
量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业30W+关注者,连续2年被腾讯云+社区评选为“年度最佳作者”。
作者:Laurens Swinkels,PhD
今天公众号为大家分享一篇Rebeco的最新文章。关于大数据和机器学习的重大发展正在推动量化投资的前沿。计算能力的增强促进了
机器学习模型的部署和使用。与基于规则的模型相比,这些模型采用完全数据驱动的方法,能够对复杂的非线性关系建模。可以潜在地揭示简单线性模型无法捕捉到的系统性和重复模式。
例如,某些变量可能只有当它们超过某个阈值时,或者当它们与其他变量结合时,或者它们可能只能预测表现不好的股票时,才能预测股票收益。在这篇白皮书中,我们深入探讨了如何使用ML技术可以推动量化建模到下一个水平。我们也看一个具体的例子,用机器学习模型来预测个别股票价格崩溃。
机器学习技术在量化投资中的不同使用正日益被学术文献所承认。这些模型包括相对简单的变量选择模型,以及能够识别不同资产回报率之间的超前滞后关系的模型。机器学习技术也被用于统计套利的复杂深度学习模型。过拟合一直是量化策略的一个关键问题。当数据量和变量的数量增加时,这是一个更大的问题。
这里的风险在于,人们可以发现过去观察到的变量之间的巧合关系,并将其用作构建投资组合的信号,而实际上,这种关系在未来不会重复,因为没有真正的潜在现象。然而,机器学习工具箱包含避免过拟合的解决方案,如正则化(即变量选择),模型平均和交叉验证。
避免投资那些随后会遭遇财务困境的公司,可以帮助投资者跑赢大盘。也就是说,要发现那些未来最有可能面临困境的公司远非易事。虽然有许多特征可以帮助预测这种结果,但它们可能以一种非线性的方式或特定的组合方式最有效地做到这一点。幸运的是,ML技术被设计用来应对这种挑战。
标记陷入困境的公司的一种方法是查看破产申请或信用评级下调。然而,这些事件发生之前可能会有股价下跌。对于股票投资者来说,预测股价下跌比正确预测破产申请或信用评级下调更有意义,因为这些事件在发生时可能已经被消化了。因此,我们将崩盘事件定义为一家公司的股价相对于其他股票的大幅下跌。该指标捕捉的是特殊风险,而不是整个市场的动荡,我们认为它很适合用于选股模型,而不使用于资产配置或因子择时模型。
