 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 谢年年、王二狗
有了ChatGPT、GPT4之后,我们的工作学习效率得到大大提升(特别在凑字数方面୧(๑•̀◡•́๑)૭)。
作为一个工具,有人觉得好用,自然也有人觉得难用。
要把大模型用得6,必须得研究一下prompt使用技巧,但有时候绞尽脑汁想的prompt却无法获得理想的输出结果。一个好的prompt的重要性不言而喻,怪不得Prompt工程师这个新兴职业的年薪已经达到了二三十万美元。
但对于大部分公司来说,prompt工程师是请不起的,怎么办呢?
这里有一个省钱小技巧,让你从小白秒变大佬级Prompt工程师!
加州大学团队提出了可以自动优化Prompt的框架——PromptAgent,结合大模型的自我反思特点与蒙特卡洛树搜索规划算法,自动迭代检查Prompt,发现不足,并根据反馈对其进行改进,寻找通往最优Prompt的路径,可以将平平无奇的初始Prompt打造成媲美人类专家手工设计的Prompt。
论文:
论文链接:
https://arxiv.org/pdf/2310.16427.pdf
先看一下例子感受一下有多厉害。
假设我们想要实现生物医学领域的命名实体识别任务,从句子中提取疾病等实体。
prompt可能就设置为:
从句子中提取疾病或状况
这样简单粗暴的prompt虽然也能完成部分简单任务,但是效果并不好。
PromptAgent能够通过该prompt所获得的结果指出错误并不断优化prompt:
您的任务是提取疾病或疾病情况...请避免包含任何相关元素,如遗传模式(如常染色体显性)、基因或基因座(如PAH)、蛋白质或生物途径。...考虑具体的疾病和更广泛的类别,并记住疾病和情况也可以以常见的缩写或变体形式出现。以以下格式提供识别出的疾病或情况:{entity_1,entity_2,....}。...请注意,“locus”一词应被识别为基因组位置,而不是疾病名称。
 ▲优化示例
▲优化示例可以看到,最终的这份Prompt涵盖了丰富的生物领域知识,且准确率得到了极大提升。简直就是菜鸟秒变大佬!
让我们来看看具体是怎么做的吧!
方法
PromptAgent框架设计
PromptAgent在确保对广阔的prompt空间进行高效策略性的搜索的同时,有效地将专家知识整合到任务prompt中。所谓专家知识通过大模型如GPT-4生成,而其搜索策略使用的是著名的蒙特卡洛树搜索。整体框架如图3所示:
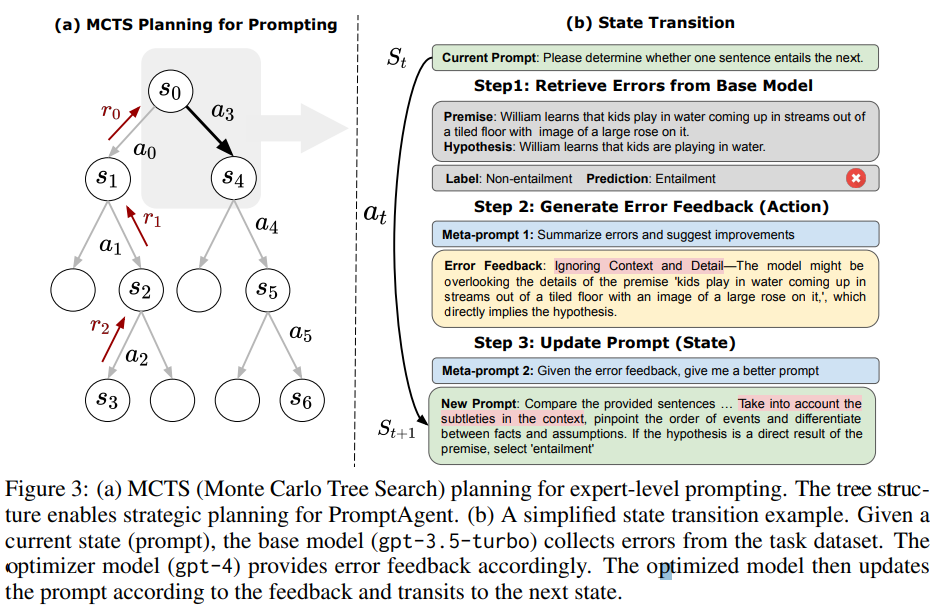
本文将任务prompt定义为状态,而对prompt的修改过程定义为执行动作。如图3(b)所示:
- 给定当前状态(也就是初始prompt),基本模型(gpt-3.5-turbo)从任务数据集获得初始输出,初始输出往往不如人意,需要进一步优化。
- 使用优化器模型(gpt-4)提供错误反馈并给出改进建议。
- 优化后的模型根据反馈更新prompt并过渡到下一个状态。
如此循环往复,最终导向专家级prompt。
策略优化过程
上述对prompt优化的过程可以无缝地将PromptAgent与主要的规划算法特别是蒙特卡洛树搜索(MCTS)相结合。从而产生最具普适性的专家级Prompt。
蒙特卡洛树搜索(MCTS)通过逐步构建树状结构来实现策略搜索,如图3(a)所示,其中每个节点表示一个状态,每条边表示状态转移的动作。MCTS执行选择、扩展、模拟和反向传播四步走来迭代搜索。迭代过程在达到预定义的迭代次数后结束,选择最高回报的路径作为最终的Prompt。
选择:在每层选择最有前途的节点进行进一步的扩展和探索。在每次迭代中,它从根节点开始,遍历每树的每一层,选择每层的后续子节点,并在叶节点处停止。在选择每层的子节点时,利用了上界置信树算法(UCT),帮助在"选择最有希望的路径"和"探索新路径"之间找到一个好的平衡。具体如下所示: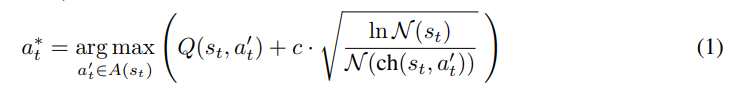
其中表示在状态执行动作时的有可能获得的回报,表示节点的动作集合,表示节点的访问次数,表示在应用动作到节点后得到的子节点,是一个用于调整探索的常数。
公式中第一项用于衡量路径的价值,而第二项衡量被访问节点的不确定性。换句话说,如果一个节点被探索得较少且其子节点也较少被访问过,那么第二项的值会较高。
扩展:在前一步选择到达的叶节点下面添加新的子节点来扩展树结构。通过多次应用动作生成和状态转换(图3(b))来完成的,从而产生多个新的动作和状态。需要注意的是,本文采样了多个训练批次得到多样化的错误反馈(动作)。在新的节点中,选择最高回报的节点作为下一个模拟步骤的输入。
模拟:模拟扩展阶段所选节点的未来轨迹,并计算如果选择该路径可能得到的回报。模拟策略的选择很灵活,比如选择随机移动直到达到终止状态。为了减少模拟的计算成本并简化过程,本文选择不断生成多个动作,并选择其中回报最高的节点,以快速进入下一个树级别。
