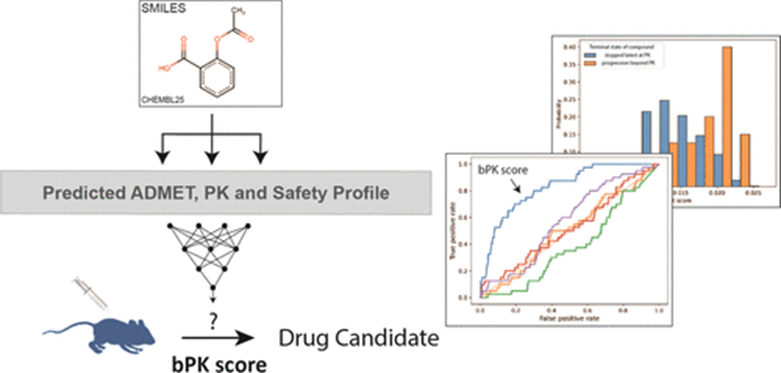
小分子药物开发是一个漫长的过程。从巨大的化学空间中识别并挑选出最有潜力成药的分子仍然具有挑战性。尽管目前已经有多种方法用于评估化合物成药潜力,如基于结构性质的sp3碳杂化比例(fraction of sp3-hybridized carbons,Fsp3)、Lipinski5规则(Lipinski’s rule of 5,Ro5)、QED打分、相对类药性打分(relative drug-likeness,RDL),以及最近的基于深度学习的方法DeepDL和GCN。然而,这些方法往往只能测定与获批药物之间的理化性质相似性,而没有充分考虑药物在生物系统中的特性(例如渗透性、清除率)。因此,单一的打分无法完全涵盖药物复杂的性质空间,这极大地限制了对化合物的指导优化。为了解决上述问题,诺华生物医学研究院近期报导了一种新的深度学习方法。该方法利用100个大规模ADMET预测结果来评估化合物成为相关候选药物的潜力,由此产生的分数称为bPK分数。该方法明显优于以前的方法,并在先前方法表现不佳的数据集上展现了较强的判别性能。相关工作以“Prediction of Small-Molecule
Developability Using Large-Scale In Silico ADMET Models”为题发表在美国化学会出版的药物化学核心期刊Journal of Medicinal Chemistry上(DOI:10.1021/acs.jmedchem.3c01083)。在该项研究中,作者对药物研发过程中的不同时间节点进行分类,将2005年至2017年间记录的近40000个化合物的理化特征数据及生物学数据用于训练深度神经网络模型。该模型采取秩次一致有序回归(rank-consistent ordinal regression)架构,以公司内部使用的ADMET模型及MELLODDY模型产生约100个的描述符作为模型的输入,根据预测产生的化合物ADMET图谱推断化合物在体内药代动力学(PK)阶段以外的研究潜力。为了评估bPK打分模型的性能,作者首先构建了一个包含约10000个化合物的内部测试集并进行打分,以分析该模型区分候选药能力,并与其他计算方法进行了比较。结果显示(图1b),QED、DeepDL或GCN等方法在内部测试集上没有显示出任何显著的辨别力,而作为基线模型的Fsp3模型的ROC-AUC为0.57,相较之下,bPK打分模型的ROC-AUC为0.83,展现出该模型较强的判别能力。图1:(a)bPK打分模型架构(左)和用于预测单个化合物的模型概述(右);(b)bPK打分模型与和其他已发表的化合物评分(QED、
DeepDL、GCN、Fsp3)的ROC曲线;(c)内部测试集中化合物bPK分数分布直方图。随后,作者通过减少模型输入特征数量来检验该模型的鲁棒性。在去除体内PK数据后,模型性能略微下降(ROC-AUC ≥
0.79),而仅使用ADMET数据时,ROC-AUC 显著降低(0.74),说明体外ADMET数据是模型的主要信息来源。作者还使用主成分分析得到的前2、5、10和20个特征来训练bPK打分模型。令人惊奇的是,在仅使用10个特征的情况下,模型AUC达到0.79。细微的特征变化并未使模型预测结果产生较大的波动,并且没有出现严重的过拟合现象,表明该模型具有较强的鲁棒性。为了深入了解不同ADMET预测方法对bPK打分模型的影响,作者使用可解释性AI模型量化特征重要性(图2)。在Shapley值最高的15个特征中,包含了体内生物利用度、清除率、渗透性和溶解度等相关测定。这些特征与候选分子挑选规则基本一致。在UMAP降维图中,候选药物一致分布在bPK分数较高的区域,但从结构以及性质角度来看并未得到可总结性的规律。为了评估模型的泛化能力,作者从ChEMBL数据构建了一个公共数据集,来模拟內部数据集的分布。ROC曲线结果显示bPK打分模型在公共数据集上具有与内部数据几乎一致的表现。这些结果表明该模型具有较好的泛化能力和鲁棒性。图2:(a)bPK打分模型输入特征Shapley分析结果(b)以bPK分数着色的UMAP降维图(c)根据性质及结构特征着色的UMAP降维图最后,作者利用bPK打分模型在诺华公司的内部项目上进行了回顾性研究。他们导出了几个项目中经过诺华化学团队详细注释及表征的所有分子,然后使用bPK评分对化合物进行评分。作者分析了不同项目中bPK分数随时间演变规律(图3)。除了项目2之外,其他项目中使用的不同化合物系列均展现出不同的分布规律,且bPK分数随化合物优化推进而增加,每个项目所选定的候选药物均获得最高的bPK打分。该结果表明,bPK打分模型可以从已有化合物中获取经验,并将该经验用于指导苗头化合物的发现、先导化合物骨架优化及分子生成过程。综上所述,作者提出了一种新颖的机器学习模型-bPK打分模型,该模型利用大规模体外ADMET预测结果作为输入。相比于其他单一条件作为输入的计算方法,这种集成式输入使模型在庞大的化合物性质空间实现最大范围的探索。在多个数据集中,bPK打分模型均表现出强大的鲁棒性以及泛化能力。应用bPK打分可以有效区分不同系列化合物并最终确定其优先级,对于药物发现及优化具有重要意义。[1] Beckers M, Sturm N, Sirockin F, Fechner N, Stiefl
N. Prediction of Small-Molecule Developability Using Large-Scale In Silico
ADMET Models. J Med Chem. 2023;66(20):14047-14060.
声明:发表/转载本文仅仅是出于传播信息的需要,并不意味着代表本公众号观点或证实其内容的真实性。据此内容作出的任何判断,后果自负。若有侵权,告知必删!
长按关注本公众号









