
今天给大家带来的是美团在CIKM2022上中稿的论文,重点关注于CTR预估中的超长用户行为序列建模。与SIM、ETA这类基于“检索”的建模范式不同,论文提出了一种简单而且有效的基于“采样”的建模范式。基于采样多个hash function和SimHash,弥补了基于“检索”的建模范式中信息缺失以及效果和效率难以平衡的缺点,极大降低计算复杂度的同时实现了在超长行为序列下类似target-attention的建模效果,一起来看一下。
1、背景
在CTR预估中,通过用户历史行为来建模用户兴趣是十分重要的一环。DIN创新的提出了target attention模块,将用户历史行为中item和target item的相关性计算引入到建模当中,与target item更相关的item对用户是否点击的行为具有更大的影响。以DIN为基础,后续阿里又提出了DIEN、DSIN等方法,但出于线上计算耗时的考虑,这些方法大都只能处理用户较短长度的行为序列,如50个。
随着互联网的不断发展,电商场景下用户的行为序列长度远不止50。据统计,淘宝APP上,有超过23%的用户半年内有多于1000次的用户交互行为;美团APP上,超过60%的用户一年中有多余1000次的交互行为,其中更有10%的用户一年内有超过5000次的交互行为。因此,如何高效的处理用户长行为序列,以此来更准确的对用户兴趣进行建模,成为近年来研究的热门话题。
对于用户长行为序列建模,MIMN使用兴趣计算分离的方式,引入记忆网络对长序列行为进行信息提取和存储,这种方式理论上可以处理任意长度的用户行为序列,但是缺点在于兴趣计算分离的方式无法建模用户历史序列和target间的交互关系,效果可能有损;SIM和UBR4CTR提出了两阶段的方法,在第一阶段中通过一定的方式从长行为序列中检索top-K个与target-item最相关的历史行为,第二阶段可以使用DIN等CTR预估的方法。两阶段的做法解决了MIMN中行为序列与target item无法交互建模的缺点,但仍是一种非端到端的建模方式,检索阶段的目标和CTR预估的目标存在不一致性。为了解决两阶段建模目标不一致的问题,阿里进一步提出了ETA这种端到端的建模方法,第一次引入SimHash的方法,通过计算target item和历史序列中item的汉明距离筛选top-k个相关item。但ETA仍然是一种基于“检索”的方法,存在两方面的局限性:
1)从用户的所有历史行为中检索top-K个item,对用户的兴趣建模是有偏的,博客(https://zhuanlan.zhihu.com/p/525604184)给出了一个比较恰当的例子帮助大家理解,比如用户历史点了50次麦当劳和100次肯德基,此时用户应该更偏好于肯德基,但截断 top-50 后对模型来说二者是平等的。