根据我们对财务困境的定义,图1显示,确定的困境事件并不集中在少数几个行业,而是跨越多个行业。也就是说,越是陷入困境的行业,通常发生的事件就越多。总的来说,股价崩溃的次数随着时间的推移而变化,因为横截面波动通常在危机时期更高。
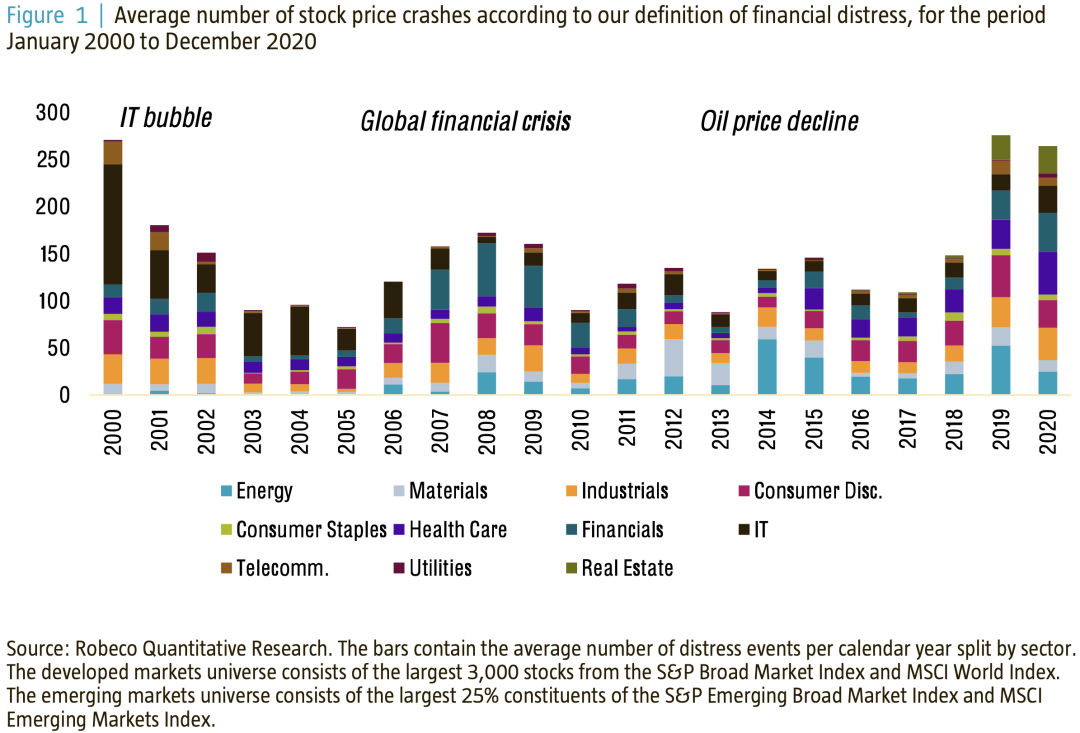
如果我们想通过使用ML模型来识别将面临财务困境的公司,我们需要向它提供一组可能包含股票价格崩溃的预测信息的变量。在ML术语中,这些预测变量被称为特征,而被预测的变量被称为目标。
选择作为算法输入的特征集,目的是找到与目标的预测关系,这是任何预测模型的重要建模步骤。出于我们的目的,我们选择的变量包括经典的金融危机指标,如distance-to-default, volatility, 和return on equity。但是,由于ML模型旨在从更大的变量集中挑选最重要的特征,我们还决定从财务报表中获取更细粒度的特征,如经营的现金流以及短期和长期债务。
在我们的模型中,我们只纳入了我们认为可能与识别具有股价崩盘风险的公司相关的特征。例如,公司名称的首字母或标志的颜色等特征就不包括在内,因为我们无法将它们与经济原理联系起来,从而解释为什么它们可能能够预测崩溃风险。由于许多公司特征只是某个时间点的快照,例如盈利能力,我们还在模型中包含了一些特征的时间序列。在我们看来,这允许算法识别一系列事件,如盈利能力下降,如何影响窘迫风险。
大多数ML算法设计用于从大量特征中过滤出相互之间不相关的预测因子,这个过程在避免过拟合方面也很有用。我们相信,更少的冗余特征降低了基于噪声数据做出投资决策的机会。此外,减少特征的数量可以加快算法的训练过程。对于我们的应用,我们训练了三个统计模型:正则化逻辑回归、随机森林和梯度增强树。
正则化逻辑回归是一种基于经典线性回归模型的方法,但通过逻辑转换(在线性尺度上的测量被转换为概率),用于预测二元结果的概率:在我们的例子中,是一家公司是否陷入财务困境。正则化是ML中模型选择的术语,也就是说,该技术只选择那些有助于预测二元结果的变量。
