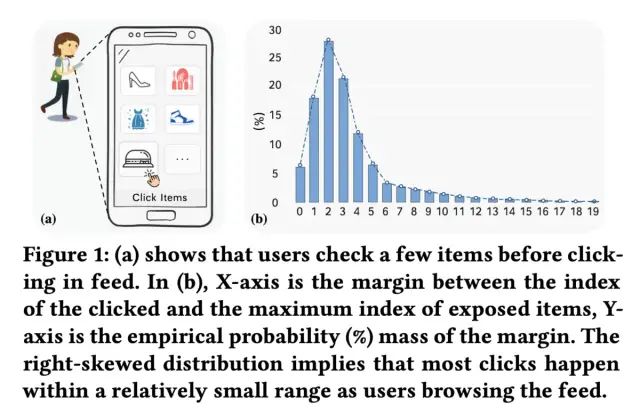
因此,为了显式建模用户在浏览过程中自上而下的全局item相互影响以及局部视野范围内item的相互影响,论文提出了一种新颖的re-ranking模型,称做 Scope- aware Re-ranking with Gated Attention model (以下简称SRGA),接下来,我们对SRGA模型进行具体的介绍。
2、SGRA模型介绍
SGRA模型如下图所示,整体分为四个部分:Input Layer,PI Layer,Gated Attention Layer和Output Layer,接下来对各层进行介绍:
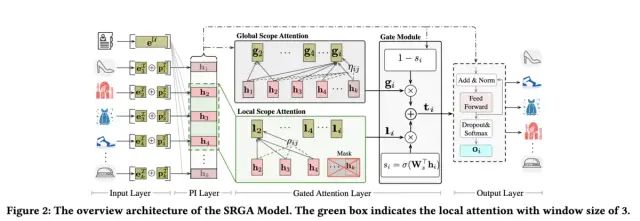
2.1 Input Layer
输入层主要包含了两部分,用户特征以及精排阶段得到的item序列。用户特征用xU表示,item特征用xI表示。输入特征首先转换为对应的embedding,这里值得一提的是,item特征在转换为对应的embedding时,会加上其对应的position embedding,用于刻画位置信息:
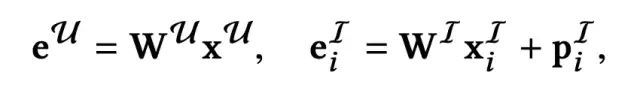
2.2 Personalized Interaction Layer
PI层用于计算用户对于单个item的兴趣,具体计算如下:
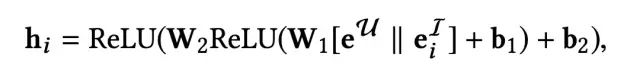
2.3 Gated Attention Layer
Gated Attention Layer为本文的核心创新点所在,包含了三个模块:Global Scope Attention(GSA)、Local Scope Attention (LSA)和Gate Moudle。
经过PI层得到的向量表示,首先会计算item之间的相互影响权重,这里与Self-Attention的计算相同:
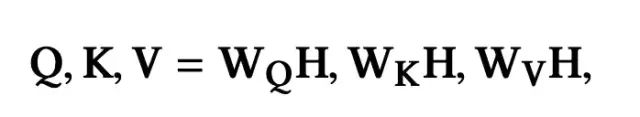
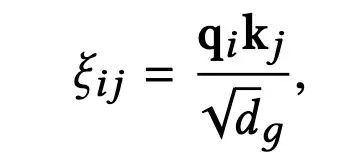
Global Scope Attention(GSA)
GSA主要用于建模全局item之间的相互影响, 如在背景中的介绍,用户在信息流中的浏览过程具有单向性,因此,对于上一步得到的attention权重,在softmax之前,首先将排在后面的item对于排在前面的item的attention权重转换为无穷小,计算公式如下:
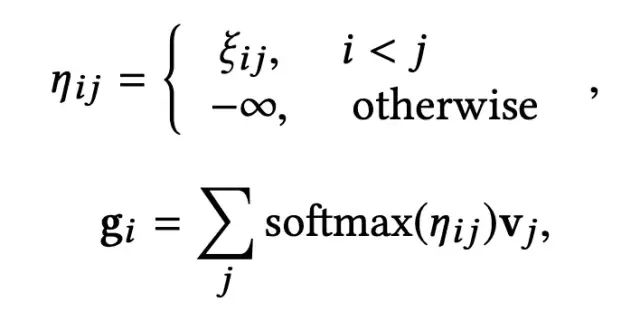
Local Scope Attention (LSA)
LSA主要建模大小为m的(m为超参数)局部视野下item之间的相互影响,这种相互影响是双向的。以item i为例,只考虑前后m/2个item对其的影响,计算过程如下:
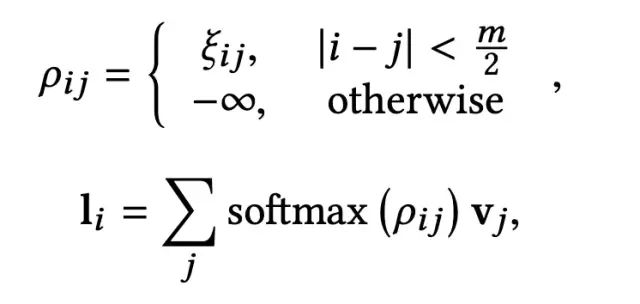
Gate Moudle
经过GSA和LSA模块,分别得到了全局影响和局部视野影响下的每个item的向量表示,接下来,通过Gate Moudle来刻画哪种影响会对用户行为产生更大的作用:
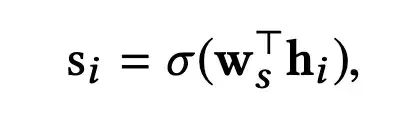
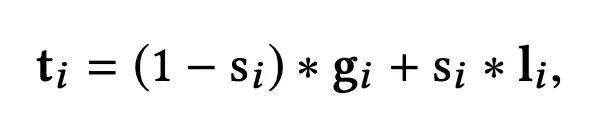
另外,Gate Moudle得到的向量表示ti会经过residual connection,layer normalization和position-wise feed-forward layer,来得到喂给最终输出层的item表示,计作oi。
2.4 Output Layer
接下来,每个item的向量表示oi经过全连接层,得到点击率预估值,并使用logloss进行模型训练和参数更新:
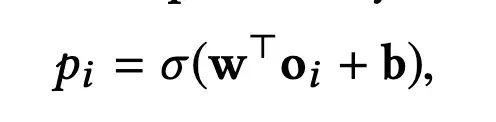
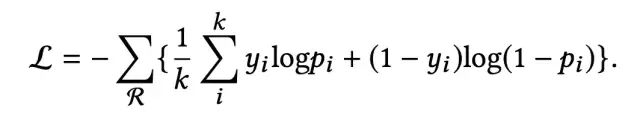
3、实验结果及分析
论文提出的SGRA模型,在多个数据上都取得了相较于base模型正向的效果:
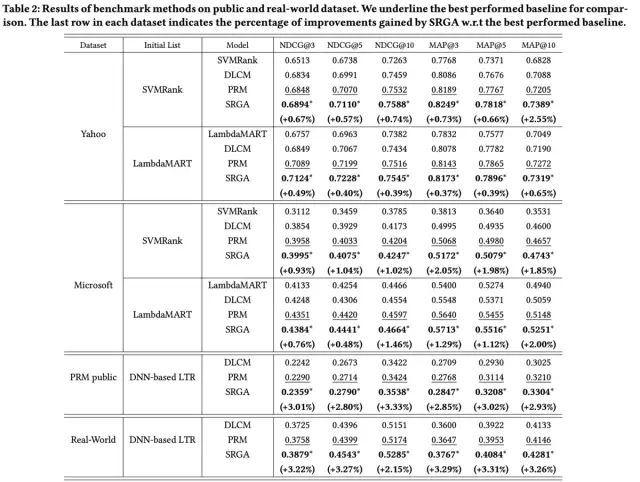
具体的实验分析以及消融实验,本文不再做具体介绍。
4、总结
尽管本文所提出的重排方法存在evaluation-before-reranking的问题,但是其对用户在信息浏览过程中全局注意力以及局部视野注意力的刻画,具有很好的借鉴意义。
本文的介绍就到这里,感兴趣的同学可以阅读原文~
往期推荐:
推荐系统遇上深度学习(一三零)-[阿里]电商搜索CTR预估中页面级反馈建模
推荐系统遇上深度学习(一二九)-基于物品属性的用户关注列表序列推荐










