
期刊:Information Sciences
题目:Crime risk prediction incorporating geographical spatiotemporal
dependency into machine learning models
作者:Yue Deng, Rixing He, Yang Liu
DOI:https://doi.org/10.1016/j.ins.2023.119414
摘要:犯罪的时空分布与环境密切相关,表现出典型的“时空自相关”特征。然而,现有的基于机器学习的犯罪预测方法大多难以模拟犯罪的时空分布。在这项研究中,我们通过引入时空滞后变量来缓解犯罪数据中的时空依赖性。为了验证所提出方法的可行性,使用了四种机器学习方法来确定考虑时空依赖性是否可以提高模型预测精度,并探索各种因素的影响(即环境因素和人口学因素)使用2014年6月至2018年5月在达拉斯收集的犯罪数据对不同地区犯罪风险强度的影响。结果表明:①结合时空滞后变量可以有效提高机器学习模型的预测精度;②预测犯罪的变量在时间和空间上具有高度的非线性,基于树的非线性模型在预测犯罪方面大大优于线性模型;③可解释的机器学习模型可以揭示每个变量对研究人员和从业者的独特贡献。这些发现有助于我们了解犯罪发生的机制,并可能指导预防犯罪策略的制定。
引言:
准确预测特定场景中的犯罪风险不仅可以帮助居民选择安全的生活场所以保护他们的生命和财产,还可以使警察部门能够增加在高风险地区的巡逻,通过减少响应时间来预防和减少犯罪。图1通过显示安塞林当地莫兰I对达拉斯市连续三年抢劫案的计算结果,说明了空间和时间犯罪模式之间的隐含联系。空间自相关指数表明犯罪的发生不是随机的,而是表现出一定的空间依赖性。达拉斯的犯罪热点和冷点似乎在三年内保持相对稳定,这表明犯罪事件的时间依赖性。总体而言,无论研究的时空单位如何,犯罪事件的发生都表现出典型的时空依赖性。然而,现有的犯罪预测模型,如随机森林和极限梯度提升,是非空间的,不需要用空间参数进行标定,难以模拟犯罪时空依赖性,这在一定程度上降低了犯罪预测的准确性。
