
凡是搞计量经济的,都关注这个号了
稿件:econometrics666@126.com
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软
件都放在社群里.欢迎到计量经济圈社群交流访问.
Marcos López de Prado, Machine Learning for Econometricians: The Readme Manual, The Journal of Financial Data Science Summer 2022, jfds.2022.1.101.
金融研究中最令人兴奋的最新发展之一,是几年前还不存在的新行政、私营部门和微观层面数据集变得越来越多。这些观察数据的非结构化性质,以及它们所测量的现象的复杂性,意味着其中许多的数据集超出了计量经济学分析的掌握范畴。机器学习 (ML) 技术提供了在高维空间中识别复杂模式所需的超强数值计算能力和灵活性的功能。然而,与计量经济学方法的透明度相比,ML通常被视为一个黑匣子。在本文作者证明了,就计量经济学过程的每个分析步骤而言,在ML分析中都会有一个同源步骤与其相对应。通过清楚地说明这种对应关系,作者的目标是促进和协调计量经济学家对机器学习方法的采用。1.简要介绍
在一般意义上,计量经济学包含一套应用于经济和金融数据的统计方法,目的是为经济理论提供实证支持。然而,在实践中,这组统计方法传统上多集中应用于多元线性回归模型中。过去 100 年来,多元线性回归模型流行的原因有如下几个:经济数据集大多是数值型的、长度短、数量少、信噪比低。考虑到数据的限制,因此,使用相对受限的模型也就是相对合理的。近年来,经济数据的数量和粒度(详细和清晰程度)有了显著提高。好消息是,行政、私营部门和微观层面数据集的突然爆发性增长,为经济的内部运作提供了无与伦比的洞察机会。坏消息是,这些数据集对计量经济学工具包提出了多重挑战。仅举几例:(a)一些最有趣的数据集是非结构化的。它们也可以是非数字和非分类的,如新闻文章、录音或卫星图像;(b) 这些数据集是高维的(例如信用卡交易)。所涉及的变量数量往往大大超过观测数量,因此很难应用线性代数的解决方案;(c) 其中许多数据集非常稀疏。例如,样本可能包含很大比例的零,而相关性等基本的关联概念无法很好地发挥作用;(d) 嵌入在这些数据集中的是关于代理网络、动机和群体的聚集行为的关键信息。由于这些挑战和这些新数据集的复杂性,经济学家可以从回归模型和其他线性代数或几何方法中学到的东西有限,原因有二:(a)即使使用较旧的数据集,传统的技术也可能太过简陋,无法为变量之间复杂的关联(例如,非线性和交互)建模;(b) 对于传统技术而言,流动性证券的效率可能过高,因为对于计量经济学模型而言,任何未被利用的低效率都过于复杂。根据第二种观点,无论通过对流动证券的回归方法确定何种关系,从结构上看都必然是虚假的。机器学习 (ML) 提供了一套现代统计工具,特别适合克服新的经济和金融数据源以及金融市场中日益复杂的关联所带来的挑战。尽管如此,在金融学术研究中使用机器学习仍然是例外而不是既成规则。部分原因可能是错误地认为机器学习是一个黑匣子,这与标准计量经济分析的透明度形成鲜明对比。本文的目的是揭露该种错误的看法。作者认为,计量经济学过程的每个分析步骤在 ML 分析中都有对应的同源物。通过明确说明这种对应关系,希望鼓励应用经济学和金融研究人员采用 ML 技术。要传达的信息是,金融数据集越来越超出计量经济学的范畴,而ML是一种透明的研究工具,在金融研究中发挥着重要作用。由于上述所有原因,金融专业人士和学者应该熟悉这些技术,经济学学生应该参加数据科学课程(除了他们的强制性计量经济学培训外)。本文的其余部分如下:第 2 节提供了计量经济学和机器学习起源的历史背景。第 3 节描述了跨科学领域的 ML 的不同用例。第 4 节提供了计量经济学和机器学习研究过程中步骤之间的对应关系。第 5 节总结了结论。2.计量经济学经典
