
本文作者:Origami
让人工智能上临床,你是不觉得还很遥远:最多,也就做个导诊、打个辅助吧。
然而就在本月,复旦大学和马萨诸塞大学的一项预印本研究,让 ChatGPT-4V 这个最新模型,参加了一场执医考试,还得到了在所有考试中都呈碾压式优秀表现的惊人结果。
——这碾压 70% 医学生的成绩,可能让很多即将成为医生的医学生直呼:「汗流浃背了老弟」。

参加执医考试,竟碾压了 70% 的医学生
这篇在 medRxiv 预印版发表的论文,题为 Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations,研究团队利用生成式多模态预训练模型 GPT-4V (vision) ,探索了该模型在临床考试中回答的准确性和解释质量。
该研究主要测试的 AI 模型,是近两年来最火热的 Chat Generative Pre-trained Transformer(ChatGPT)的相关产品。
ChatGPT 甫一面世,就成为了不少学者、学生的辅助,甚至用它完成课题、论文。但 AI 的局限性也显而易见——除了常常为人诟病的认知以外,只能读取和生成文本,还有无法处理如图像等其他数据模式的局限性。
而最新的 GPT-4V 却有所不同,它具有视觉处理/理解能力。既然如此,GPT-4V 是否有介入临床,分析医学图像的能力呢?
为了回答这个问题,研究者们决定让这些 AI 参加一次执医考试,并回答每道题的答题思路、做出解释。
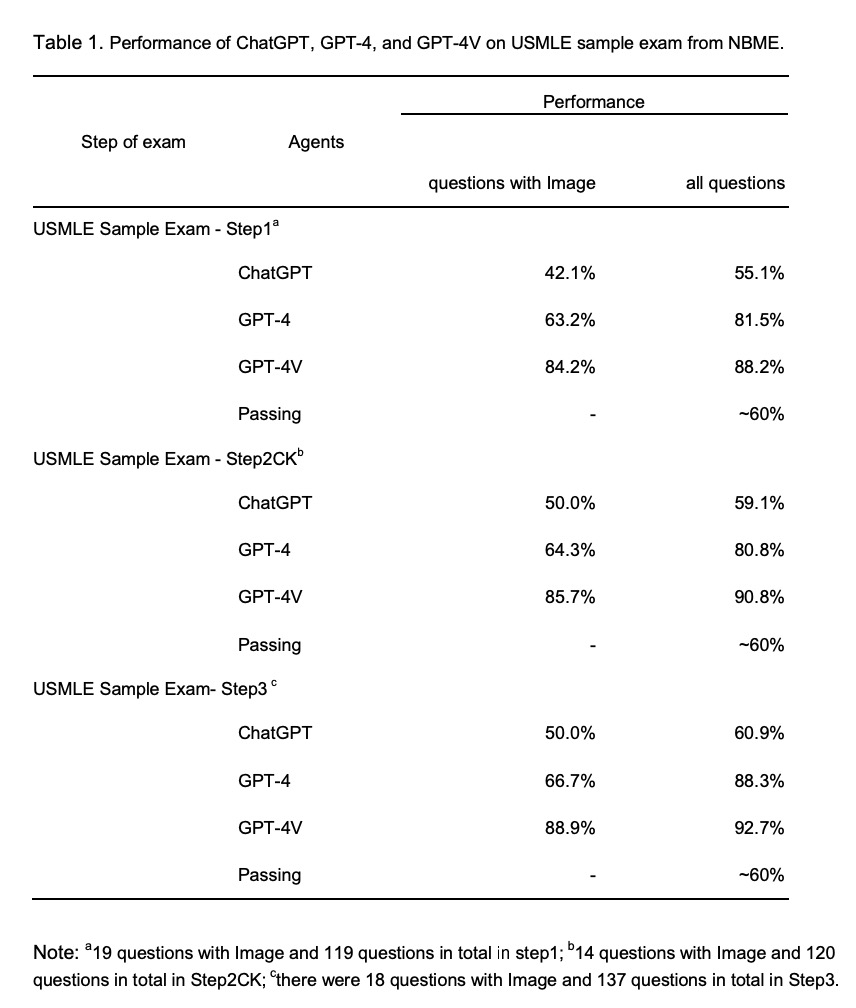
该研究使用的执医考试题型十分全面,涉及不同医学领域,且难度各异。研究使用来自美国医学执照考试(USMLE)、医学生考试题库(AMBOSS)和诊断放射学资格核心考试(DRQCE)的三套共计 226 道选择题(28 个医学领域)来考 GPT-4V、GPT-4 和 ChatGPT。
值得注意的是,考试题目均包含有图像内容。
通过图像附加上下文(即患者信息)和问题,研究者将多项选择提供给 GPT-4V。对于无法分析图像的 ChatGPT 与 GPT-4,则采用省略图像的单纯问答形式(如下图)。
