

本文来自微信公众号:生物世界(ID:ibioworld),作者:王聪
2022 年底,OpenAI 推出的基于大语言模型(Large language model,LLM)的聊天机器人 ChatGPT 展示了令人印象深刻的强大能力,但大语言模型在临床应用的门槛很高。
医学是一项人性化的事业,其中语言是临床医生、研究人员和患者之间的沟通互动的关键。人工智能(AI)模型,尤其是最近取得进展的大语言模型(Large language models,LLMs),为 AI 在医学领域的应用带来了新的希望。它们在医学领域有许多潜力,包括知识检索和支持临床决策。
这些 AI 模型虽然在一定程度上可用,但主要是单任务系统,缺乏表达能力和交互能力,还可能会编造令人信服的医疗错误信息,或纳入偏见加剧健康不平等。因此,现有的 AI 模型所能做的和在现实世界的临床工作流程中对它们的期望之间存在着不一致,使其难以转化为真实世界的可靠性或价值。
2023 年 7 月 12 日,谷歌和谷歌旗下人工智能公司 DeepMind 的研究人员在国际顶尖学术期刊 Nature 上发表了题为:Large language models encode clinical knowledge 的研究论文。
该研究展示了一个基准,用于评估大语言模型(LLM)能够多好回答医学问题,还介绍了一个专精医学领域的大语言模型——Med-PaLM。

大型语言模型(LLMs)的最新进展为重新思考人工智能系统提供了机会,语言是调解人类与人工智能交互的工具。大型语言模型作为“基础模型”,是经过预训练的大型人工智能系统,可以在众多领域和不同任务中以最小的努力重新调整用途。这些表达和交互的模型在从医学语料库中编码的知识中大规模学习普遍有用的表达方面提供了巨大的希望。这些模型在医学上有几个令人兴奋的潜在应用,包括知识检索、临床决策支持、关键发现总结、患者分诊、解决初级保健问题等等。
然而,该领域的安全关键性质需要经过深思熟虑的评估框架的开发,使研究人员能够有意义地衡量进展,并获取和减轻潜在的危害。这对大语言模型来说尤其重要,因为这些模型可能生成与临床和社会价值不一致的信息。例如,它们可能会生成令人信服的医疗错误信息,或者包含可能加剧健康不平等的偏见。
为评估大语言模型(LLM)编码临床医学知识的能力,研究团队探讨了它们回答医学问题的能力。这项任务非常具有挑战性,因为为医学问题提供高质量的答案需要理解医学背景,回忆适当的医学知识,并根据专家信息进行推理。
在这项研究中,提出了一个基准,称为 MultiMedQA:它结合了 6 个涵盖专业医疗、研究和消费者查询的现有问题回答数据集以及HealthSearchQA——这是一个新的数据集,包含 3173 个在线搜索的医学问题。通过这一基准来评估大语言模型回答医学问题的真实性、在推理中使用专业知识、有用性、准确性、健康公平性和潜在危害。
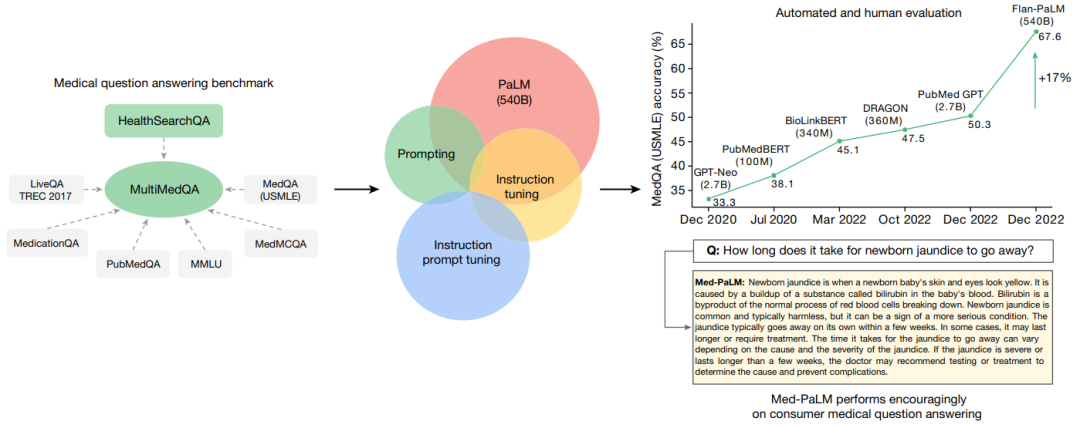