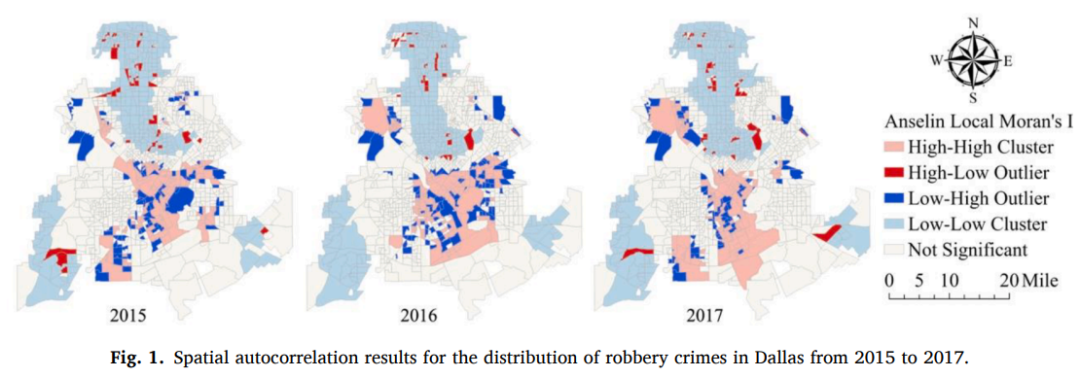
为了解决这些缺陷,我们使用时空滞后变量来检验考虑时空依赖性可能会大大提高犯罪预测准确性的假设。
相关工作回顾:
犯罪预测是犯罪学和城市安全研究中的一个难题,涉及分析和建模现有的犯罪数据和可能影响犯罪的各种相关因素(环境和人口统计),并对未来特定时间和空间的犯罪情况、结构和趋势做出判断。最常用的方法可分为以下四类:热点检测,近重复预测,基于回归,以及 机器学习。
热点检测技术是识别犯罪时空分布模式的传统而有效的策略,通常只需使用犯罪事件的地理位置即可识别犯罪的高风险区域。常用的方法包括聚类分析 、核密度估计 (KDE) 、地统计学和时空扫描统计 。热点识别策略有几个缺点。首先,对未来犯罪的预测仅假设过去热点的位置与未来热点的位置相同,而没有对犯罪热点的产生进行理论解释。其次,热点识别通常依赖于历史数据,由于犯罪发生的空间热点随时间波动,模型的准确性受到影响。
近重复预测模型描述了经验观察,即以前发生过犯罪的社区将来犯罪的可能性更高。最常用的模型包括诺克斯检验、自激点过程(SEPP)和时空流行病型余震序列(ETAS)。大多数以前的“近似重复”研究仅使用犯罪的时间,地点和类型进行预测,而没有充分考虑犯罪事件周围环境的异质性。这些方法可以确定犯罪事件在哪些空间范围和时间尺度上表现出鲜明的聚集特征,但难以详细揭示犯罪事件的发生机制和空间传播模式。
基于回归的模型的核心思想是利用自变量因子对犯罪风险进行实质性建模,以实现长期犯罪风险预测。它的缺点是该模型几乎总是假设预测变量和因变量之间存在线性关系,而忽略了犯罪数据的时空依赖性和时空非平稳性特征。