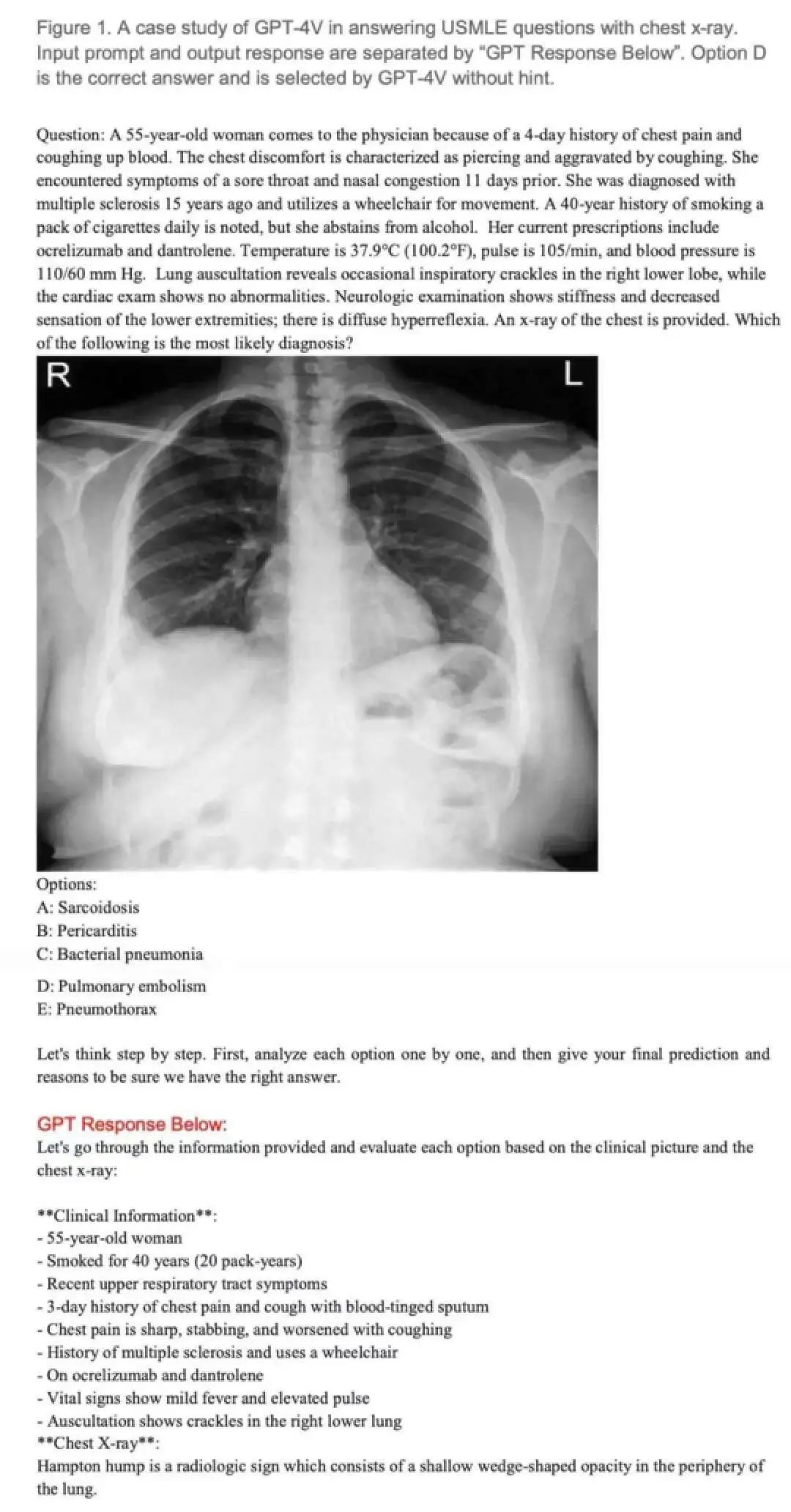
图源:文献 1
此外,研究者们让医疗专业人士评估 GPT-4V 的解释是否违背医学常识,并在 GPT-4V 做错时收集反馈、进一步训练。
结果显示,GPT-4V 在所有考试中都表现出碾压式的优秀表现。
对于 USMLE 样题的所有试题(包括无图像的试题),GPT-4V 在 Step1、Step2 和 Step3 中的准确率分别为 88.2%、90.8%、92.7%,远远高于 ChatGPT 和 GPT-4。
在带有图像的医学执照考试题上,GPT-4V 也表现出了很高的准确率。研究者估算,与准备考试的学生相比 GPT-4V 的大致排名能达到前 20~30% 的水平。
图源:文献 1
接着针对 AMBOSS,研究进一步将试题按难易程度分为 1~5 级,分别代表学生在第一次作答时最容易答对的 20%、20~50%、50~80%、80~95% 和 95~100% 的试题。
此时让医疗专业人士为 AI 做难度提示。GPT-4V 难度提示下准确率为 86%,不提示为 63%。随着难度增加,不给提示时 GPT-4V 表现变差,而提示时则下降并不明显。
但无论有没有提示,GPT-4V 的准确性总体上都优于医学生,并且题越难,优势越明显。
图源:文献 1
接着,研究者进一步评估用户对 GPT-4V 生成的解释,和专家人工解释的评价。结果,当 GPT-4V 正确回答时,生成的解释质量与专家的接近,甚至还会根据信息的有无,产生自己的判断。
例如对于第一张图中的考题,因为细菌性肺炎和肺栓塞都有咳嗽等症状,超 70% 的学生第一次都回答错误。而 GPT-4V 则正确地解释了带有汉普顿驼峰放射学征象的影像结果,侧重怀疑肺梗塞。
而当研究者去掉图像这一信息,再次提问时,GPT-4V 则在保留肺栓塞怀疑的同时,将答案切换为细菌性肺炎。
这种变化证明了 GPT-4V 确实是通过吸纳影像结果的分析,来回答这个问题。
而研究中对一高血压病例的提问也佐证了,GPT-4V 能够根据 CT 扫描图像、化验单和病人症状等其他信息,提供鉴别诊断和后续检查的建议。
