我们充分调研了业内其他厂商的实现,发现有着强社交属性的公司基本上都有一个自研的图存储系统:

Facebook 实现了一个叫做 “TAO” 专门的分布式社交图谱数据库,并将其作为最核心的存储系统;Pinterest 和 Facebook 类似,也实现了类似的图存储系统;字节跳动自研了 ByteGraph 并将其用于存储核心的社交图谱数据;Linkedln 在 KV 之上构建了社交图谱服务。
考虑到当时我们的社交图谱数据已经存放在 MySQL 数据库上且规模巨大,而社交图谱数据服务是非常重要的服务,对稳定性的要求非常高。回溯 Facebook 当年遇到的问题和我们类似,数据存储在 Memcache 和 MySQL 中。因此,参考 Facebook 的 Tao 图存储系统更贴合我们的实际情况和已有的技术架构,风险更小。
社交图谱的访问主要是边的关系查询。我们的图模型将关系表示为一个 对,其中 key 是 ( FromId, AssocType, ToId ) 的三元组,value 是属性的 JSON 格式。比如“用户 A ”关注“用户 B ”,映射到 REDtao 的数据存储结构为:
<FromId:用户A的ID, AssocType:关注, ToId:用户B的
ID> -> Value (属性的json字段)
我们对业务方的需求进行分析,封装了 25 个图语义的 API 给业务方使用,满足了其增删改查的需求,并收敛业务方的使用方式。相比于 Facebook 的 Tao,我们还补充了社交图谱所需要的图语义,为反作弊场景提供了额外的过滤参数。同时,在缓存层面,我们支持对不同的字段在缓存中配置局部二级索引。下面给一些典型的使用场景:
获取关注了 A 的所有正常用户(并且剔除作弊用户)
getAssocs(“被关注类型”, 用户A的ID, 分页偏移量, 最大返回值, 只返回正常用户,是否按照时间从新到旧)
获取 A 的粉丝个数(并且剔除作弊用户)
getAssocCount(“被关注类型”, 用户A的ID, 只返回正常用户)