与此同时,随机森林分类是一个基于多决策树(因此有了森林这个术语)的非线性模型,以随机选择的特征作为节点,其中大多数投票决定分类(确定一个观测属于哪一组),在我们的应用程序中是一个二叉决策。最后,梯度增强树算法也是基于决策树,但它不依赖于多数投票,而是改变特征的权重,以减少错误预测的数量。
这三个预测模型每年都根据它们的交叉验证指标重新训练。在对模型进行再训练之后,我们根据之前未见过的数据构建来年的信号。在设置这个训练测试配置时,确保没有数据泄漏是极其重要的。这是指在模型训练过程中,当之前未见的数据泄露时,会发生过拟合。数据泄露会导致更好的回溯测试结果,而这在实践中是无法实现的,因为将来可以访问的信息显然是不可获得的。
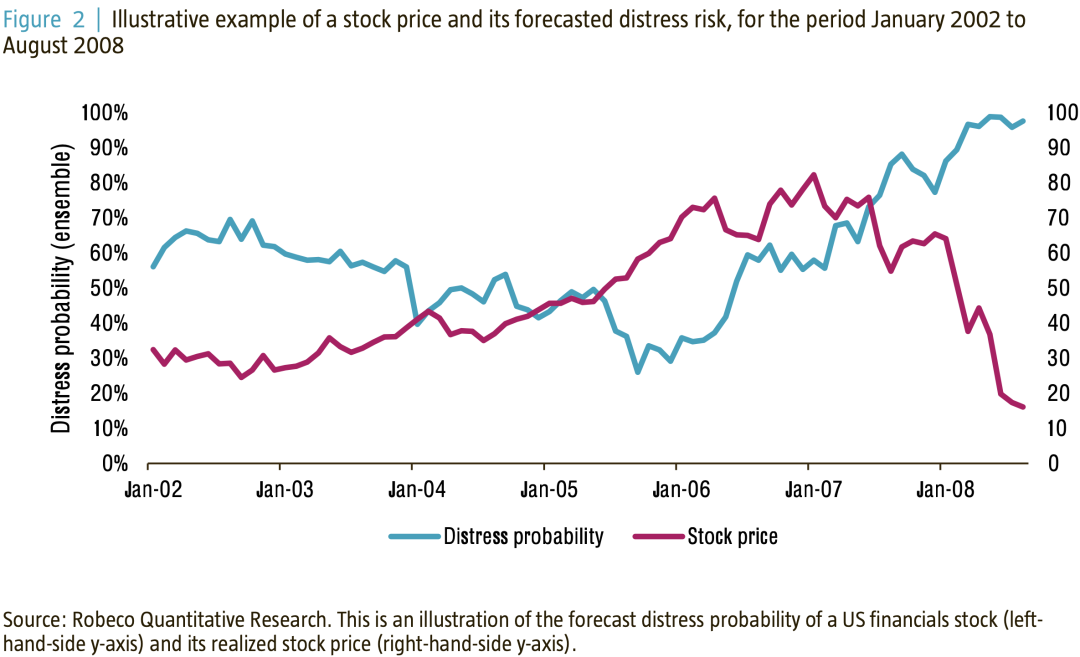
每一个模型都做出独立的预测,然后这些预测被组合成一个集合预测。在我们看来,集合是ML唯一的免费午餐,这与投资上的多样化类似。图2显示了美国金融股的股价,以及随着时间的推移预测的整体困境风险。在这个例子中,我们看到2007年中期之后,它发生危机的概率超过了75%,并在随后的几个月里超过了90%。我们还观察到,该公司的股价在2007年1月达到峰值,但从2008年3月开始急剧下跌,直到2008年9月该公司申请破产。
我们应用这种方法生成了2000年至2020年期间发达市场和新兴市场股票的单独样本的财务困境概率。为了进行比较,我们还考虑了其他困境风险的预测因素,如股票回报波动率、股票市场beta和违约距离。对于每个子样本,我们根据这些股价崩盘概率的排序形成20个投资组合,并计算它们在接下来的时间段内的收益。
图3描述了市场的表现,以及四种困境风险度量中财务困境概率最高的投资组合。就发达市场而言,这段时间的平均市场回报率为10.0%。与此同时,基于ML方法策略的底部投资组合收益率仅为2.3%。这远远低于基于其他传统变量(从4.2%到5.0%)的最高困境预测构建的投资组合所取得的收益。
就新兴市场而言,我们看到了更大的改善。市场平均回报率为11.6%,而基于其他传统危机预测指标的投资组合的回报率在4.5%至7.0%之间。另一方面,基于ML方法的投资组合产生了1.5%的损失,因此产生了比其他三种方案更好的结果。