机器学习被广泛用于犯罪预测,因为它可以快速有效地处理高维数据,并且即使数据不完整,也能提供比传统的基于回归的模型更好的拟合。代表性的方法包括神经网络模型,随机森林模型和图卷积模型。尽管大多数机器学习方法在预测任务中优于其他模型,但它们通常是非空间的,不需要校准空间参数,因此很难对犯罪数据中存在的时空依赖性进行建模。相关研究得出结论,在预测任务中使用时空滞后变量作为解释变量可以有效缓解数据中存在的时空依赖性,显著提高预测结果。但是,到目前为止,尚未确定在犯罪预测任务中考虑时空依赖性是否可以产生相同的显着性能改进。
本研究的主要贡献如下:1)使用四种监督机器学习方法来证明在犯罪预测建模中有必要考虑时空依赖性。2)通过引入Shapley加性解释(SHAP)值,我们证明了每个特征对模型预测结果的重要性在空间上是不同的。研究结果为基于预测的警务工作提供了有针对性的指导。
研究方法:
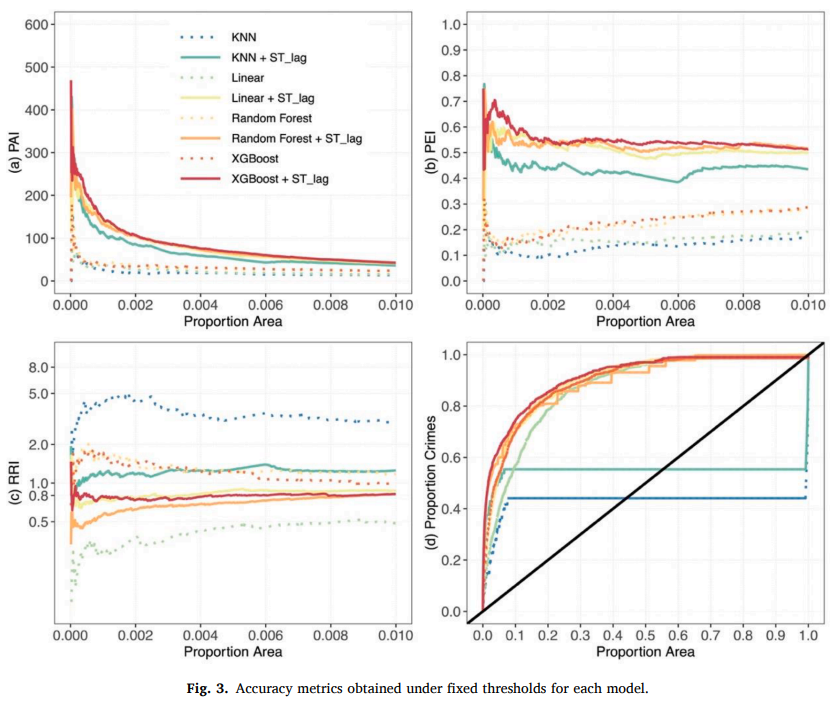
监督式机器学习可用于从一组应用于新的看不见的示例的标记训练实例中推断预测模型,而不是犯罪预测的新方法。然而,在对犯罪风险与地理空间数据之间的关系进行建模时,很少有研究考虑时空依赖性。基于上述研究背景,本研究选取了4种监督机器学习算法(线性回归、k最近邻、随机森林和极限梯度提升),以说明考虑因变量时空依赖性对犯罪预测精度的影响。此外,利用PAI、PEI RRI和ROC等各种评价指标来检验模型的预测精度。
研究数据:
数据从达拉斯开放数据门户网站(https://www.dallasopendata.com/)下载,其中包括2014年2018月至200年200月在达拉斯报告的人际抢劫信息。我们使用 240 x 481 英尺的网格单元预测了达拉斯的抢劫风险,这有助于整个研究区域的犯罪、人口和环境因素的空间相关性。总共生成了 31,32 个格网像元,用于使用达拉斯行政边界进行分析。由于微观层面的犯罪模式往往随着时间的推移表现出很强的时空稳定性,我们评估了本研究中提出的方法在年周期上的准确性,并进一步揭示了可能影响犯罪风险的重要因素,这对于以减少犯罪为导向的城市规划和警察巡逻具有重要意义。
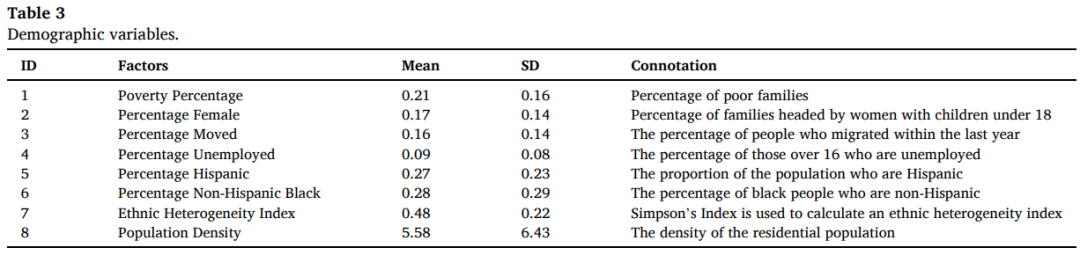
①影响犯罪风险分布的因素复杂多变。根据其属性,这些因素分为三类:环境变量、人口变量和时空滞后变量。
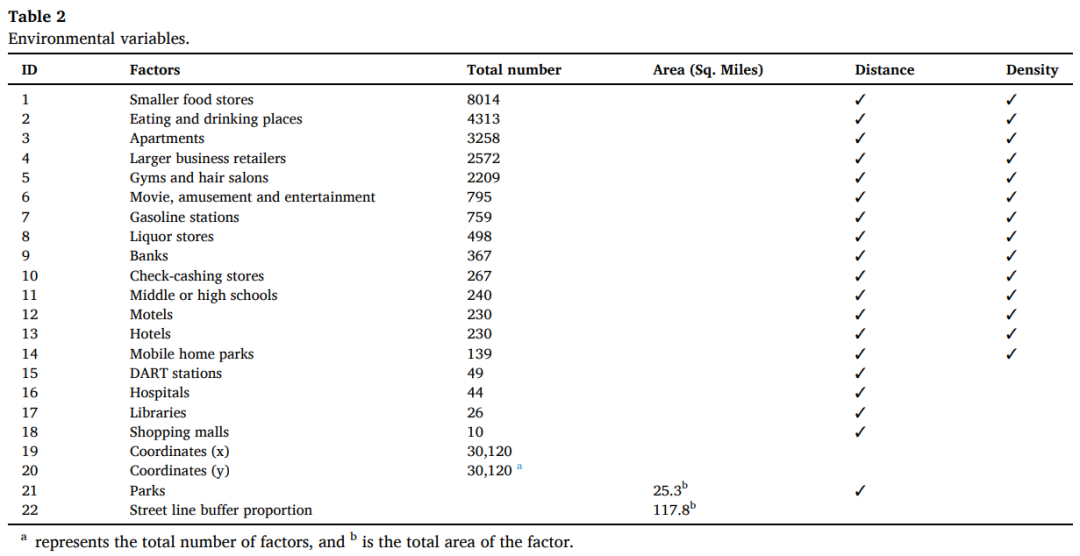
②关于犯罪的理论,如社会解体理论,表明人口因素可以在一定程度上解释城市犯罪的空间分布特征。因此,在微观犯罪预测中应充分考虑人口统计数据,以提高模型的预测能力。在区块级别估计的5年社区调查(2014年)用于计算本分析中使用的八个人口统计参数(表3)。
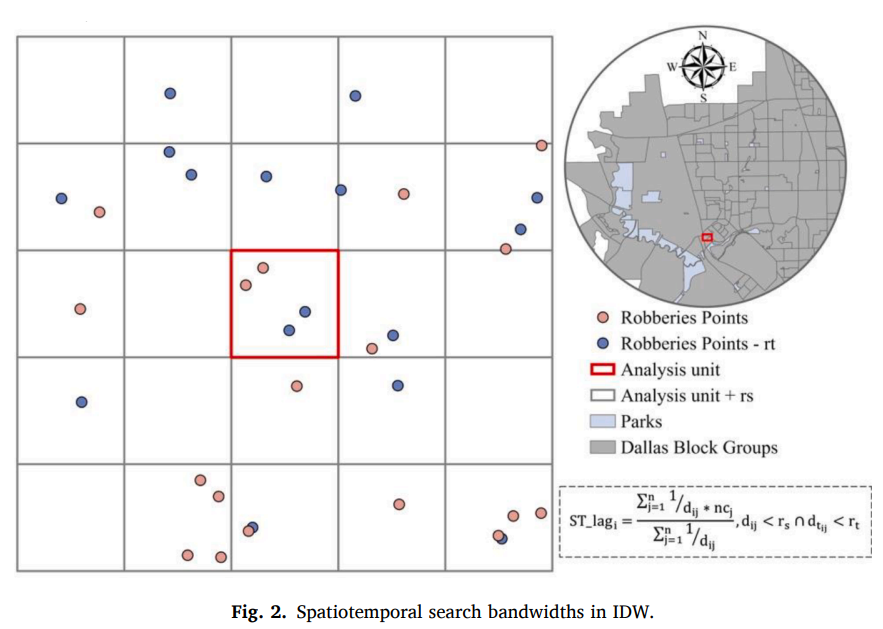
③我们在图1中观察到犯罪数据具有时空自相关,这违反了普通线性回归模型中观测值相互独立的假设,并可能影响模型的准确性.对于每个分析单元,我们想知道距离单元一定距离内的历史犯罪信息是否有助于预测下一个时期的犯罪风险。因此,我们将每个单元某个邻域内的历史犯罪数据作为解释变量包含在模型中。具体而言,如图2所示,使用24个月的时间搜索带宽和200米的空间搜索带宽,使用反距离加权(IDW)方法计算每个单元的时空滞后变量(带宽选择的基础见第6.1节。
研究结果:
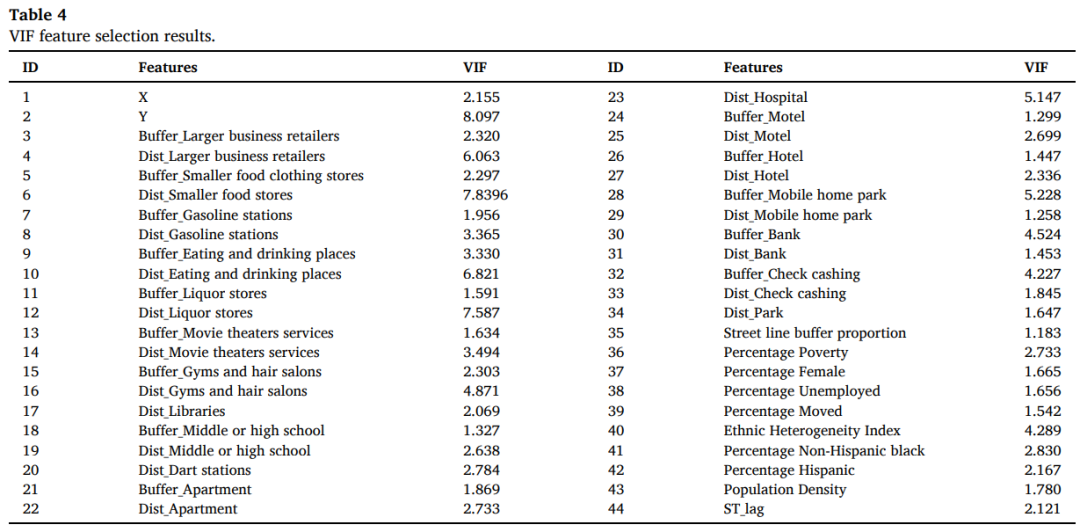
全局可解释性:
本研究利用最优XGBoost模型,通过绘制分析网格中特征的SHAP值来描述自变量对预测模型的影响。在图 4(a) 中,y 轴表示不同的独立特征,x 轴表示独立特征对模型输出的影响。当自变量和因变量呈正相关时,SHAP 值为正;当它为负时,相关性为负。SHAP 值的大小由不同的颜色表示:颜色从黄色变为紫色,表示 SHAP 值从低到高的变化。例如,图4(a)显示,小型食品店对抢劫的影响大于到公寓的距离。其他变量,如到初中或高中的距离、到医院的距离和失业百分比,对模型的影响较小
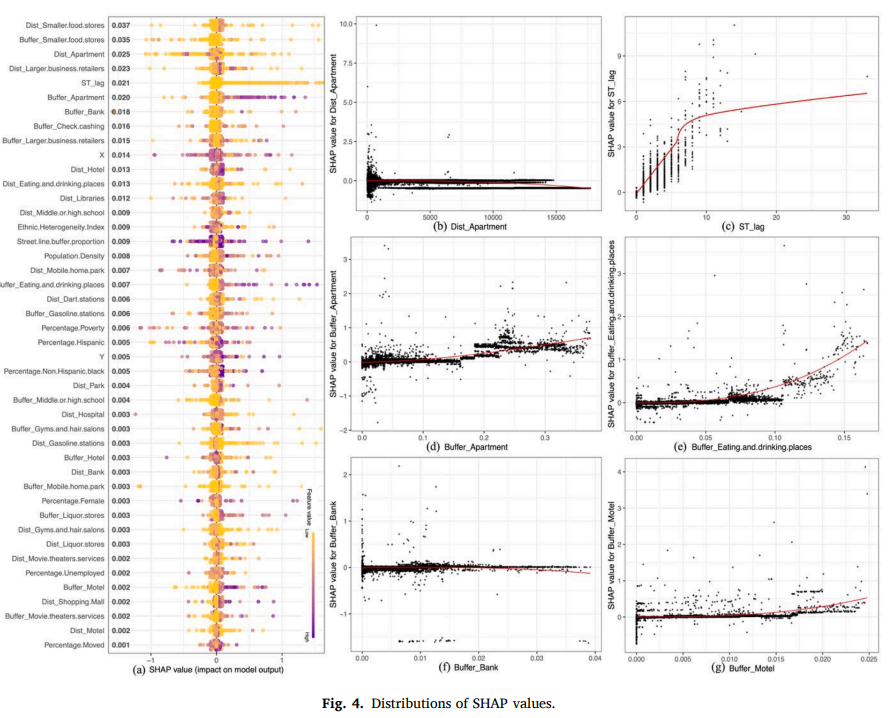
图4(b)至4(g)通过绘制特定变量和SHAP值之间的趋势,进一步显示了犯罪与变量之间的相互关系。例如,图4(b)说明了到最近公寓的距离对模型输出的影响。变量值越小,SHAP 值越高,表明它们与抢劫有关。也就是说,最靠近公寓(甚至公寓本身)的网格比其他网格更有可能发生抢劫。
图4(d)说明了公寓密度对模型输出的影响。变量值越大,SHAP值越高,表明它们与抢劫有关。也就是说,拥有更多公寓的网格比其他网格更有可能发生抢劫。图4(e)和图4(g)分别说明了饮食场所密度和汽车旅馆密度对模型输出的影响。变量的值越高,SHAP 值越高,表明饮食场所密度或汽车旅馆密度较高的格网发生抢劫的风险越高。图4(f)中银行密度和SHAP值之间的反比关系表明,较高的银行密度与较低的抢劫几率相关,这与我们的直觉相反。这表明,银行越多,安全措施越强,越不利于犯罪分子实施抢劫。此外,较高的时空滞后变量(图4(c))与较大的SHAP值相关,这意味着与抢劫呈正相关。这进一步证实了考虑时空滞后变量可以在一定程度上提高模型精度。
局部可解释性:
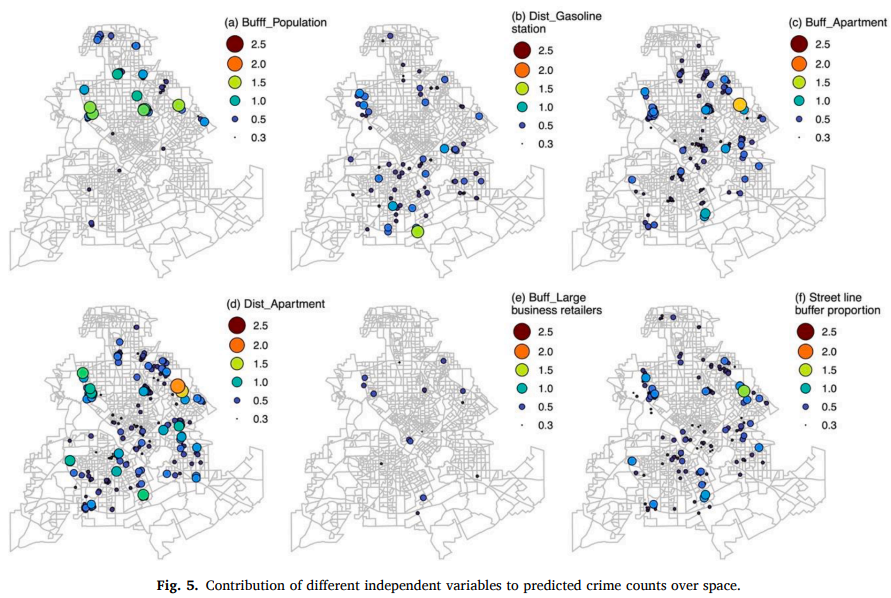
