波尔德回答:
当然可以。其实吧,很多苦逼硕士/博士/博后都是在独自憋论文。
你以为的AI科研:巨佬导师每周亲自辅导,传授独门知识经验;导师给你的题目眼光毒辣,是一座金矿,随便一划拉就能出文章;同门之间紧密合作,每周都有头脑风暴和paper reading,碰撞出思维的火花;满世界开会,和同行谈笑风生;课题组人均八张A100,没见过小于4096的batch size;你的导师能搞定审稿人甚至chair;你的课题组就是你领域的最前沿,你在推特上每推一篇新的arxiv就会有同行跟进。
实际上大部分人的科研:你导师拿到终身教职之后就懒得卷了,放羊,你干的事他不清楚,也懒得问;导师给你的课题里有巨坑,你毫不意外掉了进去,费劲吧啦爬了上来,并且思索怎么把这鬼东西填上;组里每个人都在干完全不搭嘎的题目,只能在吐槽审稿人和讨论附近哪家土耳其烤肉好吃的时候说到一起去;因为corona,你已经好几年没出差开过会了;你的台式机只有一张10GB左右的显卡,在公共cluster排队的时间远超过使用时间本身,你甚至自费买卡;你被审稿人伤害并且无能狂怒;你啥也不是,没有人认识你,你精心打造的research gate访问量为零。
你看,跟在家自己憋其实区别不大。
艹,我为什么会这么熟练。
kai.han回答:
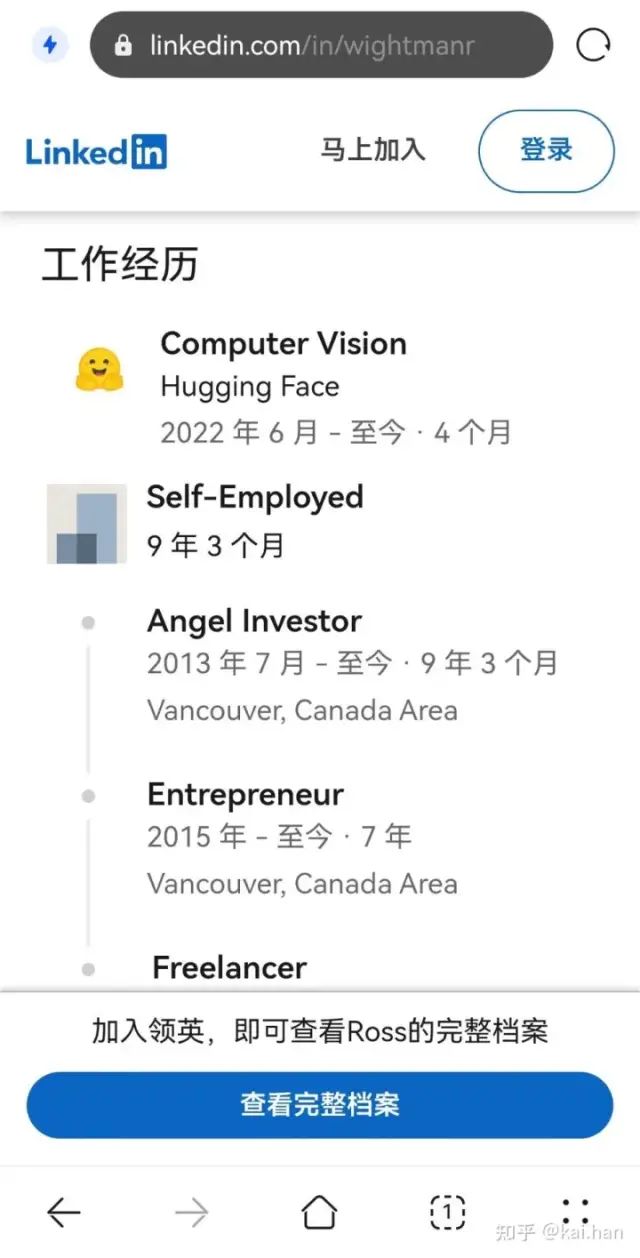
有啊,比如计算机视觉timm库作者Ross Wightman,长达9年多的自由职业,在此期间他不仅构建了timm库,还参与了How to train your ViT、ResNet Strikes Back等著名论文。看他简历,还是个天使投资人,应该有亿点点钱吧。
Yan回答:
想到了我一位学长业余时间弄的一篇,发在了CVPR22。

丁霄汉(清华博士 腾讯AILab高级研究员)回答:
可以的。如果假设题主能想出idea的话,那么只要一台机器四张卡(四张2080Ti/3080带平台,整台机器也就五到十万吧),一年几万块钱的电费就可以。
最大的问题是在没有人带路的情况下,idea立意、实验技能和写作技巧的提升都需要时间。被拒两三次,总共花费一到两年以后,自己的综合水平达到顶会的门槛上下时,再投几次应该就有机会了。
RunningVegeDog回答:
之前在字节的时候,业余时间水了一篇cvpr2020。卡是用的公司的,合作者是读研时期的师兄,指导我的是style2paints的lvmin zhang,算是网友吧,至今还没有线下见过面。
最近从腾讯离职以后,借着做副业的公司的卡又做了一些工作,准备把论文写出来,投到大家都知道是哪个但是出于双盲原则我不能说的会议。有兴趣可以去github关注一下,如果中了有可能开源代码或者模型(或者搞个网页api):

CPAPCF回答:
我跟人合作的,自己solo author的,多线并行什么都不耽误。有点cs基础的人都该知道pipelining和多线并行才是掩盖延迟和机会成本的黄金手段。
