多模态机器学习在各种场景下都取得了令人瞩目的进展。然而,多模态学习模型的可靠性尚缺乏深入研究。「信息是消除的不确定性」,多模态机器学习的初衷与这是一致的——增加的模态可以使得预测更为准确和可靠。然而,最近发表于 ICML2023 的论文《Calibrating Multimodal Learning》发现当前多模态学习方法违法了这一可靠性假设,并做出了详细分析和矫正。

当前的多模态分类方法存在不可靠的置信度,即当部分模态被移除时,模型可能产生更高的置信度,违反了信息论中 「信息是消除的不确定性」这一基本原理。针对此问题,本文提出校准多模态学习(Calibrating Multimodal Learning)方法。该方法可以部署到不同的多模态学习范式中,提升多模态学习模型的合理性和可信性。
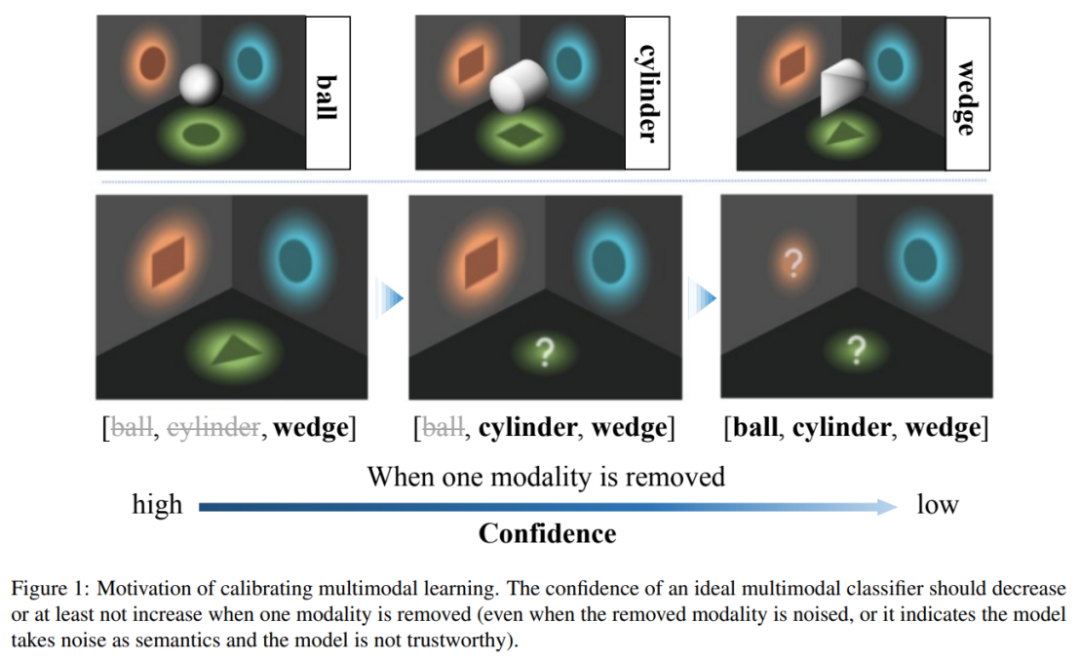
该工作指出,当前多模态学习方法存在不可靠的预测置信度问题,现有多模态机器学习模型倾向于依赖部分模态来估计置信度。特别地,研究发现,当前模型估计的置信度在某些模态被损坏时反而会增加。为了解决这个不合理问题,作者提出了一个直观的多模态学习原则:当移除模态时,模型预测置信度不应增加。但是,当前的模型却倾向于相信部分模态,容易受到这个模态的影响,而不是公平地考虑所有模态。这进一步影响了模型的鲁棒性,即当某些模态被损坏时,模型很容易受到影响。
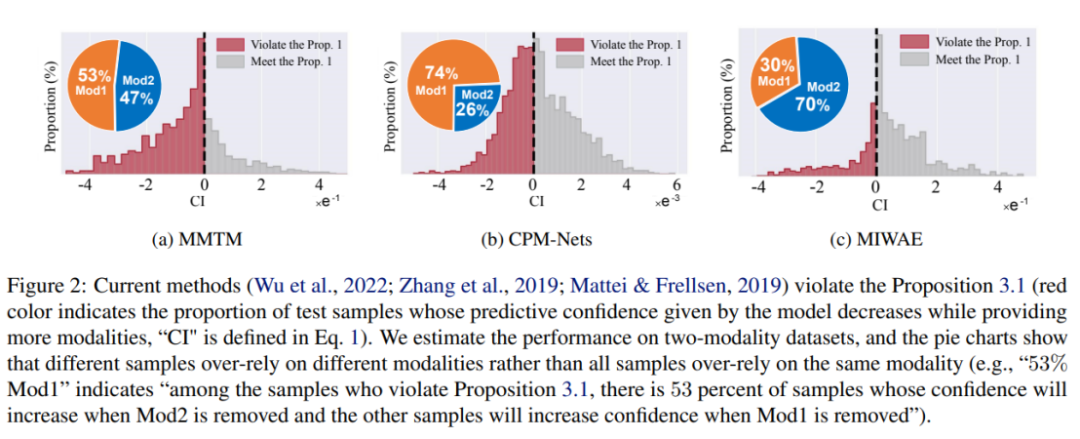
为了解决上述问题,目前一些方法采用了现有的不确定性校准方法,例如 Temperature Scaling 或贝叶斯学习方法。这些方法可以构建比传统训练 / 推理方式更准确的置信度估计。但是,这些方法只是使最终融合结果的信心估计与正确率匹配,并没有明确考虑模态信息量与信心之间的关系,因此,无法本质上提升多模态学习模型的可信性。