用 William Greene(他写的计量经济学就像一本大字典)的话来说,“多元回归的概念,尤其是线性回归模型构成了大多数计量经济学建模的基础平台,即使线性模型本身最终并未用作经验规范”。多元线性回归建模不是现代技术。它的历史至少可以追溯到 1795 年,当时高斯将普通最小二乘法 (OLS) 应用于测地线和天文数据集。有趣的是,高斯认为 OLS 是如此明显以至于不值得被发表出来。英国优生学家弗朗西斯·高尔顿爵士在 1886 年创造了“回归”一词,他通过估计线性方程来论证遗传的人类身体和道德特征表现出向平均值回归的特点。接近 20 世纪之交,卡尔·皮尔森参考高尔顿的论点创造了“回归线”一词,并引入了矩方法(80 年后由诺贝尔经济学奖得主Lars Hansen推广,所谓的GMM)。在接下来的几年里,Ronald Fisher 研究并证明了回归分析的数学性质,并推广了最大似然估计。这些想法催生了我们今天计量经济学研究的大部分内容。标准计量经济学教科书的内容最能体现其经典(推荐基本计量教材,例如,Tsay [2013]、Greene [2012]、Wooldridge [2010]、Hayashi [2000])。
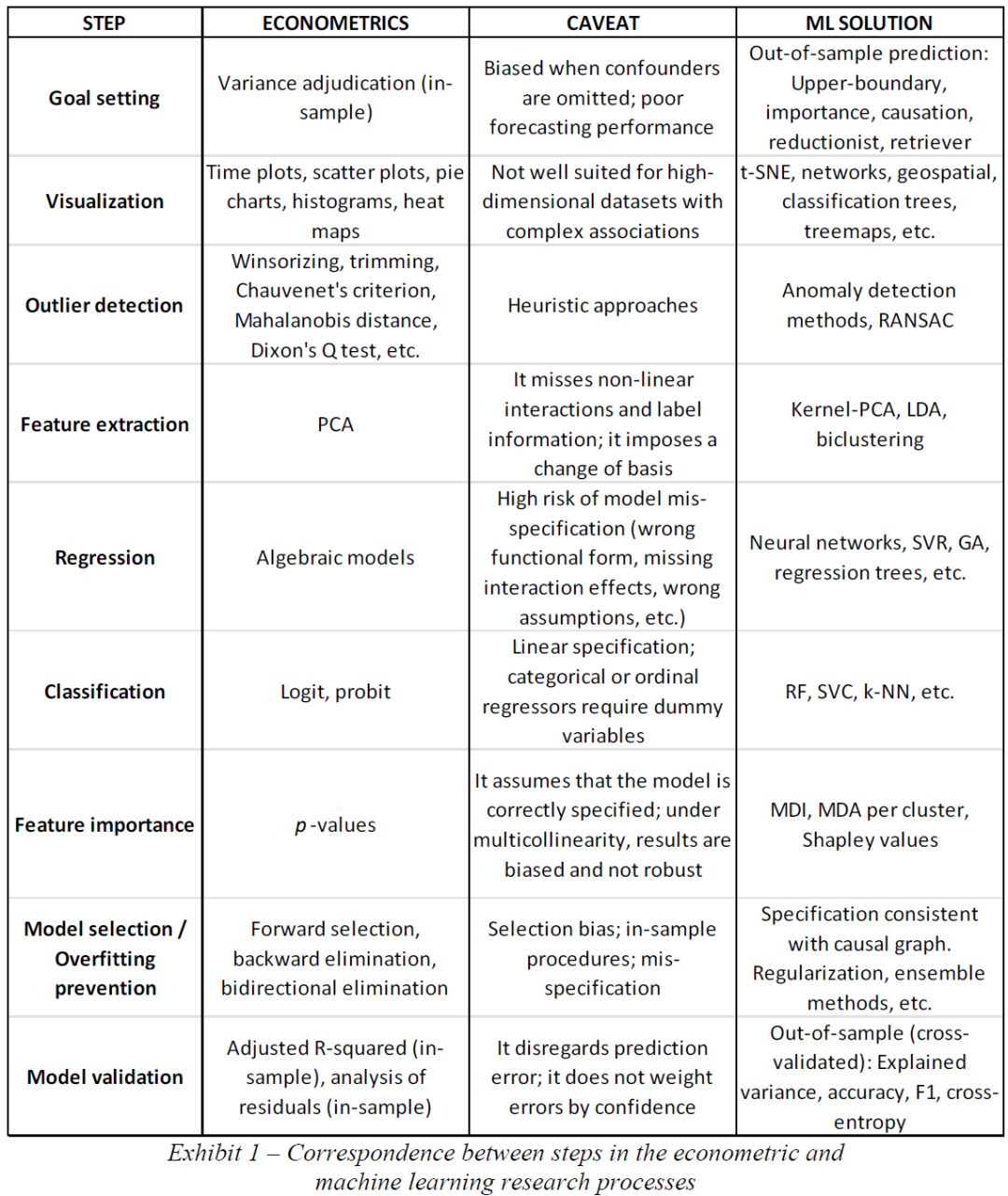
经济学家使用的同样的定量标准应用于生物数据集时被称为生物统计学,应用于化学数据集时被称为化学计量学。然而,即使是入门级的生物统计学和化学计量学教科书也经常包含高级聚类、模式识别或计算方法,而这些方法在流行的计量经济学教科书中基本上没有或很少强调(不信,你可以看看 Greene [2012] 、 Otto [2016] 和 Balding [2007]的书籍)。计算方法在这些学科中变得尤为重要,因为它们可以取代一些(可能是不切实际的)关于数据生成过程的假设。许多先锋经济学家对经济学家未充分利用数据驱动和数值方法以及过度使用基于任意假设的结构模型表示失望。例如,诺贝尔奖获得者 Wassily Leontief 大约在 40 年前就表达了这种担忧(Leontief [1982]):“经济学家们从一开始就没有接受自然科学和历史科学的同行们传统上强加给他们的、并接受的那种系统的事实调查的严酷纪律,因此他们对演绎推理产生了一种几乎不可抗拒的偏好。事实上,许多人在专攻纯数学或应用数学后进入该领域。一页又一页的专业经济期刊充满了数学公式,引导读者从几组或多或少似是而非但完全武断的假设转向精确陈述但不相关的理论结论。”对经济学文献的简单文献计量分析表明,Leontief 的哀叹在很大程度上仍然适用于今天。例如,Web of Science报告称,已经发表了 13,772 篇涉及“经济学”和“统计与概率”交叉学科的期刊文章。在这些出版物中,只有 89 篇文章 (0.65%) 包含以下任一术语:分类器、聚类、神经网络或机器学习。相比之下,在“生物学”和“统计与概率”交叉领域的 40,283 篇文章中,共有 4,049 篇(10.05%)包含这些术语中的任何一个。在“化学、分析”和“统计与概率”交叉领域的 4,994 篇文章中,共有 766 篇(15.34%)包含这些术语中的任何一个。这种差距的部分原因是旧经济数据集的缺陷,它可能限制了机器学习和其他数据密集型技术的使用。然而,面对新的非结构化、高维、稀疏、非数字经济数据集,这种差距应该在几年前缩小。制度阻力继续阻止学术经济学家采用 ML 技术,部分原因是同行评审和任期过程今天仍然有利于坚持计量经济学经典。