我chair还每天都在对着我叹气,就不能多掰点给咱本系的人合作synergetic collab嘛。我说咱招学生都知道的铁律:disappointments are always disappointments烂泥扶不上墙,PI照样同理,打游戏菜是原罪,学术界蠢是原罪。跟绝大部分没那脑子的人合作还不如自己做完早发了,哪怕想带资进组co-PI的人干不了活也是累赘。我说作为从俺们以前那组出来的人,we can never make sense of or sympathize with poverty-stricken PIs.
Jin.Carlo回答:
在家9个月的博士生来回答,当然是可以了。可以远程操控学校的工作站啊。平常大概用2-4块GPU就够了(目标检测方向)。
在学校和在家都差不多,工作日除了吃喝拉撒就是科研,周末多了个打球外也是科研。在家伙食更好,奶茶,披萨,火锅想吃就吃。有什么讨论线上进行。
休闲与忙碌看心情,想闲的话就一天只干一小时以内,想忙碌的话一天15个小时。不强迫自己赶工,有时一整天下来除了测结果与开新实验就没有别的。不过我认为思考也是要占时间的,而且思考可以占科研的大部分时间。有的新思想火花是有效的,也有的是不切实际的臆想。
很难定义什么是工作效率。效率并不是看一天改了多少代码,写了多少论文。有时一整天的思考即便没有产生任何现实收益,但积累下来也可能将研究工作推向一个新的高度。
有人可能比较好奇,2-4块GPU (RTX 3090)能做目标检测?我认为这个设备配置是刚刚好的。
首先,目标检测的两大通用benchmark是PASCAL VOC和MS COCO。前者使用VOC 07+12训练协议含训练集16551张图像,测试集4952张图像。后者一般使用coco 2017 train的118K训练集,以及5K张图像的2017 val来验证。
主干网络使用ResNet-50-FPN,使用FCOS,双3090训练voc,只需一小时出头的时间,训练ms coco需要8~9小时。而且还有minicoco可以使用,时间可以缩短至2小时以内。并且,得益于3090的显存,训练所用batchsize也可以调至默认设置16。因此,这样的时长,足以快速验证idea,并进行大量的ablation。
双卡的话,2小时一个结果,4卡的话2小时两个结果。这空出来的2小时有利于我们分析实验结果,思考下一步探索方向,完善背后理论,进行多线操作。我试过使用12块GPU,但也仅仅是在已经探索出确定可行的方法后,进行扫尾ablation时有效率,若是在前中期探索阶段,效率反而有所下降。
第一,频繁地开启实验,记录实验,不可避免就容易开启大量的无效实验。因为在设备过多时,人从心理上就会产生不要浪费的念头,进而在还没有产生有希望的idea时就被迫开启了实验。这样匆忙开启实验也容易开启参数设置不对,代码有bug的实验。最终导致我们在错误的实验上还要投入大量的脑力去分析,去思考,造成机器与人力双浪费。
第二,使用较少的GPU,不仅可以增大有效实验进行的几率,还可以有适度的时间思考,劳逸结合。
第三,小模型能成功的算法,多半在大模型上也能成功。算法的改进,一般与网络结构大小无明显关联,只是有涨幅的高低区别。因此,在前中期探索阶段,也无需在大模型,大规模数据集上怼算力。
文章转载自知乎,著作权归属原作者。
- 机器学习交流qq群955171419,加入微信群请扫码











