在多因子选股模型中,因子的开发和更新迭代变得越来越重要。与低频因子相比,高频数据在用于量化投资中存在一定优势,而高频数据挖掘因子的难点在于数据维度大、噪声高。机器学习方法擅长从数据中寻找规律和特征,是高频数据因子挖掘的有力工具。本报告在预先将高频信息处理成日频因子之后,在日频因子的基础上,用深层全连接神经网络模型提取股票特征。模型采用了55个高频数据低频化的人工因子作为神经网络的输入,在深层神经网络提取特征之后,对特征进行分析并筛选合适的选股因子。深度学习模型共获得32个特征因子,这些特征因子与模型输入的人工因子具有相对的独立性,在创业板和中证1000股票池中展现出不错的选股性能。在周度换仓的频率下,双边千三计费后,在模型的训练和验证样本外的过去三年里,hf18因子在创业板股票池中的Rank_IC为-6.79%,取得了27.25%的多头年化收益率,相对于同期的创业板指数取得了25.50%的超额年化收益率,信息比为1.04;hf13因子在中证1000股票池中Rank_IC为6.63%,取得了11.25%的多头年化收益率,相对于同期的中证1000指数取得了7.24%的超额年化收益率,信息比率为0.64。本专题报告所述模型用量化方法通过历史数据统计、建模和测算完成,所得结论与规律在市场政策、环境变化时可能存在失效风险;策略在市场结构及交易行为的改变时有可能存在策略失效风险。
近年来,A股市场机构化趋势明显,量化私募机构的管理规模也迅速扩大,产生了一批管理规模超过百亿的量化私募机构。与此同时,传统的风格因子波动增大,从市场获取超额收益的难度在增加。因子拥挤是因子收益下降的原因之一。因子代表着市场某方面的非有效性、或者是一段时期内的定价失效。当某类因子收益高的时候,会吸引更多的资金进入,从而出现因子拥挤,降低因子的预期收益。一旦新的因子被公开,套利资金的介入会使得错误定价收窄,因子收益也会跟着下降。因此,在多因子选股模型中,因子的开发和更新迭代变得越来越重要。以传统日频价量和更低频财务数据为基础的因子开发是一种研究途径。由于基础因子广为人知,在此基础上进行因子挖掘的收益提升空间相对有限。而且日频数据由于本身的数据量和信息量有限,过度挖掘会增大过拟合的风险。以高频价量数据为基础的因子开发在当下具有更大的收益提升空间。与低频因子相比,高频数据在用于量化投资中存在一定优势。首先,高频价量数据的体量明显大于低频数据。以分钟行情为例,用压缩效果较好的mat格式存储2020年全市场股票的分钟行情数据(包括分钟频的开高低收价格数据、买卖盘挂单数据等),约为12GB。如果是快照行情(目前上交所和深交所都是3秒一笔)或者level 2行情,数据量要大很多。因此,高频数据因子挖掘对信息处理能力和处理效率的要求较高。而且,日内数据,尤其是level 2数据,一般要额外付费,甚至需要自行下载存储实时行情,在此基础上构建的因子拥挤度较低。其次,高频价量数据一般是多维的时间序列数据,数据中噪声比例较高,而且与ROE、PE这类低频指标本身就具有选股能力不同的是,原始的高频行情数据一般不能直接用作选股因子,而要通过信号变换、时间序列分析、机器学习等方法从高频数据中构建特征,才能作为选股因子。此类因子与低频信号的相关性较低,而且由于因子开发流程相对复杂,不同投资者构建的因子更具有多样性。此外,高频数据开发的因子一般调仓周期较短,意味着在检验因子有效性的时候,同一段测试期具有更多的独立样本。例如,在一年的测试期内,只有12个独立的样本段用于检验月频调仓的因子,与之相比,有约50个独立的时段用于检验周频调仓因子,有超过240个独立的时段用于检验日频调仓的因子。独立样本的增多有助于检验高频因子的有效性。高频数据挖掘因子的难点在于数据维度大、噪声高。凭借专业投资者的经验或者是参阅已发表的文献,可以从高频数据中提炼出一部分有选股能力的特征。此外,机器学习方法擅长从数据中寻找规律和特征,是高频数据因子挖掘的有力工具。本报告借鉴机器学习领域特征工程的思路,从高频价量数据中提炼选股因子。在机器学习领域,“正确”的特征应该适合当前的任务,并易于被模型使用。合理的特征设计可以使得后续模型建立更容易,提升模型的预测能力。特征工程就是在给定数据、模型和任务的情况下设计出最合适的特征的过程。特征设计主要是指对原始数据进行加工、特征组合,生成有一定意义的新变量(新特征)。以健康管理为例,通过观察者的身高、体重、或者两者的线性加权,并不能直接判断其是否肥胖,而通过适当的变量组合之后形成的BMI指数(体重除以身高的平方)则是一个非常简明的指标,可以直接用BMI指数的大小判断观察者是否肥胖。领域知识可以显著提升特征的挖掘效率。在多因子选股体系中,不同的选股因子即是结合金融市场特点构建的特征。盈利、成长、价值、质量、动量、流动性等因子都是投资者通过经济学逻辑和金融市场的特点构建的选股因子。基于上述因子筛选的股票组合有望跑赢市场。随着我们将研究对象从低频数据转向高频数据,数据的维度变得更高、信息密度变得更低、噪声含量变得更高。此时,专家的金融领域知识相对匮乏,而机器学习等方法擅长处理海量数据和高维特征,在这种情景下更能体现其优势。遗传规划是一种启发式搜索算法,在选股因子构建时,一般以因子收益率或者因子IC为优化目标,通过不断迭代进化因子计算表达式,获取预测能力强的因子。机器学习特征生成是在机器学习方法对数据进行建模的同时,产生新特征。可以产生新特征的机器学习模型包括主成分分析、梯度提升树和深度学习等。主成分分析是一种常见的数据预处理和特征生成方法,通过线性投影将原始的变量变换为主成分变量。但主成分分析是一种线性算法,不能产生更具有多样化的非线性特征,而且无监督学习方法生成的特征对后续分类或者回归模型的提升有限。在2014年发表的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》,Facebook研究团队提出了经典的梯度提升树(Gradient Boosting Decision Trees,GBDT)+逻辑回归的点击率预测模型结构,可以说开启了特征工程自动化的新阶段。该模型如下图所示,GBDT模型的决策树对样本进行处理,生成特征,将新特征输入给逻辑回归模型,实现分类目标。图中展示了两棵决策树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应逻辑回归的某一维特征(0/1取值,如果样本落在该叶子节点上,则取值为1,否则取值为0)。通过遍历决策树,就得到了该样本对应的所有特征。下图的左树有三个叶子节点,右树有两个叶子节点,最终的特征即为5维的向量。对于输入x,如果落在左树第3个节点,则编码[0,0,1],落在右树第1个节点则编码[1,0],整体的编码为[0,0,1,1,0]。本报告在预先将高频信息处理成日频因子后,在日频因子的基础上,用深层全连接神经网络模型提取股票特征。深层神经网络是对股票因子和未来收益率之间的关系进行建模。本报告的网络模型采用了55个日频变量作为神经网络的输入,这些日频变量是高频数据低频化的股票特征,具体特征定义在下一节所示。在本报告的深度学习选股模型中,我们采用7层神经网络系统建立股票价格预测模型。其中包含输入层X,输出层Y,和隐含层H1、H2、H3、H4、H5。各层的节点数如下表所示。
价格数据中蕴含了丰富的股票信息,本报告从日内累积收益率、日内收益率的高阶统计量和日内价格的趋势强度进行考察,确定了10个候选因子,如下表所示。

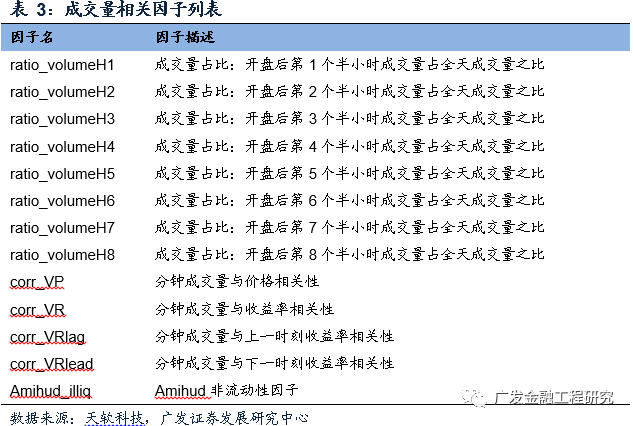
成交量也是日内行情信息的重要组成部分。一方面,成交量的分布可以反映投资者的行为特征,另一方面,成交量与价格或者价格走势的关系可以确认价格形态的信息。本报告考察的成交量相关因子如下表所示。
盘前价量信息主要包括隔夜收益率(开盘价相对前收盘的收益率)和开盘前集合竞价信息。目前,A股证券交易所在每个交易日的9:15至9:25为开盘集合竞价时间。开盘集合竞价又分为两个阶段,其中第一阶段是9:15至9:20,该阶段允许撤销已经提交的订单;第二阶段是9:20至9:25,该阶段不允许撤销已经提交的订单。集合竞价信息反映出资金的试盘行为和多空双方的博弈。本报告考察隔夜收益率和集合竞价的相关因子如下所示。
此外,可以将部分时段的数据进行重点分析,产生衍生因子。一般来说,开盘后半小时(9点半至10点)和收盘前半小时(14点半至收盘)的股票成交活跃,多空博弈激烈,蕴含的信息相对较多。本报告针对开盘后半小时和收盘前半小时的价量信息构建了如下因子。
在不同的成交中,大单成交与主力资金关联较多,蕴含的信息可能更多。本报告将个股在每个交易日的分钟成交量时间序列按照成交量大小排序,将分钟成交量排名前1/3的成交量定义为“大成交量”。针对大成交量对应的时刻的股价信息,可以构建大成交量相关因子。
以2007年1月至2020年6月的全市场数据作为样本内的训练和验证数据,其中2007年1月至2017年12月的数据为训练数据,2018年1月至2020年6月的数据为验证数据,用以确定模型在训练过程中的最佳早停时点。此外,将2020年7月至2023年6月期间的数据作为样本外回测数据。根据当期股票的因子值和方向分为10档,其中前10%和后10%分别作为多头和空头,每5个交易日进行调仓,双边千三计费,并剔除了ST/ST*、涨跌停板、上市未满1年的股票。
观察深层神经网络最顶端隐藏层(H5层)的32个特征,将其节点依次编号为0,1,……,31,称之为因子hf0,hf1,……,hf31。在创业板中,32个深度学习特征因子在样本外选股表现如下表所示,共有14个因子的多头年化收益率超过了10%,其中hf18因子的多头年化收益率达27.25%最为突出,其Rank_IC为-6.79%,多空年化收益率为39.44%;hf2因子的多空年化收益率达53.21%,Rank_IC为-8.43%。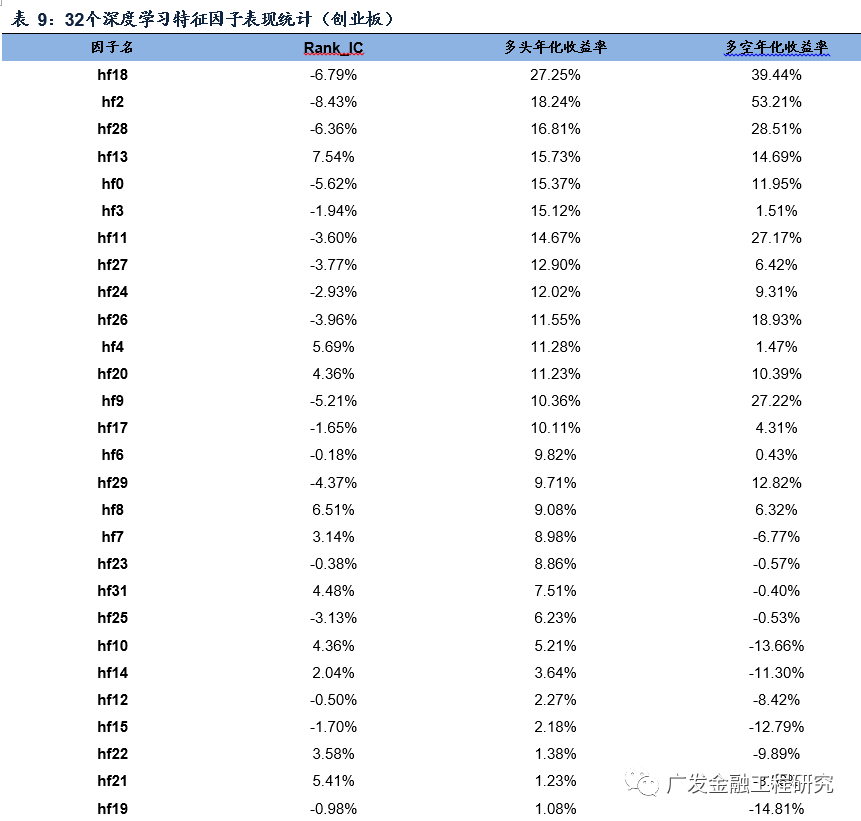

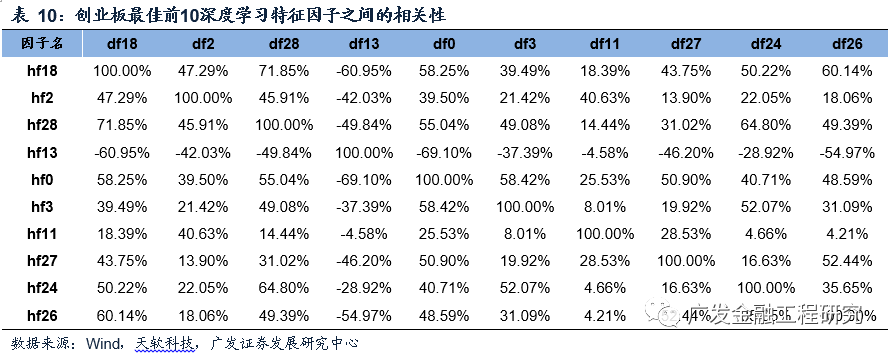
在创业板中选取最佳前10的深度学习特征因子计算其相关性,结果如下表所示,整体而言不同的深度学习特征因子之间展现出了一定的非相关性。
在创业板中选取最佳前5的深度学习特征因子与高频人工因子计算其相关性,结果如下表所示,经过神经网络构建的深度学习特征因子与输入的高频因子之间的相关性较低,得到的深度学习特征因子是一组相对独立的新因子。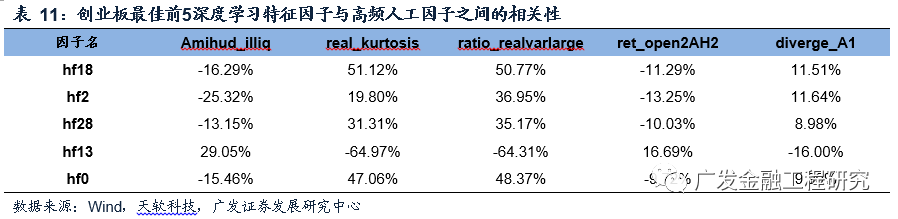
单独研究在创业板中表现最佳的hf18因子,其分档表现较为显著,其中Q1档作为多头的表现最为突出,多头年化收益率达27.25%,相对于同期创业板指的超额年化收益率达25.50%。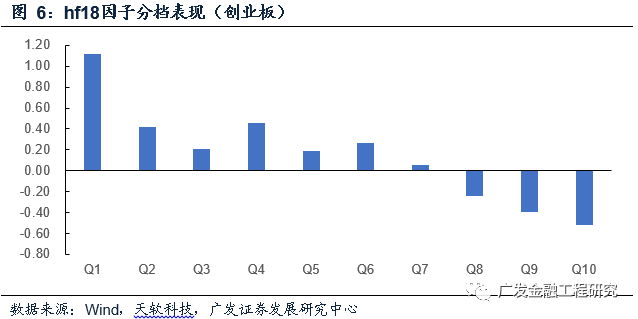

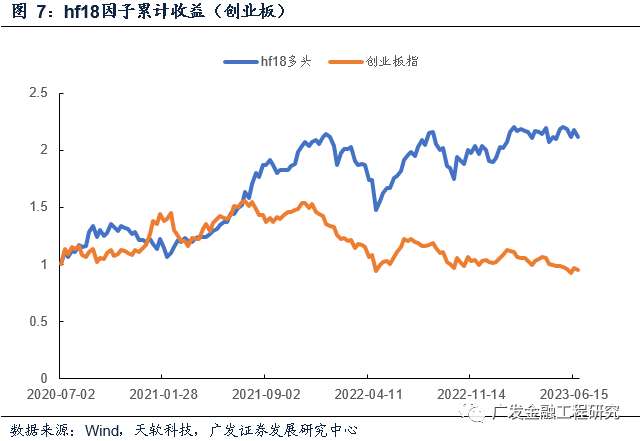
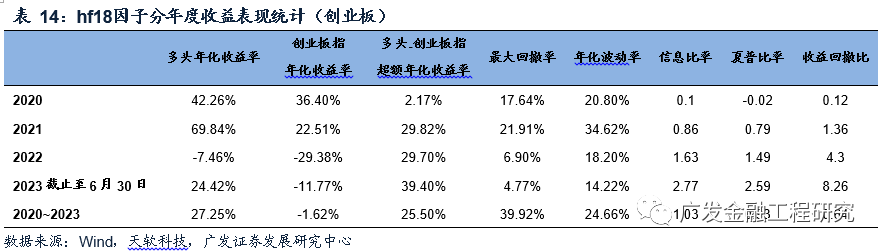
hf18因子在创业板中的分年度Rank_IC和收益表现统计如下表所示。在各年份中,hf18因子的表现较为稳定,负Rank_IC占比均超过了75%,在2021年之后超过了85%;由hf18因子筛选得到的创业板多头组合在2021年之后的超额年化收益率超过了29%,在2023年达39.40%。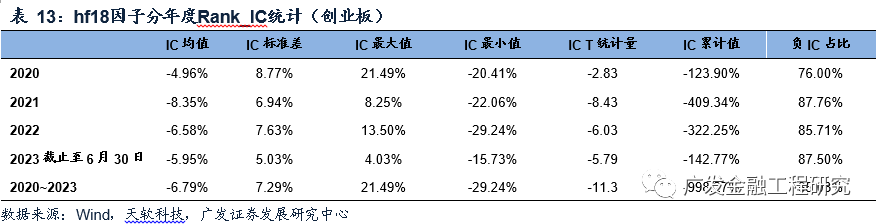
本报告在预先将高频信息处理成日频因子之后,在日频因子的基础上,用深层全连接神经网络模型提取股票特征。模型采用了55个高频数据低频化的人工因子作为神经网络的输入,在深层神经网络提取特征之后,对特征进行分析并筛选合适的选股因子。深度学习模型共获得32个特征因子,这些特征因子与模型输入的人工因子具有相对的独立性,在创业板和中证1000股票池中展现出不错的选股性能。周度频率换仓,双边千三计费后,在模型的训练和验证样本外的过去三年里, hf18因子在创业板股票池中取得了27.25%的多头年化收益率,相对于同期的创业板指数取得了25.50%的超额年化收益率;hf13因子在中证1000股票池中取得了11.25%的多头年化收益率,相对于同期的中证1000指数取得了7.24%的超额年化收益率。本专题报告所述模型用量化方法通过历史数据统计、建模和测算完成,所得结论与规律在市场政策、环境变化时可能存在失效风险;
策略在市场结构及交易行为的改变时有可能存在策略失效风险。
本微信号推送内容仅供广发证券股份有限公司(下称“广发证券”)客户参考,其他的任何读者在订阅本微信号前,请自行评估接收相关推送内容的适当性,广发证券不会因订阅本微信号的行为或者收到、阅读本微信号推送内容而视相关人员为客户。
完整的投资观点应以广发证券研究所发布的完整报告为准。完整报告所载资料的来源及观点的出处皆被广发证券认为可靠,但广发证券不对其准确性或完整性做出任何保证,报告内容亦仅供参考。
在任何情况下,本微信号所推送信息或所表述的意见并不构成对任何人的投资建议。除非法律法规有明确规定,在任何情况下广发证券不对因使用本微信号的内容而引致的任何损失承担任何责任。读者不应以本微信号推送内容取代其独立判断或仅根据本微信号推送内容做出决策。
本微信号推送内容仅反映广发证券研究人员于发出完整报告当日的判断,可随时更改且不予通告。
本微信号及其推送内容的版权归广发证券所有,广发证券对本微信号及其推送内容保留一切法律权利。未经广发证券事先书面许可,任何机构或个人不得以任何形式翻版、复制、刊登、转载和引用,否则由此造成的一切不良后果及法律责任由私自翻版、复制、刊登、转载和引用者承担。