2)检索算法的效果和性能很难权衡。如简单的检索算法线上性能可以得到保证,但可能会损失更多效果;而复杂的检索算法(如UBR4CTR)虽然可以一定程度上提升CTR预估的精度,但对线上耗时并不友好。
为了解决上述的挑战,论文提出了基于“采样”的超长行为序列建模方法SDIM (Sampling-based Deep Interest Modeling),通过采样多个hash function以及引入SimHash,弥补了基于“检索”的建模范式中信息缺失以及效果和效率难以平衡的缺点,极大降低计算复杂度的同时实现了在超长行为序列下类似target-attention的建模效果,下一章,咱们对SDIM进行详细介绍。
2、SDIM介绍
SDIM的整体框架如下图所示:
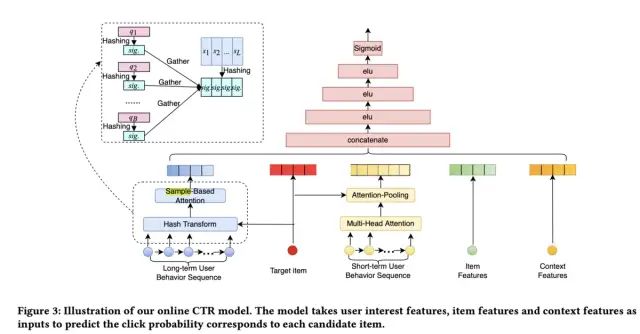
整个架构和SIM、ETA等结构大致相同,其主要的创新点在于长序列处理部分,接下来,会主要对这部分进行介绍,同时会对该部分的有效性以及时间复杂度进行分析,最后还会介绍如何将SDIM部署在实际的工业场景中。
2.1 Hash-Based Sampling
这一部分的本质还是在计算历史行为序列中每个item与target item的相关性得分,与ETA相同,论文引入了SimHash方法快速计算相关性。SimHash是Locality-sensitive hash中的一种高效的方法,关于SimHash,感兴趣的同学可以阅读博客(https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/06.03.html)。
对于SimHash,首先通过一个hash function和sign操作将item的Embedding转换为-1或1的hash code,如果对于两个item,其hash code相同,则可以认为二者有更大的概率是更相关的。
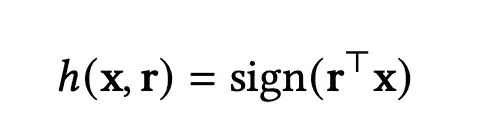
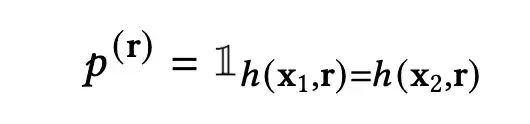
上式中,r代表对应的hash function,h代表得到的hash code,若两个向量在r的作用下得到的hash code相同,则p(r)为1,否则为0。
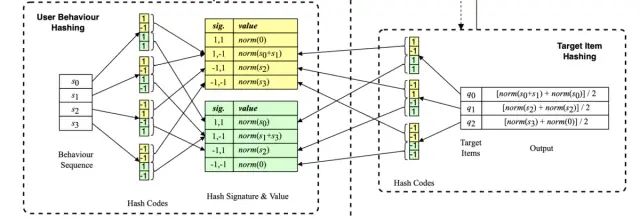
