作者:python与数据分析
链接:https://www.jianshu.com/p/22cb6a4af6d4
Python 读取数据自动写入 MySQL 数据库,这个需求在工作中是非常普遍的,主要涉及到 python 操作数据库,读写更新等,数据库可能是 mongodb、 es,他们的处理思路都是相似的,只需要将操作数据库的语法更换即可。本篇文章会给大家系统的分享千万级数据如何写入到 mysql,分为两个场景,三种方式。
一、场景一:数据不需要频繁的写入mysql
使用 navicat 工具的导入向导功能。支持多种文件格式,可以根据文件的字段自动建表,也可以在已有表中插入数据,非常快捷方便。
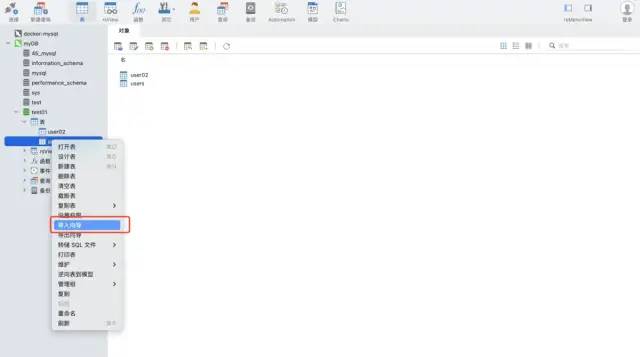
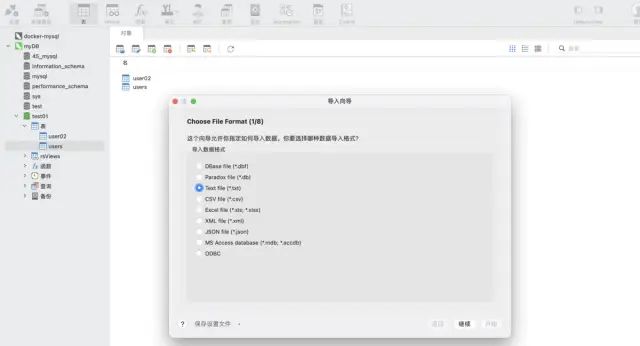
场景二:数据是增量的,需要自动化并频繁写入mysql
测试数据:csv 格式 ,大约 1200万行
import pandas as pd
data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
data.shape
 打印结果
打印结果
方式一:
python ➕ pymysql 库
安装 pymysql 命令
pip install pymysql
代码实现
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv'
,chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')
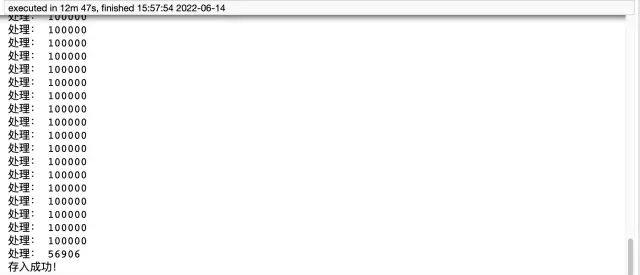
方式二:
代码实现
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01')
data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
data.to_sql('user02',engine,chunksize=100000,index=None)
print('存入成功!')

总结
pymysql 方法用时12分47秒,耗时还是比较长的,代码量大,而 pandas 仅需五行代码就实现了这个需求,只用了4分钟左右。
最后补充下,方式一需要提前建表,方式二则不需要。
所以推荐大家使用第二种方式,既方便又效率高。如果还觉得速度慢的小伙伴,可以考虑加入多进程、多线程。
最全的三种将数据存入到 MySQL 数据库方法:
直接存,利用 navicat 的导入向导功能
Python pymysql
Pandas sqlalchemy
- 机器学习交流qq群955171419,加入微信群请扫码