分析自变量对抢劫预测模型的空间贡献有助于解释一个地区的犯罪发生情况,可以为警方制定有针对性的犯罪预防策略提供有意义的信息。图 5 显示了几个选定变量对模型的贡献的空间变化。每个要素都具有独特的重要空间分布模式。也就是说,要素在不同区域中显示不同的犯罪预测效果。一般来说,公寓、加油站和街道等变量在预测达拉斯的犯罪方面很重要,而大型商业零售商的密度是犯罪的弱预测指标。具体而言,图5(a)表明人口密度对犯罪预测模型的贡献大部分位于北部地区。图5(b)显示,到最近加油站的距离贡献主要限于城市的南部。图5(c)和5(d)显示,公寓的密度和到最近公寓的距离是两个强有力的预测因子,它们的影响在达拉斯的所有地区都很明显。图5(e)显示,大型商业零售商密度的贡献是达拉斯犯罪的弱预测指标,值低于0.5。主要原因可能是大型商业零售商在达拉斯更加分散,因此它们的密度值较低,并且它们对犯罪预测的贡献较低。图5(f)显示,街道线缓冲比例的贡献也是达拉斯犯罪预测的强预测因子,并显示出更强的空间特征,在城市外比在城市内具有更强的影响,表明抢劫更有可能发生在街道上,郊区街道比城市中心的街道更容易发生抢劫。
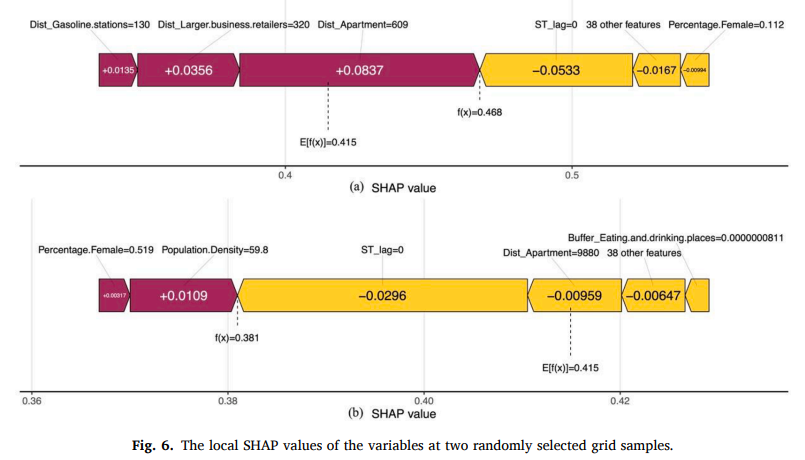
为了进一步阐明局部特征在每个网格中XGBoost模型的重要性,我们随机选择了两个网格样本进行局部可解释性分析。一般来说,样本网格的SHAP值代表了独立特征和从属特征之间存在的相关性或因果关系,因此可以指导警察部门在特定地方制定抢劫预防策略。图 6 中任意选择的两个样本的 SHAP 值表示每个单独样本的每个维度特征对模型输出的贡献。正 SHAP 值表示相应特征对模型的积极影响,而负值表示负效应。例如,在位置 6000(图 6(a)),总 SHAP 值为 0.468,大于基值 0.415。具有正 SHAP 值的特征是到最近的加油站的距离、到大型商业零售商的距离和到公寓的距离,而具有负 SHAP 值的变量包括时空滞后、女性百分比和其余特征。