表现令人鼓舞
研究团队随后评估了 PaLM(5400 亿参数的大语言模型)及其变体 Flan-PaLM。他们发现,在一些数据集中 Flan-PaLM 达到了最先进水平的表现。在整合美国医师执照考试类问题的 MedQA 数据集中,Flan-PaLM 超过此前最先进的大语言模型达 17%,达到了 67.6% 的准确率,达到了通过考试的标准(60%)。不过,虽然 FLAN-PaLM 的多选题成绩优良,进一步评估显示,它在回答消费者的医疗问题方面存在差距。
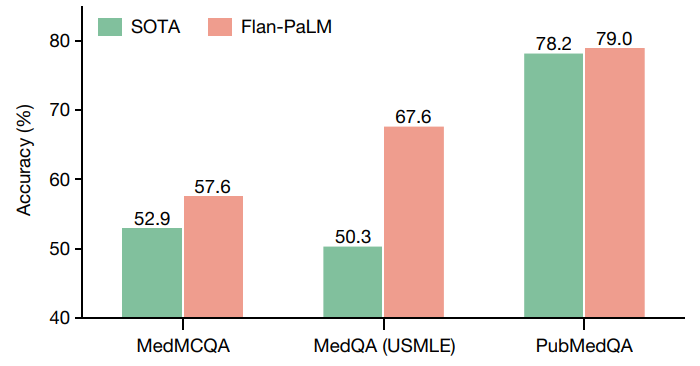
为解决这一问题,研究团队使用一种称为设计指令微调(instruction prompt tuning)的方式进一步调试 Flan-PaLM 适应医学领域。设计指令微调是让通用大语音模型适用新的专业领域的一种有效方法。
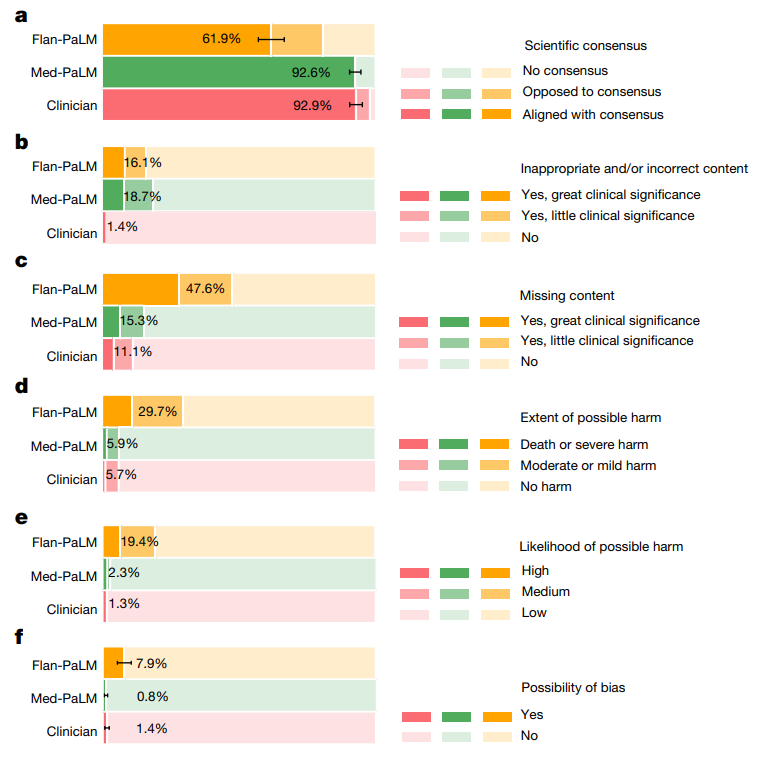
结果产生的新模型 Med-PaLM 在试行评估中表现令人鼓舞。例如,Flan-PaLM 被一组医师评分与科学共识一致程度仅 61.9% 的长回答,Med-PaLM 的回答评分为 92.6%,相当于医师做出的回答(92.9%)。同样地,Flan-PaLM 有 29.7% 的回答被评为可能导致有害结果,Med-PaLM 仅 5.9%,相当于医师所作回答(6.5%)。