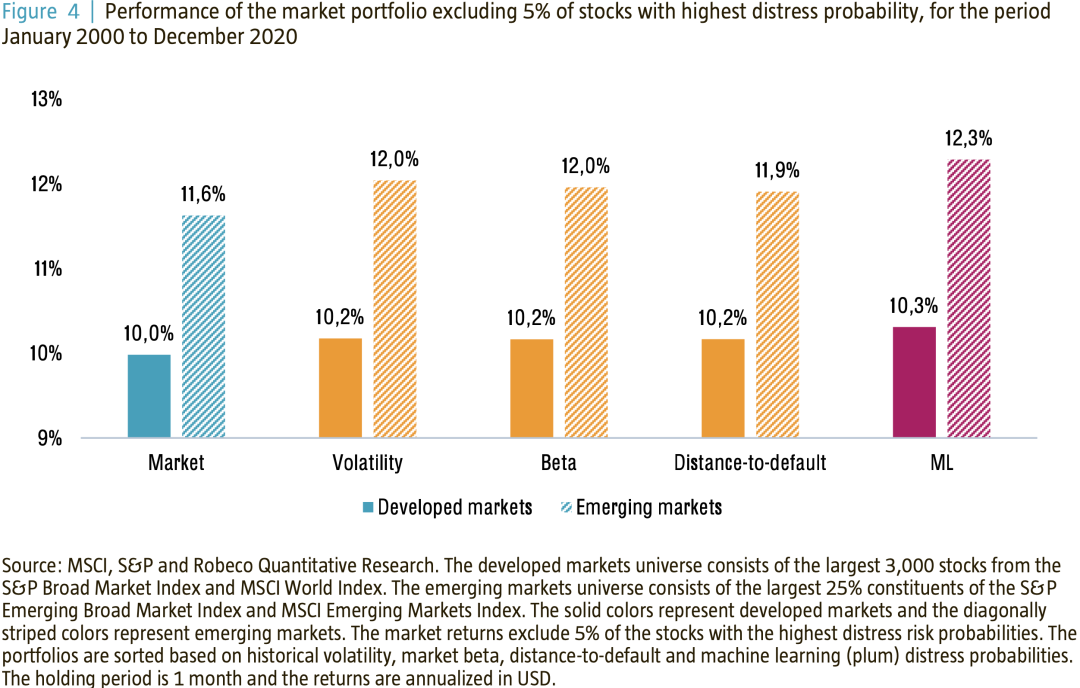
这表明,先进的ML技术可以潜在地帮助我们识别具有较高困境风险的股票。换句话说,如果我们避免投资这些股票,我们就有可能提高量化股票投资组合的回报。
为了更好地理解ML是如何帮助预测财务困境的,我们首先考察了5%风险最高的股票的行业分类。虽然我们希望ML方法能够自动识别出可能遭遇困境的行业,但我们不希望它被行业选择所主导。对于我们的ML模型,我们没有对其进行这样的限制,因为我们没有在其特征集中包含扇区信息。
图5显示了该股票子集随时间的行业分布。我们观察到,大多数财务困境股票出现在21世纪初的信息技术板块,然后是2008年至2010年期间的金融板块,其次是2015年至2019年期间的能源板块。虽然随着时间的推移,有明显的倾向于这些陷入困境的行业,但我们注意到,已确定的困境事件并不仅仅集中在少数几个行业。因此,我们相信这使我们的ML技术成为股票选择过程中使用的一个很好的候选者。

评估每一个所选特征的重要性也是至关重要。SHAP值是预测目标时特征的边际贡献的平均值。这种方法使我们能够理解我们预测背后的经济原理。
在图6的这个例子中,我们的预测模型只包括三个特征:波动性、市盈率(PE)和股票周转率。在不考虑任何特征的情况下,我们假设该模型将预测训练样本的平均遇险概率为10%。然后,如果只考虑波动性、本益比或股票换手率信息,我们将看到一只股票的困境概率分别上升到15%、12%或11%。此外,我们展示了当同时包含两个变量时,以考虑了所有三个特征时,预测概率的变化。
每个特征的平均边际贡献,或SHAP值,在右边计算。在这个例子中,股票波动率的贡献最大,为4.5%。这包括添加到基线时5%的平均增幅,作为下一行9的第二个特征添加时4.5%的平均增幅,以及作为底部第3个变量添加时4%的增幅。同样,本益比的SHAP值为1.5%,而周转率的边际贡献最小,SHAP值为1.0%。总的来说,SHAP值加起来为7%,构成了模型预测值17%与基线值10%之间的差异。通过这种方法,我们可以解构每个特征对每个观测的重要性。

我们的ML模型中特征的重要性如图7所示。每个点的颜色表示特征的大小,其中红色表示高特征值,蓝色表示低特征值。这些特征按重要性从上到下排序。例如,特征25是最重要的,这表明它在SHAP值中有最大的差异。
