公众号:尤而小屋
作者:Peter
编辑:Peter
本文记录的是如何通过Pandas来读取Excel文件,以及如何将DataFrame保存到Excel文件中。
官网参数详解:https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
参数
read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。支持读取单一sheet或几个sheet。
下面记录的官方文档中提供的全部参数信息:
pandas.read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=None,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
decimal='.',
comment=None,
skipfooter=0,
convert_float=None,
mangle_dupe_cols=True,
storage_options=None
)
下面解释常用参数的含义:
- io:文件路径,支持 str, bytes, ExcelFile, xlrd.Book, path object, or file-like object。默认读取第一个sheet的内容。案例:"/desktop/student.xlsx"
- sheet_name:sheet表名,支持 str, int, list, or None;默认是0,索引号从0开始,表示第一个sheet。案例:sheet_name=1, sheet_name="sheet1",sheet_name=[1,2,"sheet3"]。None 表示引用所有sheet
- header:表示用第几行作为表头,支持 int, list of int;默认是0,第一行的数据当做表头。header=None表示不使用数据源中的表头,Pandas自动使用0,1,2,3…的自然数作为索引。
- names:表示自定义表头的名称,此时需要传递数组参数。
- index_col:指定列属性为行索引列,支持 int, list of int, 默认是None,也就是索引为0,1,2,3等自然数的列用作DataFrame的行标签。如果传入的是列表形式,则行索引会是多层索引
- usecols:待解析的列,支持 int, str, list-like, or callable ,默认是 None,表示解析全部的列。
- dtype:指定列属性的字段类型。案例:{‘a’: np.float64, ‘b’: np.int32};默认为None,也就是不改变数据类型。
- engine:解析引擎;可以接受的参数有"xlrd"、"openpyxl"、"odf"、"pyxlsb",用于使用第三方的库去解析excel文件
- “xlrd”支持旧式 Excel 文件 (.xls)
- “openpyxl”支持更新的 Excel 文件格式
- “odf”支持 OpenDocument 文件格式(.odf、.ods、.odt)
- converters:对指定列进行指定函数的处理,传入参数为列名与函数组成的字典,和usecols参数连用。key 可以是列名或者列的序号,values是函数,可以自定义的函数或者Python的匿名lambda函数
- skiprows:跳过指定的行(可选参数),类型为:list-like, int, or callable
- nrows:指定读取的行数,通常用于较大的数据文件中。类型int, 默认是None,读取全部数据
- keep_default_na:是否导入空值,默认是导入,识别为NaN
模拟数据
现在本次模拟了两个数据:Pandas_Excel.xls 和 Pandas_Excel.xlsx
Pandas_Excel.xls 文件中包含两个sheet,第二个数据只比第一个多个index的信息
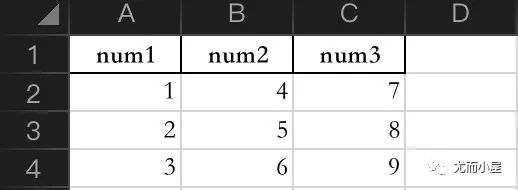
1、sheet1的内容
 image-20220423115151077
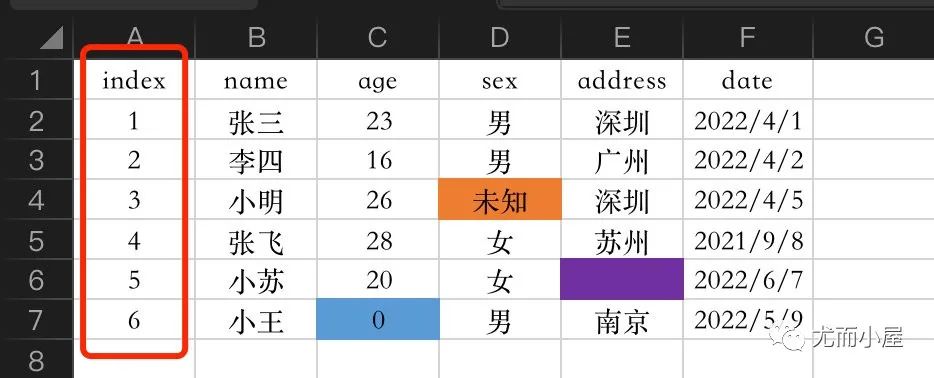
image-202204231151510772、sheet2的内容
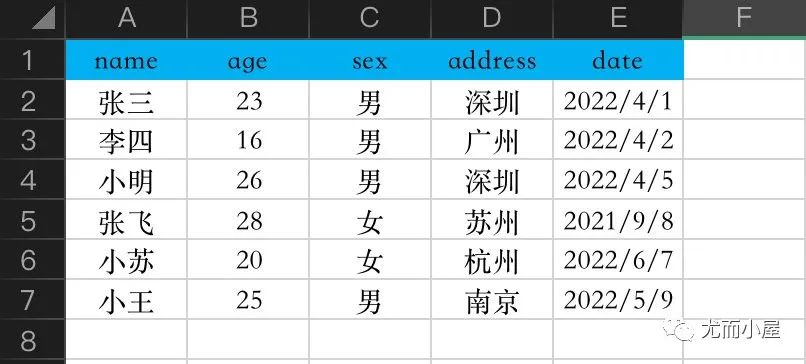
3、Pandas_Excel.xlsx的内容,模拟的完整信息:
import pandas as pd
默认情况
此时文件刚好在当前目录下,读取的时候指定文件名即可,可以看到读取的是第一个sheet
df = pd.read_excel("Pandas-Excel.xls")
df
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN |
2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数io
填写完整的文件路径作为io的取值。也可以使用相对路径
pd.read_excel(r"/Users/peter/Desktop/pandas/Pandas-Excel.xls")
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数sheet_name
# pd.read_excel("Pandas-Excel.xls", sheet_name=0) # 效果同上
# 直接指定sheet的名字
pd.read_excel("Pandas-Excel.xls", sheet_name="Sheet1") # 效果同上
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
换成读取第二个sheet:名称是Sheet2
pd.read_excel("Pandas-Excel.xls", sheet_name="Sheet2")
| index | name | age | sex | address | date |
|---|
| 0 | 1 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 2 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 3 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 4 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 5 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 6 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