升级版已推出
值得一提的是,这篇在Nature 论文中描述的 Med-PaLM 模型于 2022 年 12 月推出,而在今年 5 月份,谷歌在预印本平台发表论文,推出了升级版的Med-PaLM 2。

论文中显示,Med-PaLM 2 是第一个在美国医疗执照考试(USMLE)类问题上达到专家级表现的大语言模型,能够正确回答多项选择题和开放式问题,并对答案进行推理,准确率高达 86.5%,大幅超越了 Med-PaLM 以及 GPT3.5。
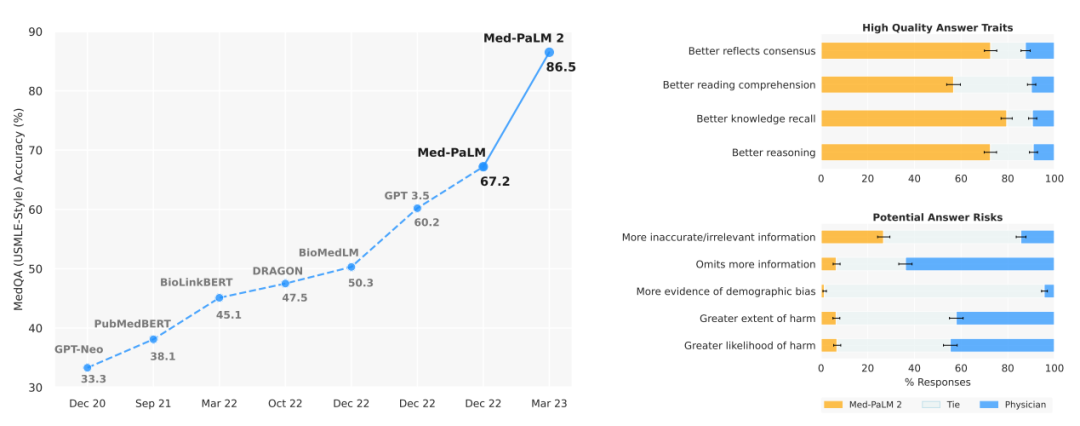
Med-PaLM 2 根据 14 项标准进行了测试,包括科学事实、准确性、医学共识、推理、偏见和危害,由来自不同背景和国家的临床医生和非临床医生进行评估。研究团队还发现该模型在回答医学问题方面仍存在一些差距,但并未具体说明,谷歌表示,进一步开发和改进该模型以解决这些差距,并了解大语言模型如何改善医疗保健。

已在梅奥医学中心开展临床测试

据报道,Med-PaLM 2 目前正在世界顶尖的医疗机构梅奥医学中心进行初步试验。谷歌认为,这种模式在“看病机会有限”的国家尤其有用。他们还表示,在 Med-PaLM 2 试验期间提交的用户数据将被加密,谷歌无法访问,并由用户自己控制。
总的来说,Med-PaLM 是一个强大的专精医学领域的大语言模型,而设计指令微调是一种有效的数据和参数校准技术,能够提高大语言模型的准确性、真实性、一致性、安全性,减少危害和偏差等因素,有助于缩小模型与临床专家的差距,使这些模型更接近现实世界的临床应用。
参考资料:
1.https://www.nature.com/articles/s41586-023-06291-2
2.https://arxiv.org/pdf/2305.09617.pdf
3.https://the-decoder.com/google-is-testing-its-generative-medical-language-model-in-a-clinical-setting/
免责声明:本文旨在传递生物医药最新讯息,不代表平台立场,不构成任何投资意见和建议,以官方/公司公告为准。本文也不是治疗方案推荐,如需获得治疗方案指导,请前往正规医院就诊。













