
作者:Dr. Dataman
译者:刘媛媛
过去三十年来,研究学者在图像识别算法和图像数据集方面做了许多工作,积累了宝贵的知识经验。如果你对图像训练感兴趣,但又不知道从何开始。那么,我希望这篇文章可以为你提供一个很好的开始。
这篇文章简要介绍了过往的演变,并指出了当代热点话题。阅读本文后,你将熟悉以下主题:
丨ImageNet
丨预训练模型
丨迁移学习(热门主题)
丨使用预训练模型去识别一张未知图像
丨PyTorch
一、ImageNet的起源
基于监督学习的卷积神经网络模型的训练依赖于图像数据。在2000年代初期,大多数AI研究人员专注于图像分类问题的模型算法,但是由于缺乏大规模的数据样本使其具有很大的挑战性。
研究人员需要大量的图像及其对应的标签来训练模型,于是,ImageNet数据集就此诞生。
在科学研究中,两个学科交叉时可以碰撞出新的火花。
ImageNet由斯坦福大学人工智能研究员李飞飞构思和带头。2007年,当她开始构思ImageNet的想法时,她首先去会见了普林斯顿大学教授Christiane Fellbaum—— WordNet 的创建者之一,与他讨论了ImageNet项目。
WordNet是一个自然语言处理(NLP)的词汇数据库,用于记录名词、动词、附属词和副词之间的语义关系。
它有155,327个词汇,分为175,979个同义词,称为synsets(有些词汇只有一个synset,有些有几个)。
如果将图像附在WordNet中的词上,那不是很好吗?这就是ImageNet的起源。
ImageNet将成百上千的图像与WordNet中的同义词联系起来。从那时起,ImageNet就对计算机视觉和深度学习的发展起到了重要作用。这些数据可供研究人员免费使用,用于非商业用途。
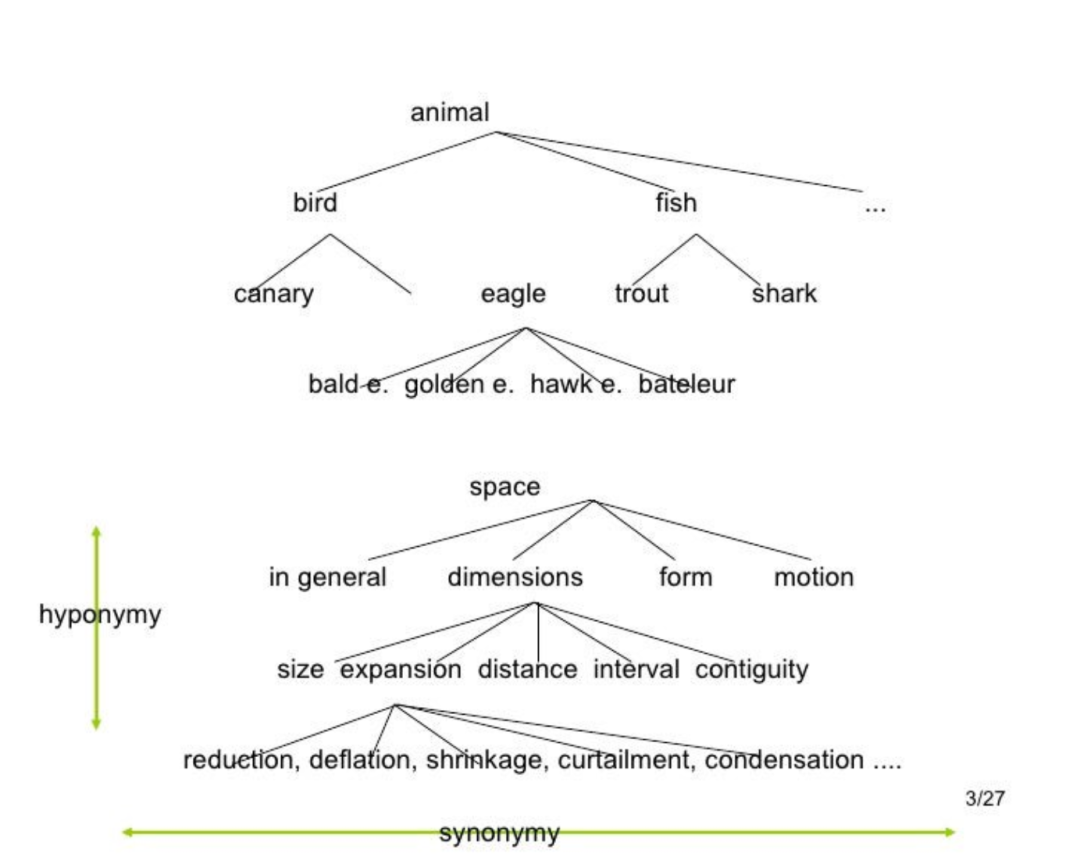
ImageNet数据库有超过1400万张图片(14,197,122),被组织成21,841个子类别。数据集中的每张图片都是由人类注释的,并经过多年的质量控制。
ImageNet中的大多数同义词是名词(80,000多个),总共有100,000多个同义词。因此,ImageNet是一个组织良好的层次结构,使其对监督机器学习任务非常有用。你可以通过ImageNet网站自己注册,免费访问ImageNet。
有了大型图像数据库,研究人员可以随意开发他们的算法。
于是,著名的ImageNet大规模视觉识别挑战赛(ILSVRC)来了。这是一个在2010年至2017年间举行的年度计算机视觉竞赛。
它也被称为ImageNet挑战赛。挑战赛中的训练数据是ImageNet的一个子集。1,000个synsets(类别)和120万张图像。
你对这1,000个语料库感兴趣吗?请从https://deeplearning.cms.waikato.ac.nz/user-guide/class-maps/IMAGENET/ 查看。稍后我还会告诉你如何在代码中加载它。
ImageNet挑战赛激励了许多伟大的图像分类模型。
这些模型的训练规模庞大、耗时长且依赖于CPU/GPU强大算力。提供这些模型的开发人员希望为机器学习社区做出贡献以解决类似的问题。
每个模型都包含代表 ImageNet 中图像特征的权重和偏差。它们被称为预训练模型,因此其他研究人员可以使用它们来解决类似的问题。