这种对现代化的抵制反映在基金管理公司身上,因为这些公司(遗憾地)在几十年前就发现了期刊文章对投资基金营销的有效性。经济和金融数据的爆炸式增长应该鼓励从业者重新考虑拟合简单模型的适当性。新的可用数据集包括社交媒体、从网站上抓取的元数据、卫星图像、传感器数据、从文本中提取的情绪以及交易所生成的微观结构数据。SINTEF 估计,过去两年收集了所有可用数据的 90%。国际数据公司估计,所有可用数据中有 80% 是非结构化数据,因此他们不适用于传统的定量分析方法。几年前还没有这些详细的信息来源,它们最终为我们提供了发展基于丰富实证证据的经济理论的可能性。然而,这些也是 21 世纪的数据集,其结构无法用传统的计量经济学工具轻易揭示。下一节将回顾其他领域如何应用 ML。下面是“计量经济学和机器学习研究过程中步骤之间的对应关系”。
关于机器学习,参看1.机器学习之KNN分类算法介绍: Stata和R同步实现(附数据和代码),2.机器学习对经济学研究的影响研究进展综述,3.回顾与展望经济学研究中的机器学习,4.最新: 运用机器学习和合成控制法研究武汉封城对空气污染和健康的影响! 5.Top, 机器学习是一种应用的计量经济学方法, 不懂将来面临淘汰危险!6.
Top前沿: 农业和应用经济学中的机器学习, 其与计量经济学的比较, 不读不懂你就out了!7.前沿: 机器学习在金融和能源经济领域的应用分类总结,8.机器学习方法出现在AER, JPE, QJE等顶刊上了!9.机器学习第一书, 数据挖掘, 推理和预测,10.从线性回归到机器学习, 一张图帮你文献综述,11.11种与机器学习相关的多元变量分析方法汇总,12.机器学习和大数据计量经济学, 你必须阅读一下这篇,13.机器学习与Econometrics的书籍推荐, 值得拥有的经典,14.机器学习在微观计量的应用最新趋势: 大数据和因果推断,15.R语言函数最全总结, 机器学习从这里出发,16.机器学习在微观计量的应用最新趋势: 回归模型,17.机器学习对计量经济学的影响, AEA年会独家报道
,18.回归、分类与聚类:三大方向剖解机器学习算法的优缺点(附Python和R实现),19.关于机器学习的领悟与反思,20.机器学习,可异于数理统计,21.前沿: 比特币, 多少罪恶假汝之手? 机器学习测算加密货币资助的非法活动金额! 22.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 23.全面比较和概述运用机器学习模型进行时间序列预测的方法优劣!24.用合成控制法, 机器学习和面板数据模型开展政策评估的论文!25.更精确的因果效应识别: 基于机器学习的视角,26.一本最新因果推断书籍, 包括了机器学习因果推断方法, 学习主流和前沿方法,27.如何用机器学习在中国股市赚钱呢? 顶刊文章告诉你方法!28.机器学习和经济学, 技术革命正在改变经济社会和学术研究,29.
世界计量经济学院士新作“大数据和机器学习对计量建模与统计推断的挑战与机遇”,30.机器学习已经与政策评估方法, 例如事件研究法结合起来识别政策因果效应了!31.重磅! 汉森教授又修订了风靡世界的“计量经济学”教材, 为博士生们增加了DID, RDD, 机器学习等全新内容!32.几张有趣的图片, 各种类型的经济学, 机器学习, 科学论文像什么样子?33.机器学习已经用于微观数据调查和构建指标了, 比较前沿!34.两诺奖得主谈计量经济学发展进化, 机器学习的影响, 如何合作推动新想法!35.前沿, 双重机器学习方法DML用于因果推断, 实现它的code是什么?
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。











