AI大模型需要大规模、高质量数据,而数据的高效处理方式是大模型成功的关键,因此为应用程序迅速提供数据的能力至关重要。随着AI应用场景日趋复杂化,我们需要了解数据访问模式并采取合适的解决方案。
《大模型制胜宝典》白皮书全面介绍了现代AI/ML平台中的数据访问模式,并探讨了机器学习流程各个阶段中数据访问的特征,以及在构建数据和AI平台时可选用的解决方案。
案例1:金融科技巨头-支付宝,加速数十亿小文件上的大型计算机视觉训练支付宝是全球最大的移动支付平台之一,服务13亿个人用户和8000万商户。为了给用户提供最佳体验,支付宝依靠机器学习模型来支持各种功能,如欺诈检测、风险评估和个性化推荐。
然而,随着支付宝用户群和交易量的增长,公司开始在模型训练方面遭遇挑战。计算和存储性能之间的差异导致模型训练缓慢且效率低下。此外,专用硬件的高昂成本也给支付宝在预算方面带来了压力。
为了应对这些挑战,支付宝开始使用Alluxio作为加速机器学习任务的统一数据访问层。
Alluxio提供位于计算层和存储层之间的高性能缓存,降低延迟并提高吞吐量。使用Alluxio后,支付宝可以在标准商业化硬件上训练模型,其性价比高于使用专用硬件。
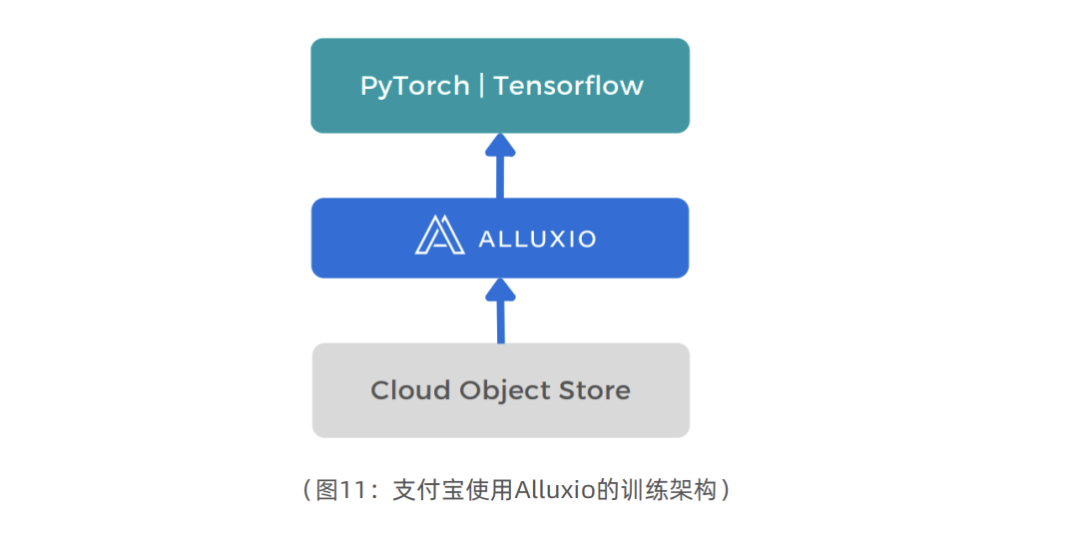
除了提高性能,Alluxio还简化了支付宝的数据管理。Alluxio提供按需数据访问,消除了维护数据副本的需求。这使得数据工程师可以腾出时间专注于其他任务,例如优化模型性能。
使用Alluxio后,支付宝的模型训练速度和效率都得到了显著提升。此外,基础设施成本有所降低,数据工程师能有更多时间来专注于更具战略意义的任务。
案例2:头部在线内容社区-知乎,通过优化GPU利用率达到90%加速模型训练和部署
知乎是中国领先的在线内容社区,目前拥有4亿用户、1亿月活用户和540亿月浏览量。知乎通过训练自定义大语言模型(LLM)来支持其搜索和推荐功能。为了开发LLM,知乎需要高性能的数据访问层来有效地访问位于多个云上的数据。
知乎团队在为LLM构建高性能数据访问层时面临几个挑战。首先,需要找到一种方法来高效地访问位于多个云上的数据。其次,需要确保数据访问层具有可扩展性,能满足LLM训练和部署不断增长的需求。第三,需要确保数据访问层是可靠的,并且能够承受预期之外的故障。
知乎团队选择使用Alluxio作为LLM的高性能数据访问层。Alluxio为模型训练和部署中的大规模数据访问提供统一的加速解决方案。
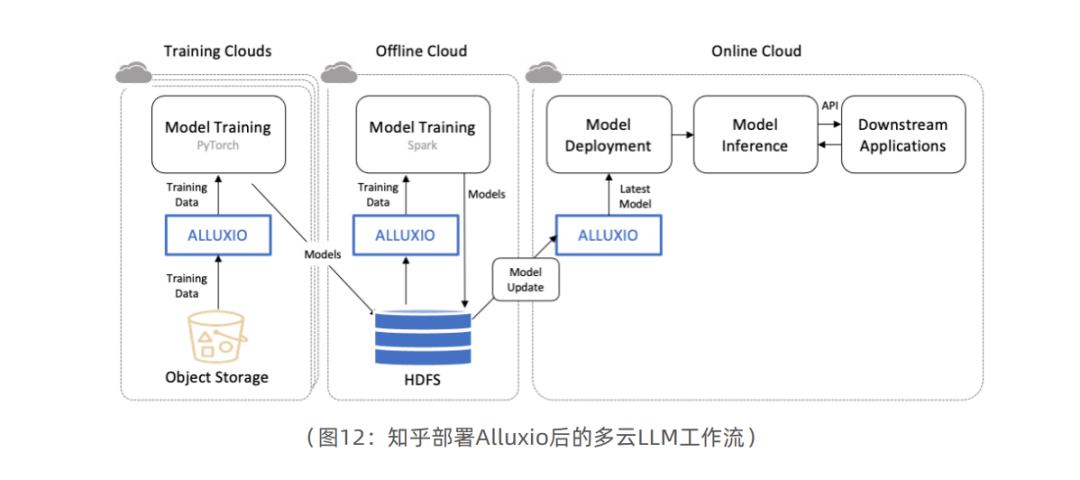
知乎在部署Alluxio后,在性能、可扩展性和可靠性方面都实现了显著提升。LLM的训练速度提升了2-3倍,模型更新频次由几个小时或几天提高到分钟级别。此外,基础设施成本也降低了50%。
探索更多内容请下载电子书👇

👇点击阅读原文免费下载电子书