1)LeNet-(1989):一个经典的卷积神经网络(CNN)框架LeNet-5 是最早提出的卷积神经网络之一。其框架结构简单,因此许多课程将其用作引入CNN的第一个模型。1989年,贝尔实验室的Yann LeCun等人将一个由反向传播算法训练的卷积神经网络结合起来,用于读取手写数字,并成功地将其应用于识别美国邮政提供的手写邮编号码。AlexNet在 2012 年 ImageNet 挑战赛中登上舞台,因为它以非常大的优势获胜。它实现了top5错误率为17%,top2错误率为 26%。它的架构与 LeNet-5 非常相似。它是由 Alex Krizhevsky、Ilya Sutskever 和 Krizhevsky 的博士导师 Geoffrey Hinton 合作设计。该模型包含6000 万个参数和 500万个神经元。GoogLeNet是由谷歌研究院的Christian Szegedy 等人设计开发。该模型的参数量比 AlexNet 少 10 倍,大约 600 万左右。牛津大学K. Simonyan 和 A. Zisserman等人在他们的论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出了VGG-16 模型。他们使用非常小的 3x3卷积滤波器将网络深度增加到 16 层和 19 层。这种架构显示出显着的改进。VGG-16 名称中的“16”指的是 CNN 的“16”层。它大约有1.38 亿个参数。显然 VGG-19 比 VGG-16参数量更大,同时精度更高。大多人更倾向于使用 VGG-16。这深度神经网络的各层通常被设计为学习尽可能多的特征。Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun在他们的论文《Deep Residual Learning for Image Recognition(图像识别的深度残差学习)》中提出了一个新的架构。他们提出了一个残差学习框架。各层被制定为学习参考层输入的残差函数,而不是学习未参考的函数。他们表明,这些残差网络更容易优化,并能从大大增加的深度中获得准确性。ResNet-50中的 "50 "指的是50层。ResNet模型在ImageNet挑战赛中以错误率仅为3.57%而赢得了比赛。当我们遇到新任务时,我们会从以前学习经验中识别并应用相关的知识。迁移学习技术是一项伟大的发明。它“转移”在先前模型中学习的知识,以改善当前模型中的学习。任何预训练模型都具有数百万个参数,模型参数中包含了学习到的图像特征。如果你的任务相似,那么利用预训练模型中的知识(参数)是有意义的。
迁移学习技术让你可以利用预训练模型来完成类似的任务,而不需要重复训练大规模的模型,并且可以依赖更少的数据。如果你有一组新图像,需要构建自己的图像识别模型,那么,就可以在你的神经网络模型中包含一个已经训练好的预训练模型。 因此,迁移学习技术成为了近年来的热门话题。我们可以预见两个研究前沿:(ii)将产生越来越多的迁移学习模型以满足特定需求。 然而,对于缺乏企业平台和资源的个体研究人员来说,图像数据的存储、格式化或创建并非易事。Image Hub 旨在让研究人员存储图像、音频、视频及其标签。你可以将数据保存在本地或者保存在Image Hub的 Activeloop存储中。另外,你只需通过‘pip install hub’命令,便可以安装对应的Python包。它包含了所有主要的图像数据集:在本节中,我将向你展示如何使用 VGG-16 预训练模型来识别图像。(iii) 如何应用预训练模型。你可以通过此链接下载整个 python notebook。在图像建模中,研究人员广泛使用PyTorch、TensorFlow 或 Keras等。其中,PyTorch 是 Facebook 的 AI 研究实验室基于Torch 库开发的基于Python的开源机器学习库。