反向传播:在模拟过程中遇到终止状态时,将进行反向传播。终止状态由预设的最大深度或提前停止条件决定。此时,通过更新Q值函数,沿着从根节点到终止节点的路径反向传播计算未来的回报。对于次条路径中的每个状态-动作对,聚合从状态开始的所有未来轨迹的回报来更新,更新方式如下:
 这里M表示从状态开始的未来轨迹的数量,和分别表示从状态和动作开始的第个状态序列和动作序列。
这里M表示从状态开始的未来轨迹的数量,和分别表示从状态和动作开始的第个状态序列和动作序列。
PromptAgent使用预设的迭代次数执行上述四个操作,当达到迭代次数后,选择具有最高回报的最佳路径中的最佳节点(即Prompt)进行最终评估。
实验
实验设置
为了全面评估PromptAgent对各种应用的影响,作者从三个不同领域精选了12个任务进行深入实验:
- 6个BIG-Bench Hard (BBH)任务,强调领域知识(如几何形状和因果判断)和复杂推理能力(如桌上的企鹅、物体计数、认识论推理和时间序列)。
- 3个生物医学领域特定任务:疾病命名实体识别(NER)、生物医学句子相似性任务(Biosses)和医学问答任务(Med QA)。
- 3个著名的自然语言理解任务,包括两个文本分类任务(TREC和Subj)和一个自然语言推理任务(CB)。
实验结果与分析
整体效果
表1显示PromptAgent在BBH任务上明显优于所有基线。相对人类Prompt(ZS)、CoT和APE方法分别提升了28.9%、9.5%和11.2%。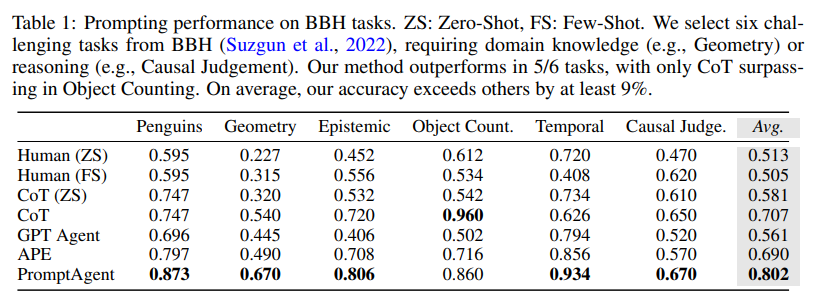
对于需要广泛的领域知识和深厚的LLM Prompt工程经验的生物领域任务,人类Prompt和CoTPrompt效果不佳。而APE通过自动Prompt抽样和优化融入了一些领域知识,减少了人工干预,效果有所提升。但是,PromptAgent相对于APE平均提高了7.3%,这表明PromptAgent可以更好地引导有效的领域知识,产生专家级Prompt,并弥合新手和专家Prompt工程师之间的知识差距。
而对于通用的NLU任务,PromptAgent的能力和通用性也完胜所有的基线。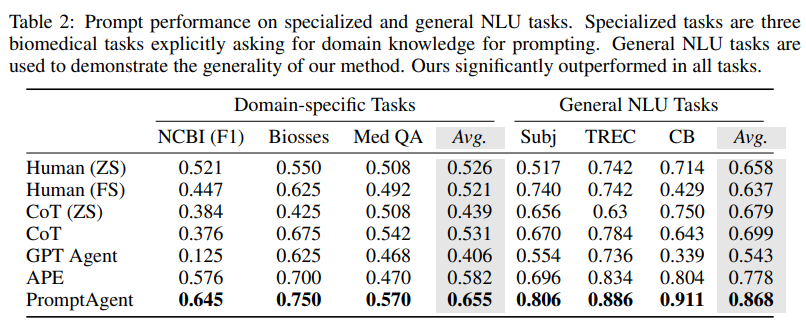
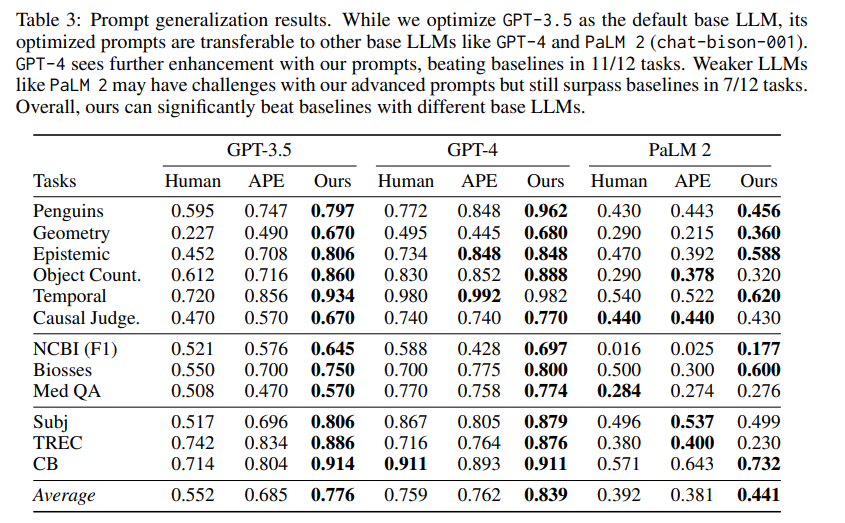
Prompt泛化性