在位置 28,600(图 6(b)),总 SHAP 值为 0.381,小于基值 0.381。具有正 SHAP 值的特征是女性百分比和人口密度,而具有负 SHAP 值的变量是时空滞后、到最近公寓的距离和其余变量。这两个实例表明,自变量对抢劫的局部影响可能与全球模型的方向不同,并且可能因地区而异。
讨论:
在第 5.2 节中,我们观察到时空滞后变量可以提高模型精度。时空搜索带宽和空间搜索带宽是构造时空滞后变量过程中的两个重要决定性参数。因此,我们设计了一系列不同的时间搜索带宽和空间搜索带宽,并通过多次组合实验选择了最优参数。
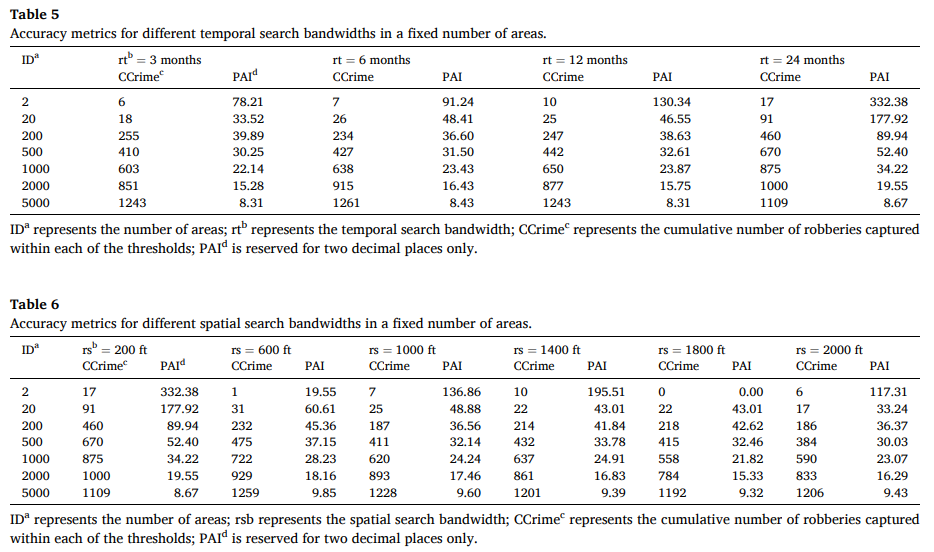
表 5 显示了当选择不同的时态搜索带宽时,模型捕获的累积犯罪数量以及固定数量的网格上犯罪预测的 PAI 值。结果表明,无论固定网格的数量如何,PAI值都随着时间搜索带宽的增加而增加。也就是说,历史犯罪数据越多,模型的预测精度就越高。这也与犯罪事件的“空间近似重复”现象相一致。
在确定最优时间研究带宽的基础上,表6进一步显示了不同空间搜索带宽(200英尺至2000英尺)下模型捕获的累计犯罪数量和固定网格中犯罪预测的PAI值。结果表明:PAI值随空间搜索半径的增加而逐渐减小,选择200英尺网格时效果最好。这意味着将解释变量的范围扩展到周围的 rid 可能会降低模型精度。总体而言,时空搜索半径对犯罪预测模型的影响证实了犯罪事件具有“时空聚合”和“近重复”现象的特征,进一步表明考虑时空滞变量可以提高犯罪风险建模的准确性。
结论:
犯罪事件严重影响居民的健康和安全。准确的犯罪预测提高了我们对犯罪发生机理的认识,可以指导公安部门合理配置资源,预防和减少犯罪。然而,传统的犯罪预测很少考虑大数据量下的时空依赖性。本研究基于引入2014—2018年达拉斯抢劫犯罪记录时空滞后变量,采用LR、KNN、RF和XGBoost四种机器学习方法对犯罪进行长时间序列的预测,以评估考虑时空依赖性是否可以显著提高犯罪预测的准确性。结果表明,时空滞后变量的加入在一定程度上缓解了模型的时空依赖性,提高了模型的精度。此外,与KNN和线性回归等模型相比,基于RF和XGBoost等决策树的集成机器学习在犯罪风险建模方面的性能相对较好且准确。这项研究的另一个贡献是引入了SHAP值,以提供犯罪风险预测模型中变量的可解释性。例如,小型食品店、公寓和时滞变量是影响研究区域抢劫案的三个重要因素。此外,本地SHAP值揭示了每个网格内的局部微环境,这些信息可能为寻找潜在的犯罪风险点提供线索,以指导警察部门制定数据驱动的犯罪预测策略或为未来安全城市的建设提供信息。
此外,还有一些问题需要进一步研究。首先,在这项研究中,我们使用了基于网格的方法,不同类型的分析单元(例如,路段)可能会产生更准确的结果。因此,在未来的工作中,将引入街道段来生成预测犯罪的模型。其次,与大多数犯罪预测研究一样,这项研究只关注导致犯罪的环境空间变量,而忽略了人类活动对犯罪风险的影响。在未来的研究中,可以通过引入人类行为的大数据来提高犯罪预测的准确性,例如手机数据和轨迹数据。第三,该模型仅在达拉斯进行了测试。即使它在这种数据设置中具有很高的准确性,也需要更多的研究来确定它是否可用于检测不同地区的其他类型的犯罪。
总之,我们的目标是开发一个有用的犯罪预测模型,并通过引入时空滞后变量来提高犯罪预测的准确性。我们的研究还为达拉斯的犯罪风险预测提供了见解。此外,我们还为其他时空预测问题提供了有用的想法。
注:以上内容仅代表个人阅读与理解,详情请见原文。欢迎转载、转发本公众号发布的内容(请注明来源并添加公众号名片)。本人水平有限,难免出错。请各位同行监督、批评与指正。








