关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
连「作为一个大模型……」这样的 AI 语都忘了删就提交,结果还过审发表了。
ChatGPT 出现以后,很多学术机构都发出了禁令,因为这种 AI 虽然生成能力强,但有时会胡说八道,滥用大模型写文章也违背了做研究的初衷。
但随着大模型的应用浪潮,我们很快忘记了刚开始的恐惧。有学术机构正在解禁,微软也计划在年内把 ChatGPT 整合到 Office 全家桶里。或许过不了多久,人人都可以用大模型去写文章。
这让人不得不去想象以后的学术论文会被 AI 生成的内容冲击成什么样。其实,这种事可能已经在发生了。
今天,有个斯坦福本科生在谷歌学术搜索(Google Scholar)上就发现了这类「浑水摸鱼」的掺假论文。
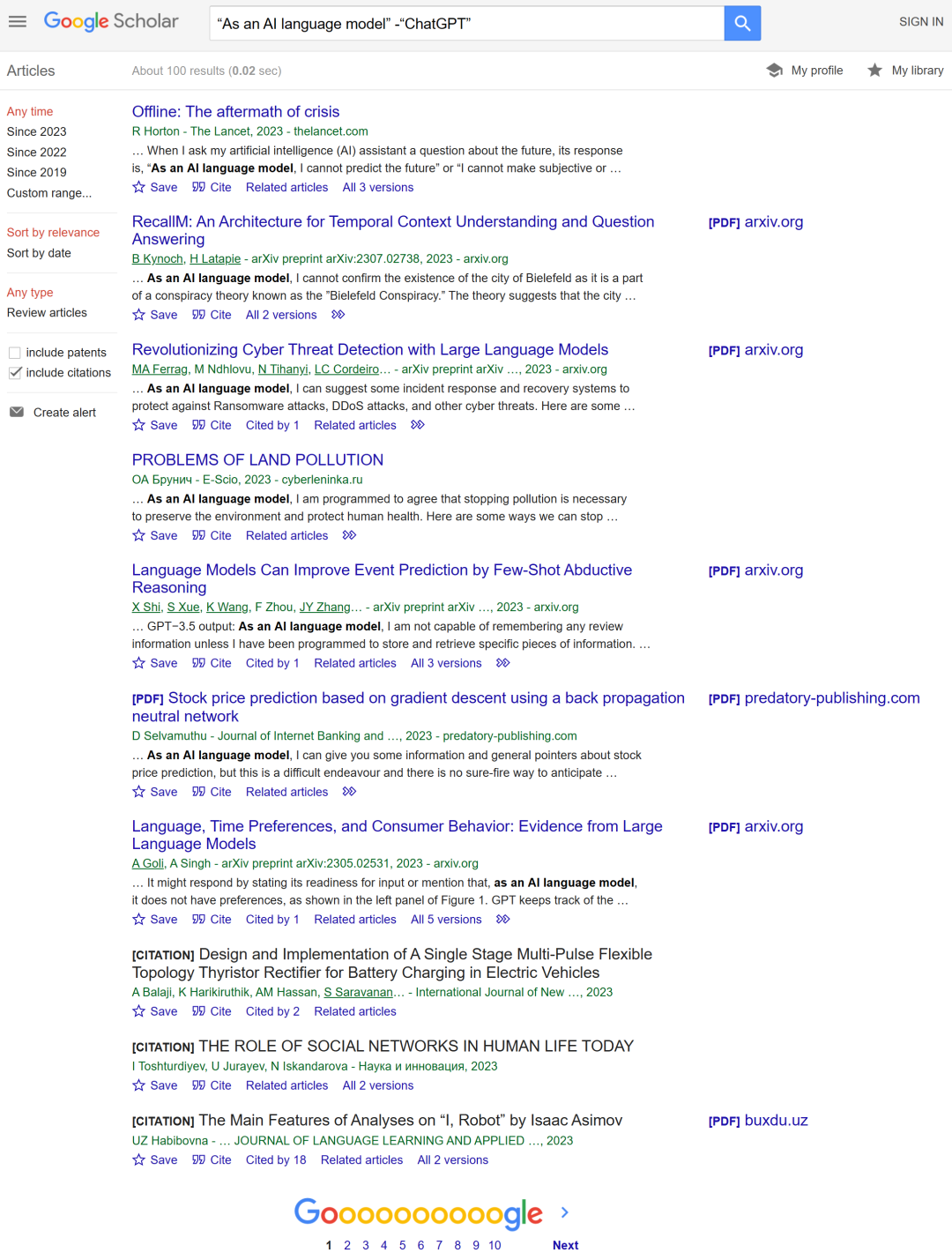
当你输入「“As an AI language model” -“ChatGPT”」搜索时,会搜到很多直接将 ChatGPT 答案贴上去的论文。