如红点所示,特征25的高值会导致财务困境概率的大幅增加,因为这些点比任何其他特征都更靠右。另一方面,较低的数值,如蓝点所强调的,意味着财务困难的概率降低,因为蓝点位于量表的负侧。相比之下,特征4的最小值位于最左侧,因此这些值可能比特征25的最小值对遇险概率产生更大的负面影响。特征5的影响是非线性的,因为高值对概率有很大的正影响,而低值只有很小的负影响。

为了更好地理解特征和财务困境概率之间的非线性和相互作用效应,我们查看了图8中的部分依赖图。这些图显示了单个特征对预测遇险概率的边际影响。
图8中左侧的图表显示,较低的Distance-to-default会增加遇险概率。但整体的形状是凸向原点的Distance-to-default的降低对SHAP的边际贡献越大。这是一个清楚的例子,解释了为什么非线性模型是有用的,因为整个范围的横截面值是不相等的信息。
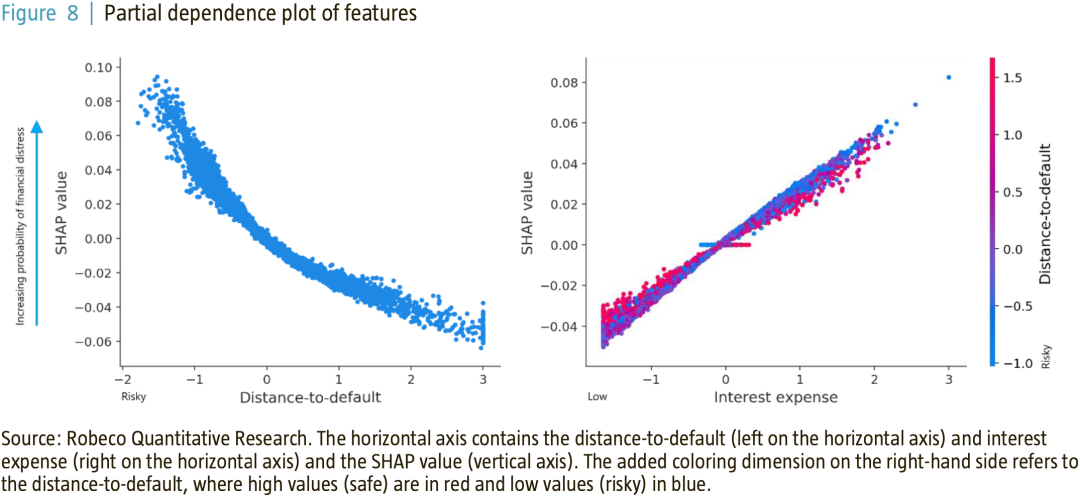
到目前为止,我们已经展示了特征和财务困境概率之间的(可能是非线性的)关系,这有助于我们理解基于输入的预测模型的行为。然而,也有可能深入到一个似乎是黑匣子的地方来解释个别的灾难预测。深入挖掘原始数据使我们能够清楚地了解为什么某只股票被认定为或不被认定为低价股票。
对于每一次观测,我们都能精确地显示出哪些特征提高了遇险概率,哪些特征降低了遇险概率。图9中描述了我们投资领域中某只股票的情况。
对于每一个相关特征,我们说明输入值及其对估计遇险概率的影响。红色条形图包含了提高遇险概率的特征值,而蓝色条形图包含了降低遇险概率的特征值。通过使用这些可视化,我们可以确保我们的ML应用程序是一个玻璃箱而不是一个黑箱,并且我们可以深入到源数据,以更好地理解我们的股票池中每只股票的破产概率。

我们已经正式运行了几个ML模型。例如,我们使用自然语言处理技术来解读大量新闻,以检测情绪,或分析公司披露的信息,以确定公司可能对联合国可持续发展目标做出的贡献。这是对本文中描述的用于预测股价崩盘风险的ML技术的补充。我们相信这些工具可以帮助我们更好地识别未来可能表现不佳的公司。避免投资这类股票可能会提高投资业绩。