结果中多了一列index的取值
参数header
# 和默认情况相同
pd.read_excel("Pandas-Excel.xls", header=[0])
|
name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
pd.read_excel("Pandas-Excel.xls", header=[1]) # 单个元素
第一行的数据当做列属性:
| 张三 | 23 | 男 | 深圳 | 2022-04-01 00:00:00 |
|---|
| 0 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
| 1 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 2 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 3 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 4 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
传入多个元素会形成多层索引:
pd.read_excel("Pandas-Excel.xls", header=[0,1]) # 多个元素
| name | age | sex | address | date |
|---|
| 张三 | 23 | 男 | 深圳 | 2022-04-01 00:00:00 |
|---|
| 0 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 1 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
| 2 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 3 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 4 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数names
# 指定列名称
pd.read_excel("Pandas-Excel.xls", names=["a","b","c","d","e"])
| a | b | c | d | e |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数index_col
# 指定单个元素作为索引
pd.read_excel("Pandas-Excel.xls", index_col=[0])
| age | sex | address | date |
|---|
| name |
|
|
|
|
|---|
| 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 张飞 | 28 | 女 | 苏州 |
2021-09-08 |
|---|
| 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
# 多个元素
pd.read_excel("Pandas-Excel.xls", index_col=[0,1])
|
| sex | address | date |
|---|
| name | age |
|
|
|
|---|
| 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 小苏 | 20 | 女 | NaN |
2022-06-07 |
|---|
| 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数usecols
pd.read_excel("Pandas-Excel.xls", usecols=[0]) # 单个字段
pd.read_excel("Pandas-Excel.xls", usecols=[0,2,4]) # 多个字段
| name | sex | date |
|---|
| 0 | 张三 | 男 | 2022-04-01 |
|---|
| 1 | 李四 | 男 |
2022-04-02 |
|---|
| 2 | 小明 | 未知 | 2022-04-05 |
|---|
| 3 | 张飞 | 女 | 2021-09-08 |
|---|
| 4 | 小苏 | 女 | 2022-06-07 |
|---|
| 5 | 小王 | 男 | 2022-05-09 |
|---|
# 直接指定名称
pd.read_excel("Pandas-Excel.xls", usecols=["age","sex"])
| age | sex |
|---|
| 0 | 23 | 男 |
|---|
| 1 | 16 | 男 |
|---|
| 2 | 26 | 未知 |
|---|
| 3 | 28 | 女 |
|---|
| 4 | 20 | 女 |
|---|
| 5 | 0 | 男 |
|---|
# 传入匿名函数,字段中包含a,结果sex没有了
pd.read_excel("Pandas-Excel.xls"
, usecols=lambda x: "a" in x)
| name | age | address | date |
|---|
| 0 | 张三 | 23 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 南京 | 2022-05-09 |
|---|
参数dtype
df.dtypes
name object
age int64
sex object
address object
date datetime64[ns]
dtype: object
从上面的结果中看到age字段,在默认情况下读取的是int64类型:
# 指定数据类型
df1 = pd.read_excel("Pandas-Excel.xls", dtype={"age":"float64"})
# 查看字段信息
df1.dtypes
name object
age float64 # 修改
sex object
address object
date datetime64[ns]
dtype: object
参数engine