REDtao 的架构设计考虑了下面这几个关键的要素:

整体架构分为三层:接入层、缓存层和持久层。业务方通过 REDtao SDK 接入服务。如下图:
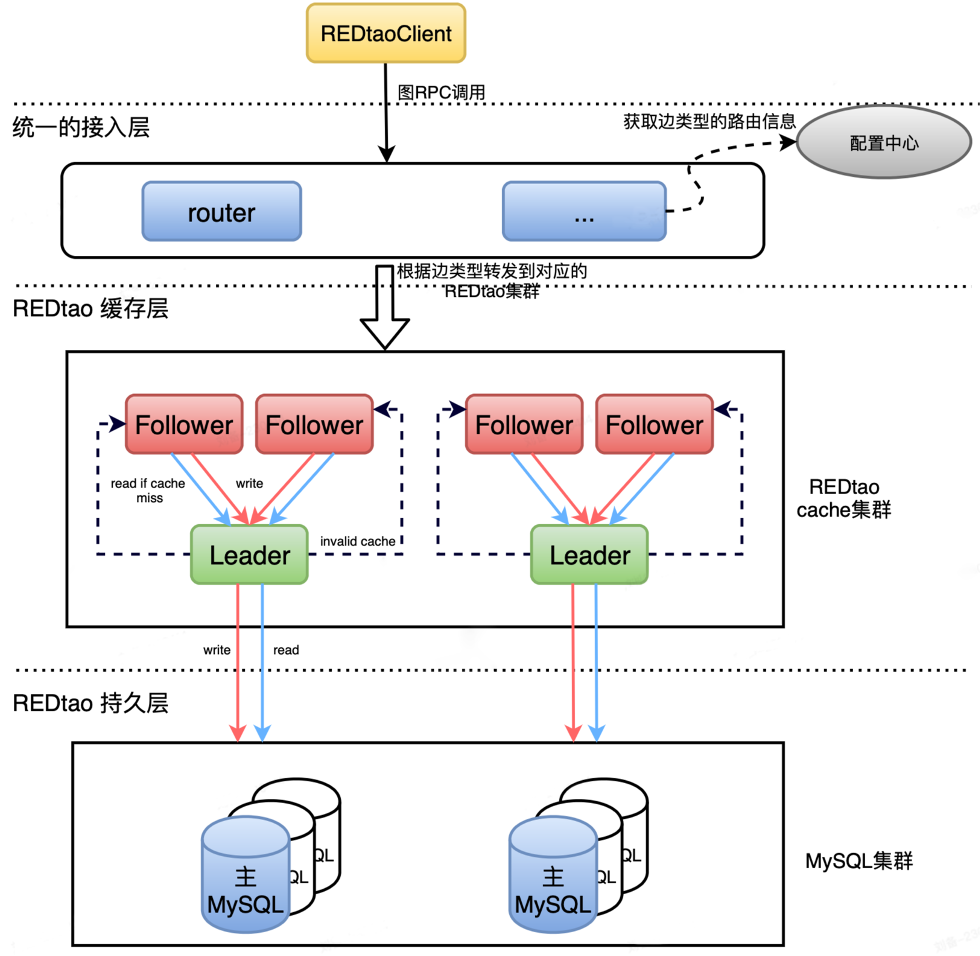
在这个架构中,和 Facebook Tao 不一样的是,我们的缓存层是一个独立的分布式集群,和下面的持久层是解耦的。缓存层和下面的持久层可以独立的扩容缩容,缓存分片和 MySQL 分片不需要一一对应,这样带来了更好的灵活性,MySQL 集群也变成了一个可以插拔替换的持久存储。
读流程:客户端将读请求发送给 router,router 接收到 RPC 请求后,根据边类型选择对应的 REDtao 集群,根据三元组 ( FromId, AssocType, ToId ) 通过一致性 Hash 计算出分片所在的 Follower 节点,将请求转发到该节点上。Follower 节点接收到该请求,首先查询本地的图缓存,如果命中则直接返回结果。如果没有命中,则将请求转发给 Leader 节点。同样的,Leader 节点如果命中则返回,如果不命中则查询底层 MySQL 数据库。
写流程:客户端将写请求发送给 router,和读流程一样,会转发到对应的 Follower 节点上。Follower 节点会转发写请求给 Leader 节点,Leader 节点转发给 MySQL,当 MySQL 返回写入成功后,Leader 会清除本地图缓存对应的 Key,并同步给其他所有 Follower 清除掉该 Key,保证数据的最终一致性。
REDtao 分为独立的两层:缓存层和持久层。每一层都保证高可用性。
自研的分布式缓存:
我们自研了实现图语义的分布式 cache 集群,支持故障自动检测和恢复、水平扩缩容。
它是一个双层 cache,每个分片都有一个 Leader 和若干个 Follower。所有的请求都先发给外层的 Follower,再由 Follower 转发给 Leader。这样的好处是读压力大的时候只需要水平扩展 Follower,单点 Leader 写入的方式也降低了复杂度,更容易实现数据的一致性。