在我们看来,新的量化研究技术——如ML——挑战了量化投资领域的传统智慧,并有可能改善投资结果。在本文中,我们阐述了ML如何在发达市场和新兴市场的困境事件(例如破产申请或信用评级下调)发生之前帮助投资者发现困境企业。我们已经评估了ML模型的附加价值,因为它们可以考虑非线性和相互作用等复杂性,特别是与更简单的传统线性模型相比。
ML算法的一个关键优势是,我们可以向它们提供经济合理且表现良好的输入参数,并详细分析它们的选择是否随时间推移而合乎逻辑。由于我们仍然认识到过拟合的风险,我们使用了交叉验证框架,我们相信,随着时间的推移,可以在可预测性方面产生谨慎的数据驱动的变化。此外,我们有能力仔细检查源数据,这使我们能够解释为什么我们的投资组合中某只股票具有特定的困境风险概率。简而言之,我们基于ml的遇险风险预测应用与Robeco的量化投资理念是一致的。
未来的创新研究项目将揭示复杂的预测关系或导致更好地解释非结构化数据的可能性很高。金融市场数据的缺点是,股票价格可能会受到许多已知和未知因素的影响,而随着时间的推移,企业特征之间的关系是复杂和不稳定的。这使得预测股票收益变得困难。
因此,标准的统计方法可能无法发现复杂的模式,或者数据中的复杂模式可能是随机的,因此将来可能不会重复。我们在危机预测中的ML应用表明,ML工具箱可能包含揭示未来财务危机真实信号的方法,同时忽略了资产价格和公司特征中存在的噪声数据。
当从基于规则的模型转移到基于ml的模型时,研究人员的角色就从指导者转变为协调者。在传统的方法中,研究人员指示计算机测试输入数据的特定规则,看看它们是否有助于预测输出。在ML方面,研究人员将输入和输出数据都输入计算机,让它评估最佳规则是什么。这在ML术语中称为监督学习。
这种角色的变化使研究人员能够处理更复杂的问题。但人们需要谨慎,并注意模型的可解释性和过拟合。只有这样,定量研究人员才能坐在驾驶员的位置上,编排ML过程,而不是指导算法如何行为。因此,我们相信ML技术可以推动量化建模在我们已被证实的投资理念的范围内达到一个新的水平。事实上,循证研究、经济理性和审慎投资是ML在投资环境中发挥作用的关键因素。








