交叉验证
对于模型的准确度,一般可以将预测结果和实际结果比对,从而轻松地得出。而模型地泛化误差(是不是过拟合)则相对较难度量。交叉验证是一种评估模型泛化误差地常见手段。
具体步骤
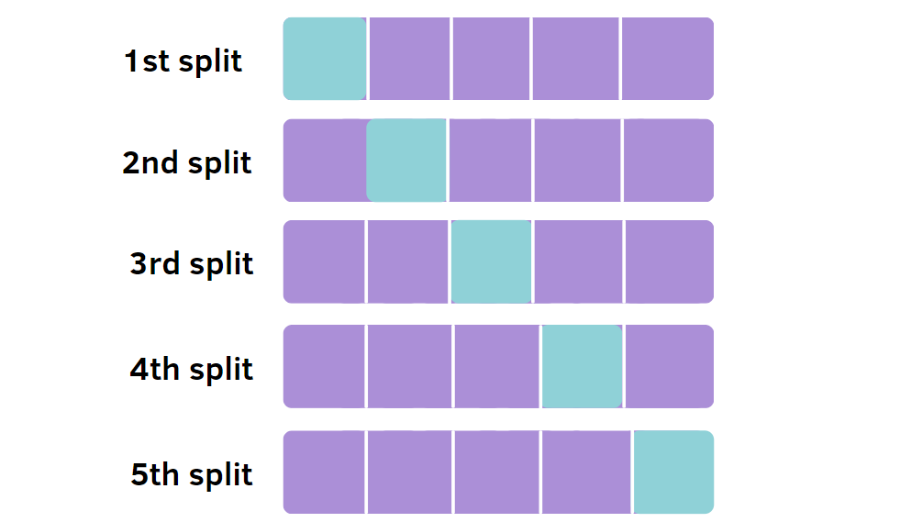
交叉验证法先将数据划分为k个大小相似的互斥子集。然后,每次选取k-1个子集进行训练,剩余的一个作为测试集。从而进行k次训练和测试,最终返回k次测试结果的均值。交叉验证的稳定性和保真性很大程度上取决于k的取值,k最常用的取值为10,这种交叉验证法又称“k折交叉验证”。
留一法
留一法是交叉验证的一种特殊情况,它将m个样本划分为m个子集,每次只取一个样本做测试集,其余全部为训练集。由于留一法每次只取出一个样本,每个训练模型都和需要评估的模型非常接近,因此被认为比较准确。但是在数据过多的情况下不建议使用。
cross_value_score
参数:(算法,数据集, 结果, cv, scoring)
cv取整数k时,按k折交叉验证方法分为k份
scoring:特殊的计算分数方法,默认none
precision: 查准率
recall: 查全率
f1: 查准率和查全率均值
#导入数据集
from sklearn import datasets
iris = datasets.load_iris()
# 应用svm算法
from sklearn import svm
clf = svm.SVC(kernel='linear', C=1)
#交叉验证评估
from sklearn.model_selection import cross_val_score
# 进行5折交叉验证
scores = cross_val_score(clf, iris.data, iris.target, cv=5)
scores
输出
array([0.96666667, 1. , 0.96666667, 0.96666667, 1. ])
k折交叉验证
from sklearn.model_selection import KFold
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
# 使用这里的n_splits设置k值
kf = KFold(n_splits=2)
# 得到训练集特征X[train_index](二维集合),结果y[train_index](集合)
# 得到测试集特征X[test_index](二维集合),结果y[test_index](集合)
for train_index, test_index in kf.split(X):
print("train_index", train_index, "test_index",test_index)
train_X, train_y = X[train_index], y[train_index]
test_X, test_y = X[test_index], y[test_index]
输出
train_index [2 3] test_index [0 1]
train_index [0 1] test_index [2 3]
p次k折交叉验证
from sklearn.model_selection import RepeatedKFold
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
# 使用这里的n_splits设置k值,n_repeats设置重复次数
kf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=0)
for train_index, test_index in kf.split(X):
print('train_index', train_index, 'test_index', test_index)
输出
train_index [0 1] test_index [2 3]
train_index [2 3] test_index [0 1]
train_index [1 3] test_index [0 2]
train_index [0 2] test_index [1 3]
留一法
from sklearn.model_selection import LeaveOneOut
X = [1, 2, 3, 4]
loo = LeaveOneOut()
for train_index, test_index in loo.split(X):
print('train_index', train_index, 'test_index', test_index)
输出
train_index [1 2 3] test_index [0]
train_index [0 2 3] test_index [1]
train_index [0 1 3] test_index [2]
train_index [0 1 2] test_index [3]
注:用LeavePOut(p=n) 代替LeaveOneOut() 可以留p个值
- 机器学习交流qq群955171419,加入微信群请扫码(读博请说明)