如果一个副本故障,系统会在秒级别内进行切换。当持久层发生故障时,分布式缓存层仍然可以对外提供读取服务。
高可用的MySQL集群:
MySQL 集群通过自研的中间件实现了分库分表方案,并支持 MySQL 的水平扩容。每个 MySQL 数据库有若干从库,并且与公司内部其他的 MySQL 运维方案一致,保证高可用性。
限流保护功能:
为防止缓存击穿导致 MySQL 突发大量请求,从而导致 MySQL 宕机,我们通过限制每个主节点最大 MySQL 并发请求数来实现限流保护 MySQL。达到最大并发请求限制之后的请求会被挂起等待,直到已有请求被处理返回,或者达到等待超时请求被拒绝不会被继续请求到 MySQL 。限流阈值在线可调,根据 MySQL 集群规模调整对应限制。
为防止爬虫或者作弊用户频繁刷同一条数据,我们利用 REDtaoQueue 顺序执行对写入或者点查同一条边的请求,队列长度会被限制,控制同一时间大量相同的请求执行。相比于单个全局的队列控制所有请求的方式,基于每个请求的队列可以很好地限制单个同一请求,而不影响其他正常请求。
数据结构的设计是 REDtao 高性能的重要保证。我们采用了三层嵌套 HashTable 的设计, 通过根据某个起点 from_id 从第一级 HashTable 中查找到 REDtaoGraph,记录了所有 type 下对应的所有的出边信息。接着,在第二级 HashTable 中,根据某个 type_id 查找到 AssocType 对应某个 type 下边所有出边的计数、索引以及其他元数据。最终在最后一级 HashTable ,通过 AssocType 的某个 to_id 查找到最终边信息。我们记录了创建时间、更新时间、版本、数据以及 REDtaoQueue,time_index 则对应根据创建时间排序列表。