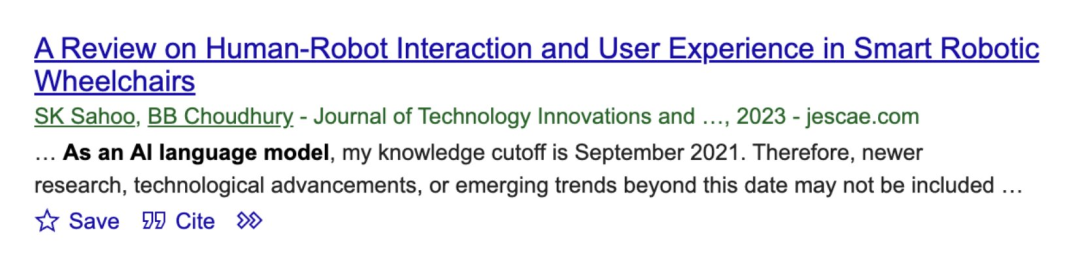
比如下面这篇经过同行评审、发表在《国际工程与技术创新期刊》的论文中,作者似乎遗漏了一个重要的合著者 ——AI 语言模型(ChatGPT)。

突出一个投者无心,审稿故意。
另外一篇经过同行评审、发表在《网络银行和商业杂志》上的论文,题目为《基于反向传播神经网络和梯度下降的股价预测》,同样有不存在的作者 ——ChatGPT。

开篇就是 AI,看上去让人忍俊不禁。
类似例子还有很多,比如下面两篇分别发表在《国际现代农业和环境期刊》和《技术创新和能源杂志》上的论文。

更离谱的是,下面这篇发表在《国际高级工程和土木研究期刊》的论文,ChatGPT 甚至引用了作者 X 和 Y 的一篇虚假(fake)文章。

除了参与论文撰写之外,ChatGPT 还参与了一些书籍的写作,比如下面的《性知识入门》和《利比亚概览》。


机器之心也在谷歌学术中输入「“As an AI language model” -“ChatGPT”」,结果出现了 10 个页面,有 100 篇左右。
Andrew Kean Gao 的发现在推特(X)上吸引了上百万人的围观,Google Scholar 似乎对此很快做出了反应。最新的情况是:很多能被搜到的 AI 文章只有名字,不给链接了。不过必须要说的是,这距离真正的「整顿」还差的挺远。
在 AI 领域,大模型的发展速度以天为计,学术期刊的审稿规则为了应对也在急速变化。此前,很多期刊、会议禁止将 ChatGPT 列为合著者。
其中《科学》杂志明确表示不接受 ChatGPT 生成的论文,也不允许 ChatGPT 作为论文作者。《自然》杂志则表示可以使用 ChatGPT 等大语言模型工具撰写论文,但也禁止列为论文合著者。
对于这位斯坦福本科生的发现,有人揶揄道,你不会以为人们在发表论文之前会再通读一遍吧。也有人再补了一刀,在发表之前让 ChatGPT 再读一遍。


或许真正的问题在于,这些论文是如何通过编辑审核或同行评审的。


最后有人一语道破天机,表示这些都是四级(four-tier)期刊,只要付钱啥都可以发表,都是一些毫无意义的垃圾。

至少目前来说,ChatGPT 生成的论文还没造成太大影响。就是不知这种工具在 Office 上真正流行起来,学术界会变成什么样子。
参考链接:
https://twitter.com/itsandrewgao/status/1689634145717379074
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
【CV知识点汇总与解析】| 技术发展篇 (超详细!!!)
最新论文解析
NeurIPS2022 Spotlight | TANGO:一种基于光照分解实现逼真稳健的文本驱动3D风格化
ECCV2022 Oral | 微软提出UNICORN,统一文本生成与边框预测任务
NeurIPS 2022 | VideoMAE:南大&腾讯联合提出第一个视频版MAE框架,遮盖率达到90%
NeurIPS 2022 | 清华大学提出OrdinalCLIP,基于序数提示学习的语言引导有序回归
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索








