深度学习作为人工智能科研领域的一个重要分支,在多个场景中展现出惊人的能力,无论是自动驾驶汽车,还是人脸识别系统,甚至是与人对话的机器人,背后都离不开它的技术支持。
近年来,Transformer架构及其变体,如BERT、GPT和T5等,已经成为NLP领域的主流。特别是预训练模型,如BERT,通过在大量的无标签文本上进行预训练,再在特定任务上进行微调,使得模型能够充分利用海量的文本数据,从而在多种NLP任务上都取得了顶级的性能。
10月10日-10月11日,我们邀请到哈工大计算机博士Kimi老师带来——深度学习第一讲,打开NLP的大门!教大家轻松掌握深度学习的核心知识,使其真正服务于我们的创新和研究。

 文末有福利
文末有福利

深度学习200+篇论文&电子数据&数据集
-哈工大博士,获年度国际青年科学家奖提名
-担任知名科研期刊编委
-发表近20篇学术论文,且全部发表在KBS,ESWA等IF>7的中科院1区Top期刊上,或发表在ACL和EMNLP等顶会上
-多个顶会期刊如中科院一区top期刊审稿专家
-研究方向:自然语言处理,小样本,医疗文本处理、法律文本处理等
1.深度学习的本质与核心:
抓住本质才能以不变应万变,找准核心才能以四两而拨千斤
2.深度学习在NLP领域的发展脉络:
从Word2Vec到ChatGPT,梳理这10年的技术历程
3.半小时Pytorch快速实战:
实机演示如何使用Pytorch框架来训练一个深度学习模型

早期,NLP主要依赖于规则-based的方法和统计模型,如N-gram模型和隐马尔科夫模型。
接着,词嵌入技术,如Word2Vec和GloVe成为深度学习在NLP的第一波应用,它们能够将语言中的词语转化为高维空间中的向量,并捕捉到词与词之间的语义关系。
接下来,卷积神经网络(CNN)被引入到文本分类和情感分析任务中,展现出优良的性能。
近年来,Transformer架构及其变体,如BERT、GPT和T5等成为NLP领域的主流。这些模型通过自注意机制(self-attention)能够捕获文本中的长距离依赖,提供了对上下文的更为深入的理解。
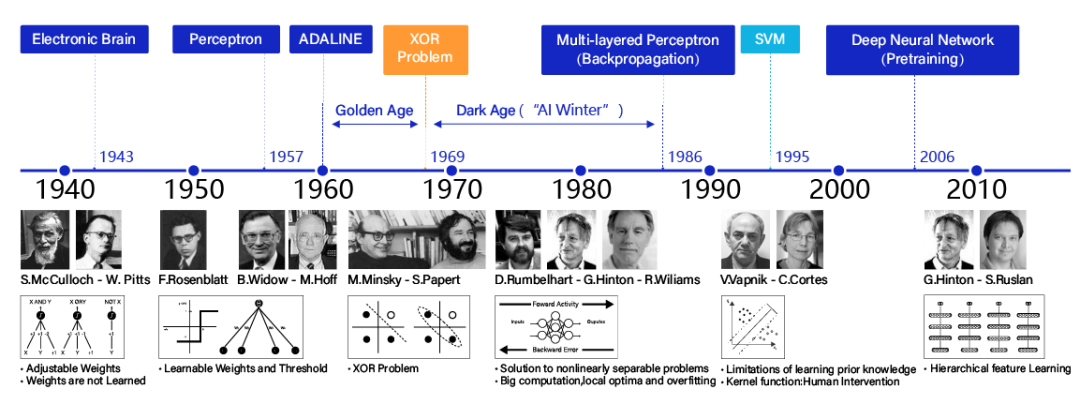
深度学习发展历程
代码完全不会,如何入门深度学习?
1.先找到自己研究领域的顶级期刊,具体怎么找到自己领域顶级期刊呢?可以使用connected papers这个网址,灰色圆圈越大的论文的对应期刊,就是你研究领域的顶刊。
2.在paper with code 上下载自己研究领域的顶刊代码,github上也可以下载到顶刊代码,需要输入自己课题的关键词。或者大量下载顶刊论文,在论文中输入github,运气好,作者就把代码挂在github上,你就可以下载到了顶刊代码了。
3.配置环境,跑通顶刊代码,大多数论文中都会把环境告诉你,你自己配就好。接着,配合着对应的论文,吃透每一行代码的意思。
4.多看看研究领域的顶级期刊,看看有没有什么模块,是可以加入到上面跑的顶刊期刊上的,加上去试试性能。也可以修改上述跑通代码的框架,这个简称(魔改),性能如果提升的话,你的创新模型就出来了。

深度学习200+篇论文&电子数据&数据集
同时向大家推荐一个1v6科研小班,由哈工大计算机博士,多个顶会审稿人Kimi老师授课——基于大模型的自然语言处理。LLMs(Large Language Models)是一种利用深度学习技术构建的人工智能模型,能够理解和生成自然语言文本。通过在大量文本数据上进行训练,LLMs可以执行各种语言任务,如问答、文本生成、翻译等。OpenAI的GPT系列模型就是大语言模型的典型代表,它们在许多自然语言处理任务中表现出色,能够与人类进行流畅的文字交流。近一年,各类中文LLMs层出不穷。ChatGLM-6B 是由智谱AI(清华) 开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。MOSS 是由复旦大学发布的一个支持中英双语和多种插件的开源对话语言模型。大数据国家实验室发布的Linly包含 Linly-Chinese-LLaMA , Linly-ChatFlow , Linly-ChatFlow-int4 四个版本。此外,基于医学知识的LLaMA微调模型HuaTuo,在医疗问答领域有着不俗的表现。甚至还有蛋白质预训练大模型ProtTrans。可以说,自然语言处理俨然已经来到了大模型的时代。
正处在时代风口的我们何不来一场大模型的论文狂欢?无论你是想二次预训练or微调LLM使其更专精于某个特定的应用场景;还是想将特定领域的知识与大模型强大的推理能力相结合,以从大模型那里得到更准确的答案;还是将大模型作为一个组件,设计一种多agent的创新方法;在这里都可以得到实现。
-哈工大计算机博士,获2023年度国际青年科学家奖提名-发表近20篇学术论文,其中包括ACL/EMNLP等-研究方向:自然语言处理,小样本,医疗文本处理、法律文本处理等 
小沃整理了沃恩智慧联合创始人Paul老师的精品系列付费课程,原价3999元,现0元免费领,包含计算机领域各方向热点内容及论文写作技巧干货!