作者提出了一个新的正则化技术,称为 “Calibrating Multimodal Learning (CML)”。该技术通过添加一项惩罚项来强制模型预测信心与信息量的匹配关系,以实现预测置信度和信息量之间的一致性。该技术基于一种自然的直觉,即当移除一个模态时,预测置信度应该降低(至少不应该增加),这可以内在地提高置信度校准。具体来说,提出了一种简单的正则化项,通过对那些当移除一个模态时预测置信度会增加的样本添加惩罚,来强制模型学习直观的次序关系:
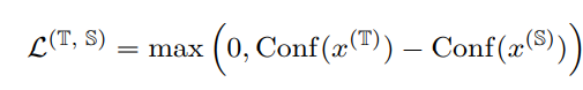
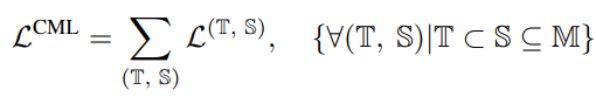
上面的约束为正则损失,当模态信息移除信心上升时作为惩罚出现。
实验结果表明,CML 正则化可以显著提高现有多模态学习方法的预测置信度的可靠性。此外,CML 还可以提高分类精度,并提高模型的鲁棒性。
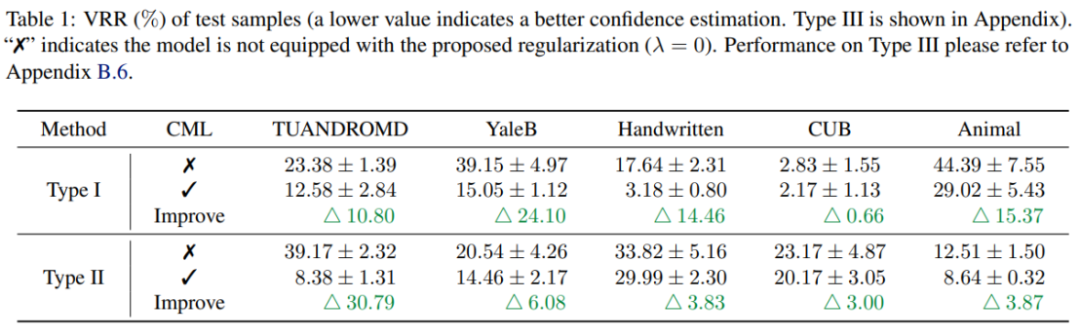
多模态机器学习在各种情境中取得了显著的进展,但是多模态机器学习模型的可靠性仍然是一个需要解决的问题。本文通过广泛的实证研究发现,当前多模态分类方法存在预测置信度不可靠的问题,违反了信息论原则。针对这一问题,研究人员提出了 CML 正则化技术,该技术可以灵活地部署到现有的模型,并在置信度校准、分类精度和模型鲁棒性方面提高性能。相信这个新技术将在未来的多模态学习中发挥重要作用,提高机器学习的可靠性和实用性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com