如果只使用一个hash function会带来较大的误差,因此论文引入了(𝑚,𝜏)-parameterized SimHash (multi- round hash) 方法,其中m代表使用的hash function的数量,同一个embedding使用m个hash function之后会得到m个hash codes,𝜏代表多少每𝜏个hash code组成一个hash signature,如m=4,𝜏=2代表使用4个hash function,同时每2个组成一个hash signature,一共可以组成两个hash signature。
对于target item的每一个hash signature,都可以从历史行为序列中找到与之相同的item,这些item对应的embedding通过sum-pooling以及L2-正则化,得到对应的向量表示。最后所有hash signature得到的向量进行avg-pooling,得到用户长期兴趣的向量表示。图示过程和数学表示如下:
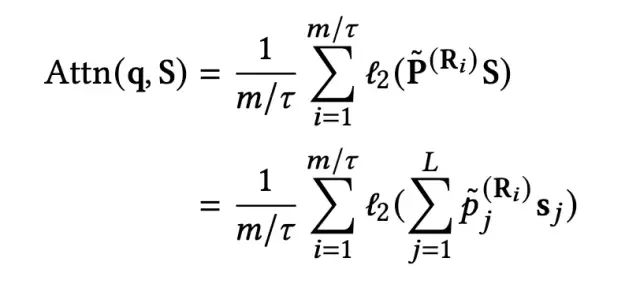
2.2 有效性分析
这一节,咱们来简单分析一下上述过程是如何近似于target attention的。对于两个标准化向量q和
sj来说,使用任意的hash function,其hash signature相同的概率期望如下:
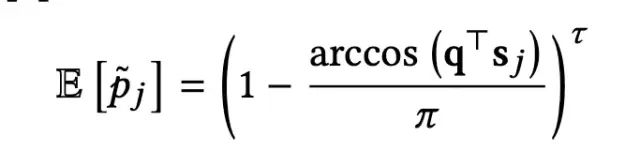
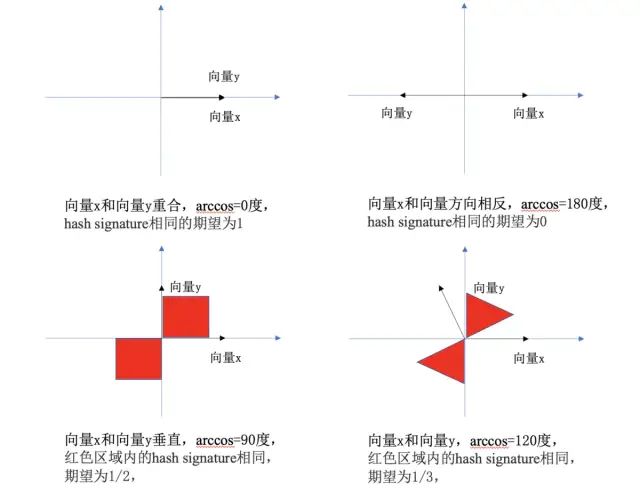
下图给出了𝜏=1的情况下几个二维平面上的例子来帮助大家形象的理解:
这样,SDIM得到的用户长期兴趣表示的期望如下:
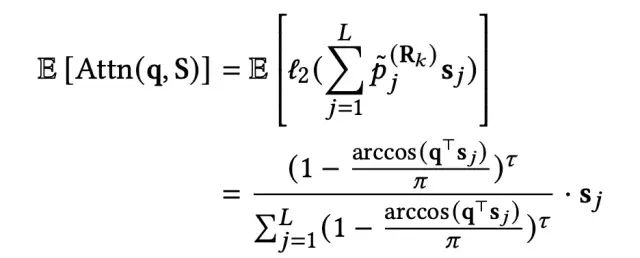
随着hash signature数量的不断增加,Attn(q,S)的结果会越接近于期望值E[Attn(q,S)],实验表明当数量大于16时,二者的误差就会非常小。因此实际部署中,选择m=48,𝜏=3,这样就会有16个hash signature。
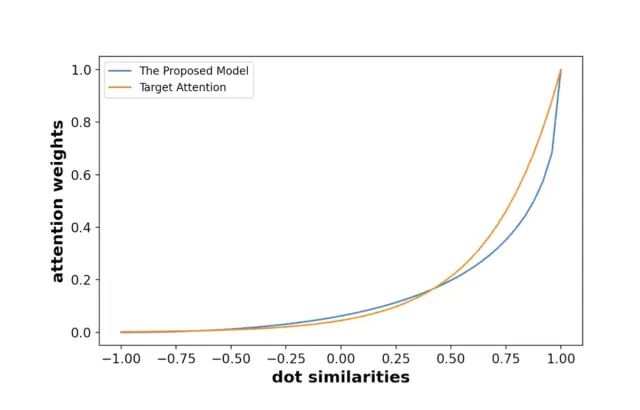
当m=48,𝜏=3时,可以从下图看出,SDIM得到的attention score与target attention得到的score是十分接近的,使用SimHash这种更快速的方式实现了类似于target-attention的效果。
2.3 线上部署介绍
这一部分咱们来介绍下SDIM的线上部署,如下图所示:
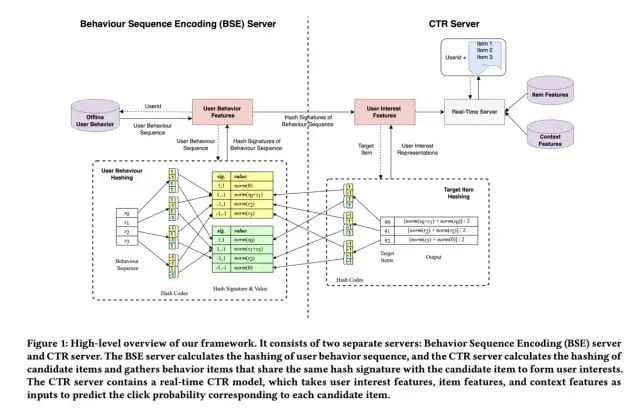