进化版 ChatGPT,能让医生失业吗?
由这项研究可见,GPT-4V 在带有图像的医学执照考试题上,展现了非凡的准确率,在临床决策支持方面似也具备无穷的潜力。而这种优势,在某种程度上对于未来的医生而言,可能不仅是辅助,确有可能达到取而代之的地位。
毕竟一个优秀医生的培养周期是以数年为单位的,而大数据团队对于 AI 工具的喂养可能仅要数月。
也许很多人会想问:不久的将来,医生是否会像曾经的接线员、打字员、电报员一样,被科技发展所迭代彻底失去饭碗呢?
首先,根据这篇文献的解释,这种忧虑似乎为时尚早。
GPT-4V 回答错误并不罕见,而且此时生成的解释质量很差。
本研究中,图像误解依然是回答错误的主要原因,占到 76.3%,只有 10 个(18.2%)错误归因于文本误解。显而易见,即便是 GPT-4V,处理图像的能力还是远远落后于文本。

图源:文献 1
此外,GPT-4V 倾向于产生事实上不准确的响应,这也是目前 AI 工具的通病,仍然需要额外的医生审查才能保证可靠性。
其次,在实际的应用中,AI 的适配性也将面临长期的挑战。
英国林肯郡 NHS 系统医生史蒂夫表示,在英国的诊疗系统中,对于 AI 的使用一直保持着谨慎态度:「一方面我们的工作得益于 AI 工具产生的高效,一方面我们也忧虑着 AI 是否会造成数据泄露的风险。」
辽宁省某三甲医院医务科负责人陈良则认为:临床诊疗是一个繁琐的过程,从问诊治疗到康复随访,AI 的作用可能会在一个环节上发挥奇效,但并不是在每一个环节都有着颠覆性的作用。
「说句不好听的,如果 AI 真的取代了医生,万一出现医疗事故,我们追责是追究谁呢?是 AI 医生吗?还是说 AI 背后的工程师和设计者呢?」
[1]https://www.medrxiv.org/content/10.1101/2023.10.26.23297629v3.full丁香园是面向医疗从业者的专业平台,以「助力中国医生」为己任。在丁香园,可以和同行讨论病例 ,在线学习公开课,使用用药助手等临床决策工具,在丁香人才找可靠医疗岗位。