它以深度学习计算而闻名,因为其具有最大的灵活性和速度。目前它在图像识别、计算机视觉和自然语言处理等领域都有着广泛应用。PyTorch是 NumPy 的替代品,可以使用GPU的强大算力。Google 的 TensorFlow 是另一个著名的开源深度学习库,用于一系列任务的数据流和可微分编程。PyTorch和TensorFlow 都非常适合 GPU 计算。PyTorch中包含了许多预训练模型。从Pytorch 模型列表中选择一个预训练模型。我们选择“VGG-16”模型,如下所示:上面的第 10 行加载了 VGG-16 模型。你可以将其打印出来以查看其架构,如下所示:
如前所述,VGG-16 在 ImageNet 挑战赛中接受了1,000 个同义词组(类别)和 120 万张图像的训练,可以从此 PyTorch 页面下载 1,000 个同义词组标签。
下面我将它保存到本地目录“/Downloads”并加载到一个名为“labels”的列表中。在下面的第 2 行中,我用谷歌搜索了“goldfish(金鱼)”,并从谷歌图片中随机选择了一张金鱼图片。在第 3 行中,我还搜索了“eagle(老鹰)”,并随机选择了一张带有图片地址的老鹰图片。
请注意,你只需在图片地址后面添加 ?raw=true,然后你的 url 将直接访问图片。你可以按照相同的步骤选择你喜欢的任何图像。图像可以由 Python Imaging Library(缩写为 PIL,或称为 Pillow 的较新版本)加载。单击此处查看此库如何帮助你打开、操作和保存图像。
第13行:图像的大小是(1600,1071)。这意味着该图像是一个1600 x 1071像素的文件。你可以看看我的这篇文章《用PyTorch进行深度学习并不折磨人》。该文章解释了如何用Numpy数组表示一个RGB图像文件。所有预训练的模型都希望输入的图像以同样的方式归一化,即:最小批次为形状(3 x H x W)的3通道RGB图像,其中H和W预计至少为224。上面的第2、3行:将图像大小标准化为[3,224,224]。第5行:图像必须用mean=[0.485, 0.456, 0.406]和std=[0.229, 0.224, 0.225]进行标准化。上面的第1行:是最重要的步骤。它预测了图像是什么。输出是1000个ImageNet系统上的1000个值的列表。上面的代码打印出前五个概率和标签。我们输入了一张老鹰的图像。VGG-16模型将该图像识别为 "bald eagle(秃鹰)",概率为0.9969。
你可以通过这个链接(https://github.com/dataman-git/codes_for_articles/blob/master/VGG-16.ipynb)下载Python notebook。在你选择的任何图像上重复上述程序。另外,你还可以选择其他预训练的模型来看看它们的结果,你可能会对这些预训练的模型感到惊讶。

-
- 机器学习交流qq群955171419,加入微信群请扫码:










