
作为人工智能的核心基础技术,深度学习具有很强的通用性,推动人工智能进入工业大生产阶段。作为中国首个自主研发、开源开放的产业级深度学习框架和平台,截至2023年8月,飞桨汇聚了800万开发者,服务22万家企事业单位。产业级深度学习框架和平台该如何建设?百度飞桨团队带来了他们的实践和思考。以深度学习框架为核心的深度学习平台是人工智能时代技术研发必不可少的基础软件,可类比智能时代的操作系统。深度学习框架向下通过基础操作的抽象以隔离不同芯片的差异,向上通过提供简单易用的接口以支持深 度学习模型的开发、训练和部署,可极大地加速深度学 习技术的创新与应用。
作为人工智能重大共性关键技术,国家“十四五”规划纲要将深度学习框架列入前沿领域“新一代人工智能” 的重点科技攻关任务。放眼全球,人工智能领域知名研究机构和相关高科技公司也都对深度学习框架给予了极大关注。谷歌公司推出的 TensorFlow和Meta公司(原Facebook)推出了PyTorch(现已转入Linux基金会)是其中代表性产品。2016年,百度开源了深度学习框架飞桨PaddlePaddle,并于2019年发布中文名“飞桨”。时间回到2012年,深度学习技术潜力初露端倪,百度就开始在语音识别、语义表示和 OCR 文字识别等领域切入展开深度学习技术研发和应用,其深度学习框架研发始于2013 年。百度在深度学习领域领先布局,驱动力在于它看到了共性技术需求——以深层神经网络为主体的深度学习技术,在编程和计算上可以很好地进行通用技术抽象,使建设一个通用开发框架具备可行性。
接下来将从深度学习框架和平台核心的技术、生态建设、平台建设的三个关键点,以及趋势和展望四个部分,详尽介绍百度是如何进行深度学习底层框架架构和建设的。
深度学习平台适配对接底层硬件,为各类深度学习模型的开发、训练和推理部署提供全流程支撑,通用性是深度学习平台的基础要求。从面向算法研究和一般开发来讲,需要有很好的灵活性。从面向产业应用来讲, 高性能非常关键, 同时需要考虑实际应用的各种复杂环境、 严苛要求,并进一步降低门槛。以下重点介绍产业级深度学习平台所需的四个方面的核心技术,并结合国内外主流平台剖析其中的挑战和业界实践。
如何对深度学习计算进行抽象表达,并提供对应的编程开发模式和运行机制,是深度学习框架的关键且基础的功能。这也被表述为深度学习框架的开发范式,会同时影响开发体验和执行效率。根据神经网络计算图创建方式和执行机制的不同,深度学习框架开发范式有两大类。一类是以TensorFlow 1.0版本为代表的静态图开发范式,需要把神经网络模型提前定义为完整的计算图,用不同批次的数据进行训练时,计算图会被反复执行,但不再发生变化。另一类是以PyTorch为代表的动态图开发范式,用不同批次的数据进行训练时,计算图被即时创建和执行,每个批次数据所使用的计算图可以动态变化。动态图模式具有更友好的开发调试的编程体验,已经成为业内默认的主流开发范式。但也存在一些局限性,如由于缺乏静态全图表示导致难以序列化保存模型,从而难以脱离训练环境部署,并且难以进行全局性能优化等,而这些在静态图模式下是非常容易实现的。因此,理想的方式是兼顾动态图和静态图的优势。百度团队于2019年提出了“动静统一”的方案并沿着这一技术路线进行研发。“动静统一”体现为以下几方面:动态图和静态图统一的开发接口设计、底层算子实现和高阶自动微分能力、动态图到静态图执行模式的低成本转换、动转静训练加速,以及静态图模式的灵活部署。这一方案兼顾了动态图的灵活性和静态图的高效性。然而,如何支持灵活的Python语法是动转静的一大挑 战。由于缺少静态图的执行模式,PyTorch的TorchScript的转换技术,需要将Python代码转换为自定义的IR表 示,由于它所支持的Python语法低于40%,许多模型无法转换部署。而得益于完整的动态图和静态图实现,飞桨的动转静技术自动将动态图的Python 代码转换为静态图的Python代码,然后由Python解释器执行并生成静态图,可支持90%以上的Python语法,新模型的动转静直接成功率达 92%。AI for Science场景的高阶微分方程求解需求,对应着框架的高阶微分能力,对动静统一提出了进一步的挑战。国内外主流框架均在这一能力上进行了布局和探索。以飞桨为例,通过基础算子体系定义的算子拆分规则将复杂算子拆分成基础算子,通过基础算子的变换规则,进行前向自动微分和反向自动微分两种程序变换,实现高效计算高阶导数,具备通用性和可扩展性。拆分后的基础算子组成的静态计算图,通过神经网络编译器技术, 实现Pass优化、算子融合和自动代码生成。以流体力学领域常用的Laplace方程求解任务为例,基于神经网络编译器优化技术性能可提升3倍。深度学习的效果通常随着训练数据规模和模型参数规模的增加而提升。在实际产业应用中,大数据+大模型如何高效训练,是深度学习框架需要考量的重要问题。而预训练大模型的兴起,使得训练的挑战进一步加大。比如 2020 年发布的 GPT-3 模型参数量就已高达 1,750 亿, 单机已经无法训练。
大规模训练能力已经成为产业级深度学习平台竞相发力的关键方向,而这一能力的建设和成熟非常依赖真实的产业环境应用打磨。以飞桨为例,已具备完备可靠的分布式训练能力,建设了端到端自适应分布式训练架构,以及通用异构参数服务器和超大规模图学习训练等特 色技术。在深度学习模型参数规模日益增大的同时,模型特性和硬件环境也复杂多样,这使得大规模训练的技术实现和性能效果的迁移成本很高。飞桨统筹考虑硬件和算法, 提出了端到端自适应分布式训练架构(见图1)。该架构可以针对不同的深度学习算法抽象成统一的计算视图, 自动感知硬件环境并抽象成统一的异构资源视图。采用代价模型对两者进行联合建模,自动选择最优的模型切分和硬件组合方案,构建流水线进行异步高效执行。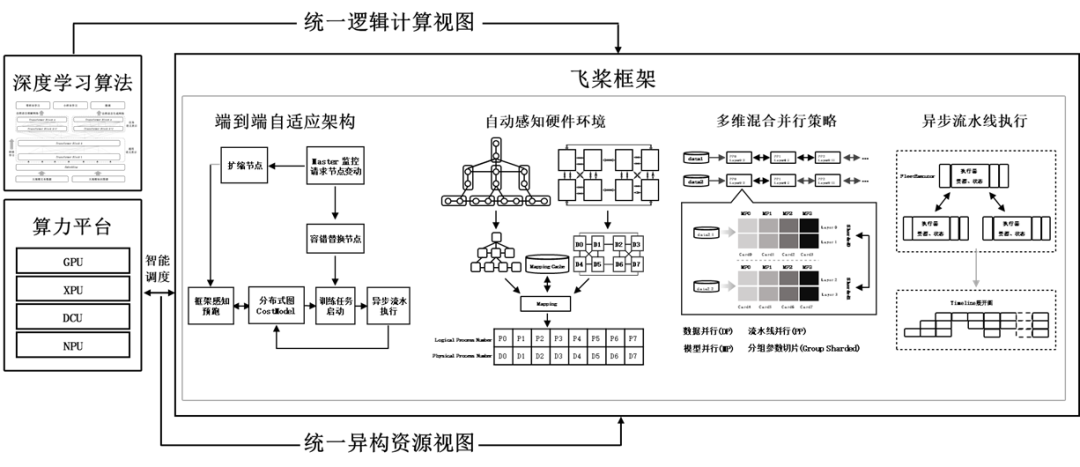 图1 端到端自适应分布式训练架构有一类特殊的深度学习大规模训练任务,广泛应用于互 联网领域的搜索、推荐等场景,不但数据量大,特征维 度极高且稀疏。这类任务的分布式训练一般采用参数服 务器技术来解决超大规模稀疏参数的分布式存储和更 新问题。但如果想对千亿、万亿规模参数的模型实现高 效支持,需要在参数服务器架构设计和计算通信策略上全面创新突破。为此,飞桨在支持万亿规模的CPU参数服务器和GPU参数服务器的基础上,于 2020年推出支持AI硬件混布调度的异构参数服务。由不同类型的计算单元负责不同性质的任务单元,可以综合利用不用硬件的优势,使整体计算成本降至最低。考虑到扩展性问题,进一步将其中的基础模块通用化,提升二次开发体验,便于产业应用中广泛定制开发。以新增支持昆仑芯 XPU 的参数服务器为例,在复用通用模块的基础上,只需增加三个硬件相关 的定制模块,就能使开发量从原来的万行减少至千行。除传统深度学习任务之外,大规模图学习正日益受到更多关注。现实世界中很多实体及关系可以通过节点和边构成的图来描述,如网页和网页链接组成的网络、路口和道路组成的交通路网等。由数百亿节点和数百亿边构成的庞大图,对算法和算力都提出了巨大挑战。结合图学习特性和计算硬件特点而推出的基于GPU 的超大规模图学习训练技术PGLBox,通过显存、内存、 SSD三级存储技术和训练框架的性能优化技术,单机可支持百亿节点、数百亿边的图采样和训练,并可通过多机扩展支持更大规模。推理部署是AI模型产业应用的关键环节,被视为AI落地的最后一公里,面临“部署场景多、芯片种类多、性 能要求高”三方面的挑战。部署场景涉及服务器端、边 缘端、移动端和网页前端,部署环境和性能要求差异巨大。芯片种类方面,既有X86/ARM不同架构的CPU芯片和通用的GPU芯片,也包括大量的AI专用XPU芯片和FPGA芯片。性能方面,因为推理直接面向应用,对服务响应时间、吞吐、功耗等都有很高的要求, 因此建设一整套完整的推理部署工具链至关重要。以下以飞桨的训推一体化工具链为例(见图2),分析如何解决推理部署的系列难题。
图1 端到端自适应分布式训练架构有一类特殊的深度学习大规模训练任务,广泛应用于互 联网领域的搜索、推荐等场景,不但数据量大,特征维 度极高且稀疏。这类任务的分布式训练一般采用参数服 务器技术来解决超大规模稀疏参数的分布式存储和更 新问题。但如果想对千亿、万亿规模参数的模型实现高 效支持,需要在参数服务器架构设计和计算通信策略上全面创新突破。为此,飞桨在支持万亿规模的CPU参数服务器和GPU参数服务器的基础上,于 2020年推出支持AI硬件混布调度的异构参数服务。由不同类型的计算单元负责不同性质的任务单元,可以综合利用不用硬件的优势,使整体计算成本降至最低。考虑到扩展性问题,进一步将其中的基础模块通用化,提升二次开发体验,便于产业应用中广泛定制开发。以新增支持昆仑芯 XPU 的参数服务器为例,在复用通用模块的基础上,只需增加三个硬件相关 的定制模块,就能使开发量从原来的万行减少至千行。除传统深度学习任务之外,大规模图学习正日益受到更多关注。现实世界中很多实体及关系可以通过节点和边构成的图来描述,如网页和网页链接组成的网络、路口和道路组成的交通路网等。由数百亿节点和数百亿边构成的庞大图,对算法和算力都提出了巨大挑战。结合图学习特性和计算硬件特点而推出的基于GPU 的超大规模图学习训练技术PGLBox,通过显存、内存、 SSD三级存储技术和训练框架的性能优化技术,单机可支持百亿节点、数百亿边的图采样和训练,并可通过多机扩展支持更大规模。推理部署是AI模型产业应用的关键环节,被视为AI落地的最后一公里,面临“部署场景多、芯片种类多、性 能要求高”三方面的挑战。部署场景涉及服务器端、边 缘端、移动端和网页前端,部署环境和性能要求差异巨大。芯片种类方面,既有X86/ARM不同架构的CPU芯片和通用的GPU芯片,也包括大量的AI专用XPU芯片和FPGA芯片。性能方面,因为推理直接面向应用,对服务响应时间、吞吐、功耗等都有很高的要求, 因此建设一整套完整的推理部署工具链至关重要。以下以飞桨的训推一体化工具链为例(见图2),分析如何解决推理部署的系列难题。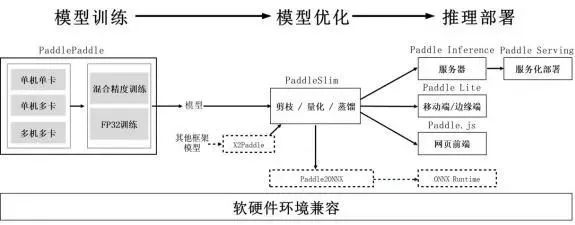 图2 飞桨训推一体化工具链针对部署场景多的问题,我们提供原生推理库及服务化部署框架、轻量化推理引擎、前端推理引擎,旨在全面解决云、边、端不同场景的部署问题。为了进一步提升推理速度,我们通过模型压缩工具PaddleSlim支持量化、稀疏化、知识蒸馏和结构搜索等模型压缩策略,并提供自动化压缩功能。通过解耦训练代码、离线量化超参搜索、算法自动组合和硬件感知,实现一键模型自动压缩,大大降低了模型压缩的使用门槛。
图2 飞桨训推一体化工具链针对部署场景多的问题,我们提供原生推理库及服务化部署框架、轻量化推理引擎、前端推理引擎,旨在全面解决云、边、端不同场景的部署问题。为了进一步提升推理速度,我们通过模型压缩工具PaddleSlim支持量化、稀疏化、知识蒸馏和结构搜索等模型压缩策略,并提供自动化压缩功能。通过解耦训练代码、离线量化超参搜索、算法自动组合和硬件感知,实现一键模型自动压缩,大大降低了模型压缩的使用门槛。
针对芯片种类多的问题,我们设计了统一硬件接入方案NNAdapter和训推一体基础架构,可支持一次训练、随处部署,满足基于广泛推理硬件的部署需求。NNAdapter支持将不同硬件的特性差异统一到一套标准化开发API上,可以实现将模型部署到已适配飞桨的所有推理硬件上。此外,支持完善的模型转换工具 X2Paddle和Paddle2ONNX,以兼容生态中不同后端和不同平台的模型表示。
针对性能要求高的问题,分别从硬件特性、算子融合、 图优化、低精度和执行调度等五个角度对不同场景进行全面优化。对于文心千亿大模型服务器端推理,得益于算子多层融合、模型并行、流水线并行、大模型量化和稀疏化压缩等多种策略。在智能手机移动端ARM CPU推理场景上,通过Cortex-A 系列处理器的硬件特性优化、计算图优化和模型全量化等多种技术,满足多样化的应用场景对性能的苛刻要求。由于推理部署所涉及的工具较多,用一个统一工具解决以上问题可进一步提升开发效率。FastDeploy AI部署工 具,通过一站式工具可进一步简化整个推理部署过程,加速AI应用落地。虽然产业级深度学习平台提供了从开发训练到推理部 署全流程的能力支持,但我们同时注意到,在实际的AI产业应用中,很多用户往往基于已有模型复用或二次开发。伴随技术的快速发展,学术界涌现了大量的算法,但开发者依然面临匹配场景需求的模型难找、模型精度和速度难平衡、推理部署应用难等共性挑战。基于此,飞桨研制了产业级模型库。目前,模型库支持算法总数超过600个。包含覆盖自然语言处理、计算机视觉、语音、推荐、时序建模、科学计算、生物计算、量子计算等领域。以计算机视觉为例,针对图像分类、检测、分割、字符识别等不同任务,发布PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR等端到端开发套件。其中,特别包含42个深度优化、精度与性能平衡的PP系列模型,以及文心系列大模型。 深度学习框架和平台生态的建设
深度学习框架和平台生态的建设
深度学习平台下接芯片,上承应用,在人工智能技术体系中处于贯通上下的腰部核心位置。也正因如此,深度学习平台必须在生态建设过程中持续迭代演进,与上下游协同构建完整的人工智能生态体系。生态建设的成效很大程度上依赖深度学习框架和平台的核心技术和功能体验。同时,生态建设本身也能加速框架和平台功能体验的优化和核心技术的创新。因此,准确把握二者关系,选择合适的时机和运营方式来建设生态至关重要。首先,深度学习平台需要广泛地跟硬件芯片适配和融合优化,作为基础设施共同支撑广泛的AI应用,因此构建基础软硬件生态是首要。企业作为人工智能应用的主体,在整个生态体系中发挥着重要作用。深度学习平台要成为企业智能化升级中的共享底座,才能更高效推动人工智能更广泛的应用落地。产业智能化升级需要大量新技术的AI人才,亟须企业与高校合作开展产教融合的人才培养。因此, 围绕高校等建设的教育生态也至关重要。同时,深度学习平台的发展离不开开源社区所搭建的环境,在与社区共创、共享中才能加速发展。
当下,人工智能呈现出显著的融合创新和降低门槛的特点。知识与深度学习的融合、跨模态融合、软硬一体融合、 AI+X 融合将会更加深入,深度学习平台将为人工智能的融合创新提供基础支撑。同时,生成式AI和大语言模型技术的快速发展,人工智能的应用门槛再度降低,将极大加速人工智能的产业落地,助力实体经济的发展,深度学习平台+大模型将在其中发挥关键作用。随着大模型和 AI for Science等技术的发展,人工智能的潜力会更大释放。通过持续技术创新突破和产品能力提升,建设更加繁荣的AI生态,产业级深度学习平台和大模型协同优化,将更好地支撑人工智能技术创新与应用,推动产业加速实现智能化升级,让AI惠及千行百业。马艳军,百度AI技术生态总经理,总体负责深度学习平台飞桨(PaddlePaddle)的产品和技术研发及生态建设,主要研究方向包括自然语言处理、深度学习等,相关成果在百度产品中广泛应用。在ACL等权威会议、期刊发表论文20余篇,多次担任顶级国际会议的Area Chair等,并曾获2015年度国家科技进步二等奖。2018年被评为“北京青年榜样 · 时代楷模”。胡晓光,百度深度学习技术平台部杰出研发架构师,有10多年的深度学习算法和框架工程研发实践经验。现负责飞桨核心框架的技术研发,设计了飞桨框架2.0全新的API体系,形成了飞桨API动静统一、高低融合的特色;牵头研制飞桨产业级开源模型库,并实现大规模产业应用;研发飞桨高阶自动微分机制,并结合编译器和分布式训练技术更高效地支持科学研究和产业应用。于佃海,百度飞桨深度学习平台总架构师,百度集团机器学习平台TOC主席,中国计算机学会(CCF)高级会员。构建了百度首个大规模分布式机器学习训练系统,最早将机器学习技术引入百度搜索排序,建设了百度最早的机器学习基础算法库和实验平台。曾获中国电子学会科技进步一等奖、北京市科学技术进步奖一等奖、CCF杰出工程师奖。文章转载自CSDN《新程序员006:人工智能新十年》关注【飞桨PaddlePaddle】公众号