最后一级 HashTable 以及索引限制存储最新的 1000 个边信息,以限制超级点占据过多内存,同时集中提高最新热数据的查询命中率以及效率。REDtaoQueue 用于排队当前某个关系的读写,只记录了当前最后一个请求的元数据。每次查询或写入时,首先查询 REDtaoAssoc,若缓存不存在,则会首先创建只包含 REDtaoQueue 的对象;若缓存已存在,则会更新队列元数据,将自己设置为队列的最后一个请求,并挂起等待被执行。
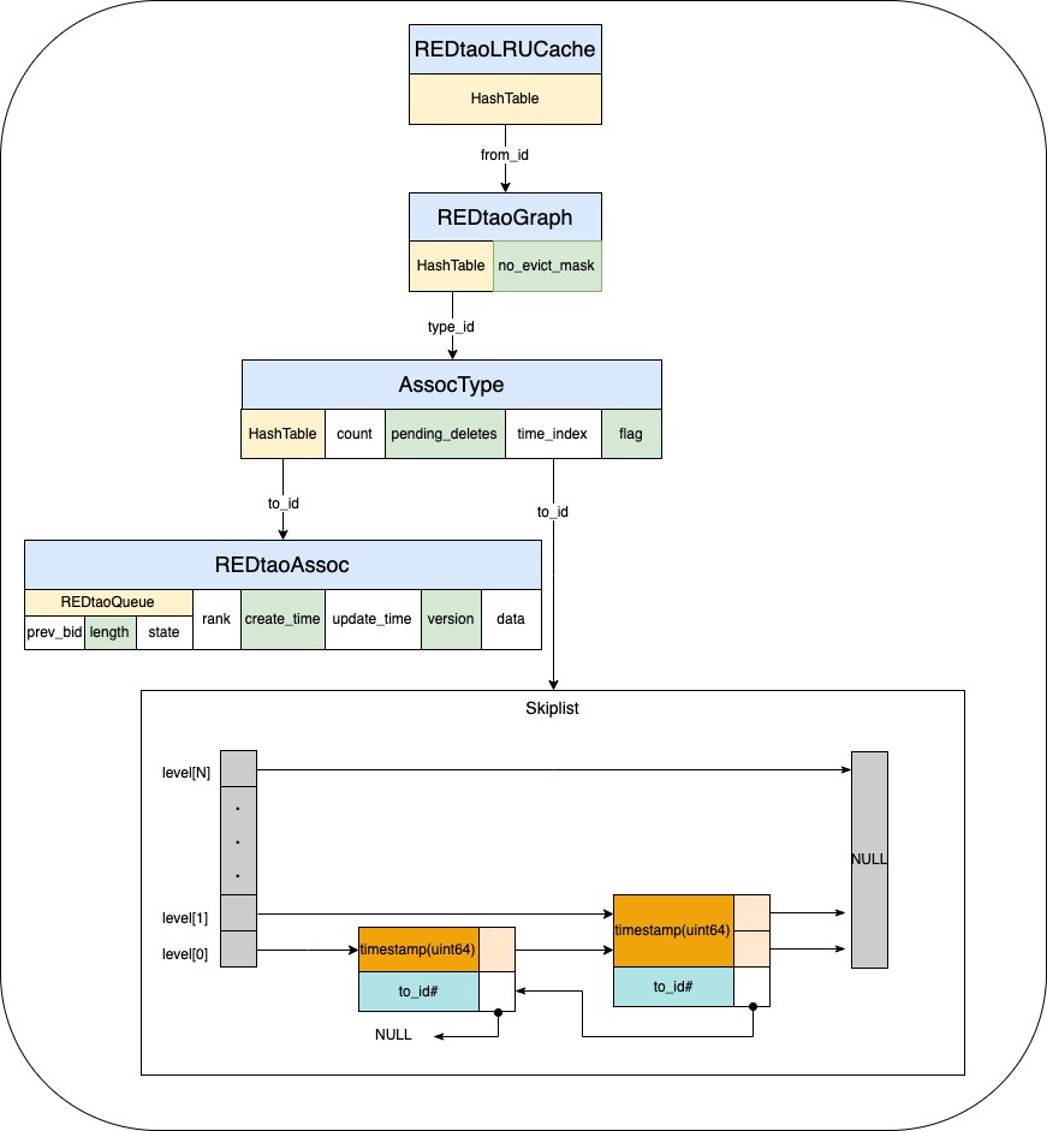
通过这种多层 hash+ 跳表的设计,我们能高效地组织点、边、索引、时间序链表之间的关系。内存的申请、释放在同一个线程上完成。
在线上环境中,我们的系统可以在一台 16 核的云厂商虚拟机上跑到 150w 查询请求/s,同时 CPU 利用率仅有 22.5% 。下方是线上集群的一个监控图,单机的 QPS 到达 3w ,每个 RPC 请求聚合了 50 个查询。



丰富的图语义 API :
我们在 REDtao 中封装了 25 个图语义的 API 给业务方使用,满足了业务方的增删改查的需求。业务方无需自行编写 SQL 语句即可实现相应操作,使用方式更加简单和收敛。
统一的访问 URL :
由于社区后端数据太大,我们按照不同的服务和优先级拆分成了几个 REDtao 集群。为了让业务方不感知后端的集群拆分逻辑,我们实现了统一的接入层。不同的业务方只需使用同一个服务 URL ,通过 SDK 将请求发送到接入层。接入层会接收到不同业务方的图语义的请求,并根据边的类型路由到不同的 REDtao 集群。它通过订阅配置中心,能够实时感知到边的路由关系,从而实现统一的访问 URL,方便业务方使用。
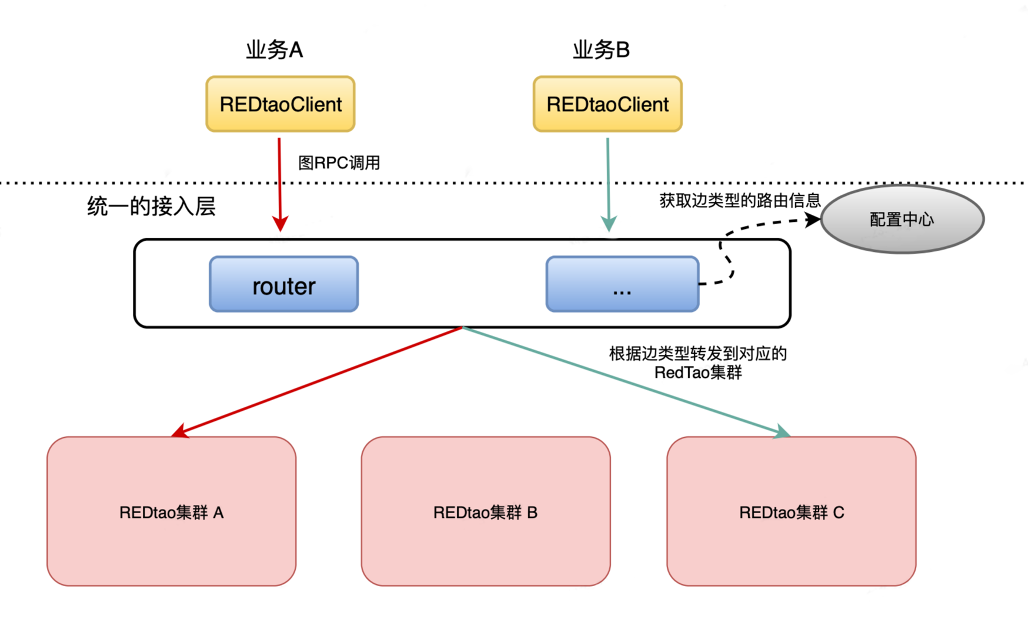
作为社交图谱数据,数据的一致性至关重要。我们需要严格保证数据的最终一致性以及一定场景下的强一致性。为此,我们采取了以下措施:
缓存更新冲突的解决:
REDtao 为每个写入请求生成一个全局递增的唯一版本号。在使用 MySQL 数据更新本地缓存时,需要比较版本号,如果版本号比缓存的数据版本低,则会拒绝此更新请求,以避免冲突。
写后读的一致性:
Proxy 会将同一个 fromId 的点或边请求路由到同一个读 cache 节点上,以保证读取数据一致性。
主节点异常场景:
Leader 节点收到更新请求后,会将更新请求变为 invalidate cache 请求异步的发送给其他 follower,以保证 follower 上的数据最终一致。在异常情况下,如果 Leader 发送的队列已满导致 invalidate cache 请求丢失,那么会将其他的 follower cache 全部清除掉。如果 Leader 故障,新选举的 Leader 也会通知其他 follower 将 cache 清除。此外,Leader 会对访问 MySQL 的请求进行限流,从而保证即使个别分片的cache被清除掉也不会将 MySQL 打崩。
少量强一致的请求:
由于 MySQL 的从库也提供读服务,对于少量要求强一致的读请求,客户端可以将请求染上特殊标志,REDtao 会透传该标志,数据库 Proxy 层会根据该标志将读请求转发到 MySQL 主库上,从而保证数据的强一致。
跨云多活是公司的重要战略,也是 REDtao 支持的一个重要特性。REDtao 的跨云多活架构整体如下:

这里不同于 Facebook Tao 的跨云多活实现,Facebook Tao 的跨云多活实现如下图:
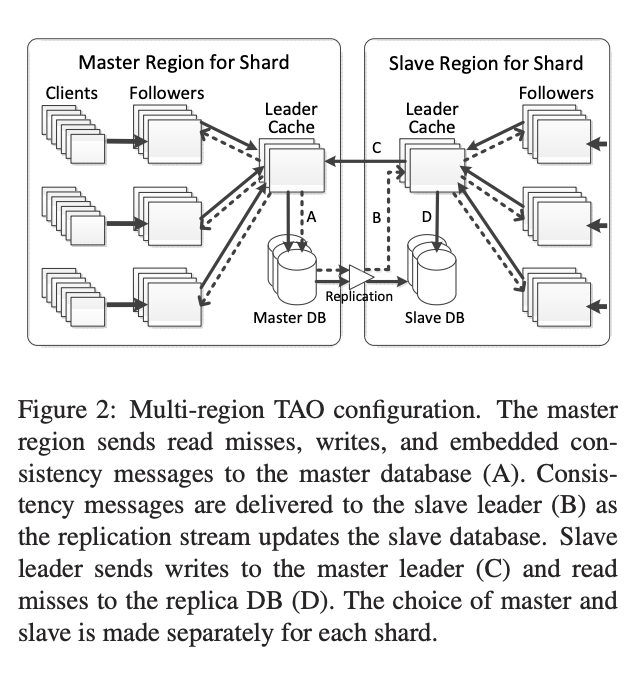
Facebook 的方案依赖于底层的 MySQL 的主从复制都通过 DTS Replication 来做。而 MySQL 原生的主从复制是自身功能,DTS 服务并不包含 MySQL 的主从复制。该方案需要对 MySQL 和 DTS 做一定的改造。前面说到,我们的缓存和持久层是解藕的,在架构上不一样。
因此,REDtao 的跨云多活架构是我们结合自身场景下的设计,它在不改动现有 MySQL 功能的前提下实现了跨云多活功能:
1)持久层我们通过 MySQL 原生的主从 binlog 同步将数据复制到其他云的从库上。其他云上的写请求和少量要求强一致读将被转发到主库上。正常的读请求将读取本区的 MySQL 数据库,满足读请求对时延的要求。
2)
缓存层的数据一致性是通过 MySQL DTS 订阅服务实现的,将 binlog 转换为 invalidate cache 请求,以清理掉本区 REDtao cache 层的 stale 数据。由于读请求会随机读取本区的任何一个 MySQL 数据库,因此 DTS 订阅使用了一个延迟订阅的功能,保证从 binlog 同步最慢的节点中读取日志,避免 DTS 的 invalidate cache 请求和本区 read cache miss 的请求发生冲突从而导致数据不一致。
REDtao 的云原生特性重点体现在弹性伸缩、支持多 AZ 和 Region 数据分布、产品可以实现在不同的云厂商间迁移等几个方面。REDtao 在设计之初就考虑到支持弹性扩缩容、故障自动检测及恢复。
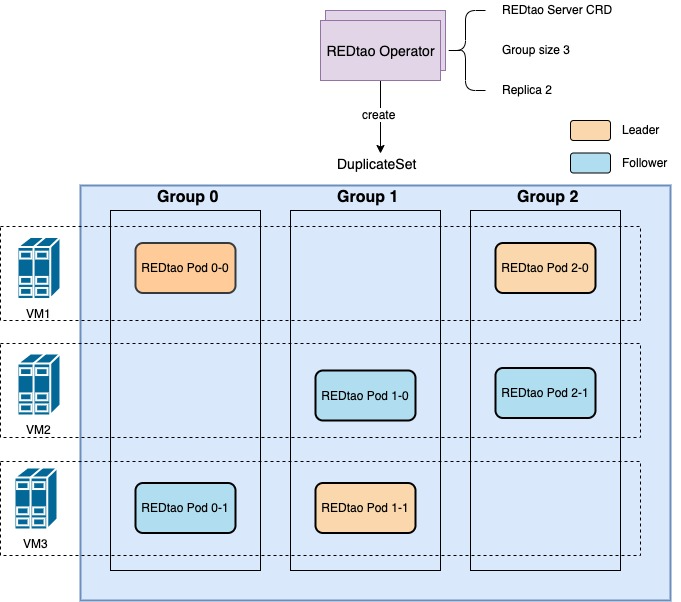
随着 Kubernetes 云原生技术越来越成熟,我们也在思考如何利用 k8s 的能力将部署和虚拟机解绑,进一步云原生化,方便在不同的云厂商之间部署和迁移。REDtao 实现了一个运行在 Kubernetes 集群上的 Operator,以实现更快的部署、扩容和坏机替换。为了让 k8s 能感知集群分片的分配并且控制同一分片下的 Pods 调度在不同宿主机上,集群分组分片分配由 k8s Operator 渲染并控制创建 DuplicateSet (小红书自研 k8s 资源对象)。REDtao 则会创建主从并根据 Operator 渲染出来的分片信息创建集群,单个 Pod 故障重启会重新加入集群,无需重新创建整个集群。集群升级时,Operator 通过感知主从分配控制先从后主的顺序,按照分片分配的顺序滚动升级以减少升级期间线上影响。