整个架构被分为两部分,Behavior Sequence Encoding (BSE) server和CTR Server。其中,BSE负责获取用户的长历史行为序列,采样多个hash functions同时计算得到对应的哈希值(论文中的意思应该是每次计算时的hash functions都是随机采样的,而非固定的)。由于BSE部分只需要拿到用户信息即可进行计算,同时对于所有的target item来说都是相同的,因此其可以与召回阶段进行并行计算,如果该部分的计算复杂度低于召回阶段,那么带来的额外开销基本为0,对于CTR服务的性能影响基本为0。这样的拆分部署的方式与MIMN类似,但与MIMN不同的是,SDIM的兴趣建模是可以考虑到target item的,因此可以有效的保证CTR预估的效果。
2.4 时间复杂度分析
最后咱们来看一下SDIM的时间复杂度信息,时间复杂度咱们这里拆分为离线训练阶段的复杂度和线上预估时的时间复杂度,结果如下:

其中,B代表target item的数量,L代表用户历史行为序列的长度,d代表item embedding的长度,k代表“检索”方法中得到的top-K的item的个数,m代表hash function的个数。这里咱们主要分析一下SDIM的时间复杂度,其他的算法感兴趣的同学可以自己计算验证一下。
首先从离线训练来看,对同一个用户来说,其历史行为都是相同的,因此对历史行为序列中item的hash只需要计算一次,时间复杂度为O(Lmd),另外,参考论文《Practical and Optimal LSH for Angular Distance》中的LSH方法,时间复杂度可以进一步降低为O(Lmlog(d));同样,对target item的hash的时间复杂度为O(Bmlog(d)。
对于线上耗时,咱们刚才也介绍过了,由于BSE和召回阶段并行,因此带来的额外开销可以认为是0,只需要对target item计算其对应的hash即可,因此线上预估的时间复杂度为O(Bmlog(d)。
3、实验结果
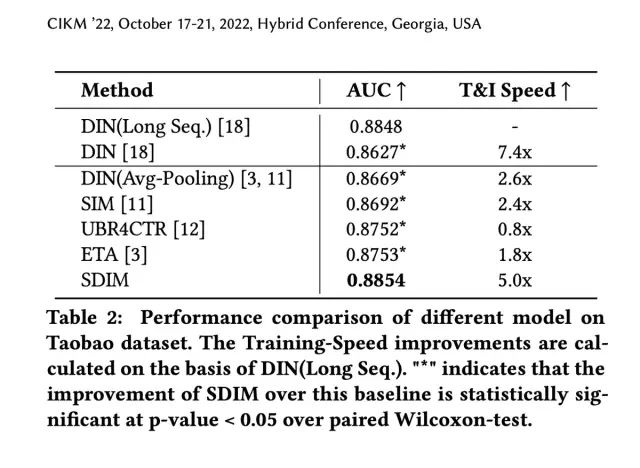
最后来看一下实验结果。从离线实验来看,SDIM从效果和训练速度上来看,在淘宝公开数据集和工业数据集上均取得了比Base模型不同程度的提升:
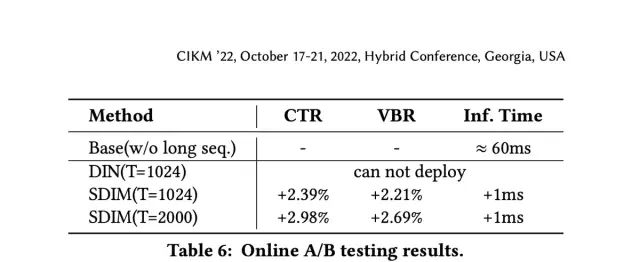
从线上A/B测试来看,SDIM也取得了更优的线上CTR和购买率的提升:
最后简单总结一下,本文在CTR预估模型中引入了(𝑚,𝜏)-parameterized SimHash的方法,在attention的计算方面达到了与target attention相近的结果,端到端地有效建模长用户行为序列的同时极大的减少了计算复杂度。而在线上通过拆分部署的方式,极大减少了线上的预估耗时,提升系统的推荐性能和效果。
好了,论文就介绍到这里,一篇非常不错的工业落地方面的论文,感兴趣的同学可以阅读原文~