# xls 结尾
pd.read_excel("Pandas-Excel.xls", engine="xlrd")
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
# xlsx 结尾
pd.read_excel("Pandas-Excel.xlsx", engine="openpyxl")
|
name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 男 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | 杭州 | 2022-06-07 |
|---|
| 5 | 小王 | 25 | 男 | 南京 | 2022-05-09 |
|---|
参数converters
pd.read_excel("Pandas-Excel.xlsx") # 默认操作
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 男 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | 杭州 | 2022-06-07 |
|---|
| 5 | 小王 | 25 | 男 | 南京 | 2022-05-09 |
|---|
pd.read_excel("Pandas-Excel.xlsx",
usecols=[1,3], # 1-age 3-address 数值为原索引号
converters={0:lambda x: x+5, # 0代表上面[1,3]中的索引号
1:lambda x: x + "市"
})
| age | address |
|---|
| 0 | 28 | 深圳市 |
|---|
| 1 | 21 | 广州市 |
|---|
| 2 | 31 | 深圳市 |
| 3 | 33 | 苏州市 |
|---|
| 4 | 25 | 杭州市 |
|---|
| 5 | 30 | 南京市 |
|---|
参数skiprows
pd.read_excel("Pandas-Excel.xls") # 默认情况
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 |
女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
把张三和李四所在的行直接跳过:
pd.read_excel("Pandas-Excel.xls", skiprows=2)
| 李四 | 16 | 男 | 广州 | 2022-04-02 00:00:00 |
|---|
| 0 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 1 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 2 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 3 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
# 跳过偶数行
pd.read_excel("Pandas-Excel.xls", skiprows=lambda x: x%2 == 0)
| 张三 | 23 | 男 | 深圳 | 2022-04-01 00:00:00 |
|---|
| 0 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 1 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
参数nrows
# 指定读取的行数
pd.read_excel("Pandas-Excel.xls", nrows=2)
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
参数na_values
pd.read_excel("Pandas-Excel.xls") # 默认
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 |
深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
pd.read_excel("Pandas-Excel.xls",
na_values={"sex":"未知"})
sex字段中的未知显示成了NaN:
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | NaN | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
参数keep_default_na
pd.read_excel("Pandas-Excel.xls") # 默认keep_default_na=True
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
| 4 | 小苏 | 20 | 女 | NaN | 2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
pd.read_excel("Pandas-Excel.xls", keep_default_na=False)
| name | age | sex | address | date |
|---|
| 0 | 张三 | 23 | 男 | 深圳 | 2022-04-01 |
|---|
| 1 | 李四 | 16 | 男 | 广州 | 2022-04-02 |
|---|
| 2 | 小明 | 26 | 未知 | 深圳 | 2022-04-05 |
|---|
| 3 | 张飞 | 28 | 女 | 苏州 | 2021-09-08 |
|---|
| 4 | 小苏 | 20 | 女 |
|
2022-06-07 |
|---|
| 5 | 小王 | 0 | 男 | 南京 | 2022-05-09 |
|---|
输出到excel文件
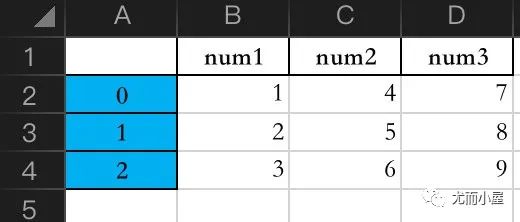
简单模拟一份数据:
df2 = pd.DataFrame({"num1":[1,2,3],
"num2":[4,5,6],
"num3":[7,8,9]})
df2
df2.to_excel("newdata_1.xlsx")
效果如下:
df2.to_excel("newdata_2.xlsx",index=False)
不会带上索引号