作者还对经过PromptAgent优化后的Prompt能否推广到其他基础LLM模型上展开评估。由于较低级别和较小规模的LLM模型(如GPT-2或LLaMA)可能无法熟练掌握这些专家级Prompt的微妙之处,会导致显著的性能下降。本次评估选取了一个性能更强大(GPT-4)和一个比GPT-3.5性能更弱的模型(PaLM 2)。结果显示PromptAgent具有巨大的潜力:
当使用更强大的GPT-4时,优化后的专家Prompt几乎在所有任务(11/12)中都取得了进一步改进。
将专家Prompt转移到PaLM 2时,性能可能不如更强大的模型,但仍然可以在某些任务(如Penguins)中获得提升。
消融实验
本文还对比了多种搜索策略的效果,包括每次随机抽样并选择一个动作的单次蒙特卡洛(MC)搜索、始终选择多个样本中的最佳样本的贪婪深度优先搜索(Greedy)和在每个层级保留多个有用路径的束搜索(Beam search)。表格4显示:
贪婪搜索(Greedy)和束搜索(Beam)都极大地改进了MC基线,表明结构化的迭代探索是必要的。
Beam和Greedy严格按照前进的方向操作,没有在Prompt空间中进行策略性搜索,缺乏预见未来结果和回溯过去决策的能力。相比之下,MCTS的策略规划允许PromptAgent更有效地遍历复杂的专家Prompt空间,在所有任务上明显优于所有搜索变体。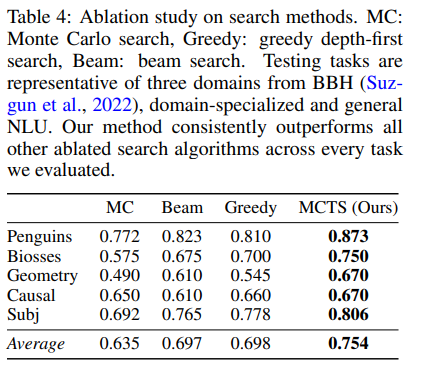
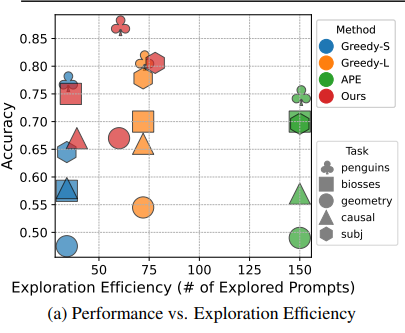
搜索效率分析
除了卓越的性能外,PromptAgent的一个关键优势是通过策略规划能够高效地搜索。搜索效率是通过搜索过程中Prompt数量来衡量的,即在搜索过程中生成的节点数。图4a中绘制了搜索效率与任务性能的关系,可以看到,PromptAgent的数据点聚集在左上角,表明在更高的准确性下,搜索的节点数也较少。
结论
本文介绍了PromptAgent,一种新颖的Prompt优化框架,结合LLMs的自我反思能力将任务的领域特定知识纳入到新生成的Prompt中,并使用MCTS规划的能力高效遍历复杂的Prompt空间找到专家级Prompt,PromptAgent优化后Prompt也始终表现出专家级的特征,丰富了领域特定的细节和指导。
在未来势必会出现越来越强大的大语言模型,能理解并支持的复杂指令越来越多,仅依赖人工专家Prompt是远远不够的,自动构建专家级Prompt将是一个非常有潜力的方向。














