目前,大型语言模型(LLM)驱动的智能体在静态和简单任务上表现出色。然而,面对复杂挑战,如机器学习任务,表现不佳。为了突破这一瓶颈,Data Interpreter应运而生。它利用三种技术:基于分层图结构的动态计划、工具集成与生成、基于置信度验证与经验驱动的推理增强。Data Interpreter在数学推理、机器学习和开放性任务上取得领先水平。相对其他开源基线,它在数学推理任务中准确率提升了26%,在机器学习任务中得分从0.86提升至0.95,在开放性任务中更是实现了112%的惊人提升。这标志着基于LLM的智能体在数据科学领域取得重大进展,为解决更复杂、更动态的问题提供了更智能的解决方案。

Data Interpreter: An LLM Agent For Data Science https://arxiv.org/abs/2402.18679 https://github.com/geekan/MetaGPT
目前,由大型语言模型(LLM)驱动的智能体已经证明了它们在处理复杂任务方面的显著潜力。此外,通过赋予LLM代码执行能力来提升其问题解决能力正逐渐成为一种趋势,这一点已经通过Code-Interpreter [1]、OpenInterpreter [2]、TaskWeaver [3] 等工作得到了实践验证。然而,在数据科学领域,面对数据的实时变化、任务间依赖关系复杂、流程优化的专业性,以及执行结果反馈的逻辑一致性识别等挑战,现有LLM-based智能体的性能仍有待提升。MetaGPT团队联合北京工业大学、复旦大学、华东师范大学、河海大学、加拿大蒙特利尔大学、KAUST、圣母大学、厦门大学、香港中文大学(深圳)、香港大学、耶鲁大学、中国科学院深圳先进技术研究院、中国人民大学等多所顶尖高校和研究机构,共同推出了Data Interpreter。这是一种全新的解决方案,旨在通过增强智能体的任务规划,工具集成以及推理能力,直面数据科学问题的挑战。Data Interpreter提出了三个关键技术:- 基于分层图的动态计划,基于分层的图结构进行任务和代码规划,有效管理任务间的复杂依赖,灵活应对数据科学任务的实时数据变化;
- 工具集成与进化,通过在代码生成过程中自动集成代码片段作为工具,动态嵌入了数据科学领域所需的领域知识;
- 基于验证与经验驱动的推理,自动在反馈中增强逻辑一致性检测,通过基于置信度的验证提升执行代码的逻辑合理性,并借助经验库增强推理能力。在各种数据科学和现实世界任务上的评估表明,与开源基线相比,Data Interpreter在机器学习任务中表现出色,准确率从0.86提升至0.95。此外,在MATH数据集上提高了26%,在开放式任务中实现了显著的112%提升。
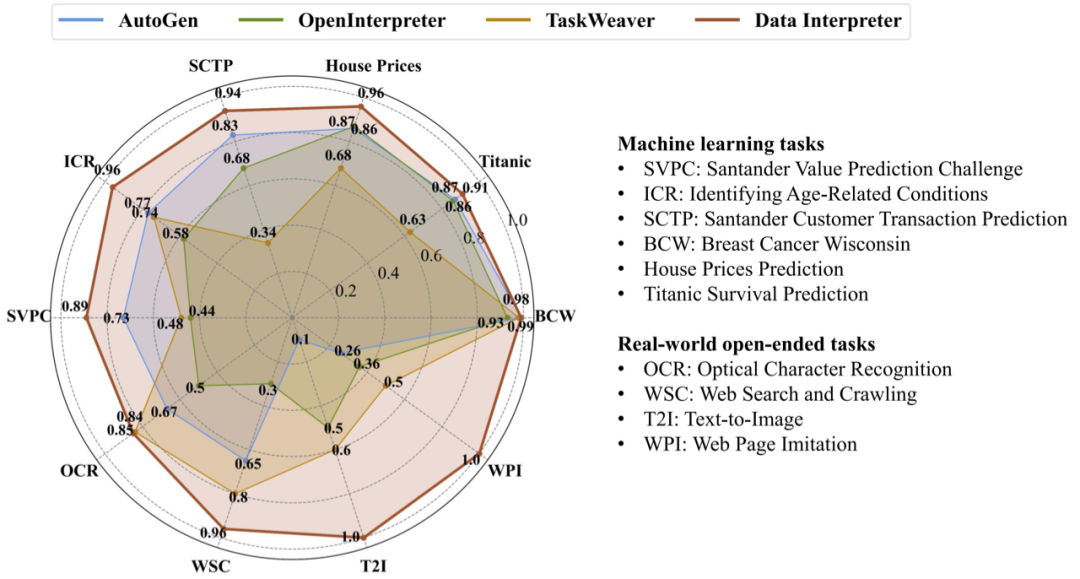
在机器学习任务和现实世界的开放式任务中与各种开源框架进行比较,Data Interpreter在多种任务上取得sota二、方法介绍
2.1 DYNAMIC PLANNING WITH HIERARCHICAL STRUCTURE
在数据科学领域,实时数据的动态变化和任务间复杂的变量依赖关系对大型语言模型(LLM)提出了重大挑战。为了有效应对这些挑战,Data Interpreter提出了一种创新解决方案:基于分层图结构的动态计划(DYNAMIC PLANNING WITH HIERARCHICAL STRUCTURE)。这种方法借鉴了自动化机器学习中的层次规划技术,通过层次结构将复杂的数据科学问题分解为易于管理的小任务,并进一步将这些任务转化为具体的代码执行动作,从而实现细致的规划与执行。
分层结构:(a) 一个有组织的任务和动作图,展示了高层级机器学习项目的工作流程,包括实现项目目标所需的任务依赖和动作序列。(b) 任务的有向无环图(DAG),以机器操作状态预测问题为例。任务图展示了拆解的计划任务,而动作图(也称为执行图)则根据计划的任务图执行各个节点。每个节点的执行代码由LLM转换。
这种动态计划方法赋予了Data Interpreter在任务变化时的适应性,而有向无环图(Directed acyclic graph)结构则在监控和处理数据科学问题中的任务依赖关系方面展现出了高效性。通过这种方式,Data Interpreter能够有效地管理和优化数据科学任务的执行流程,提高了问题解决的准确性。数据解释器的动态计划管理:(a) 通过人工编辑进行计划细化。左侧图像显示了在图上经过人工编辑的任务,右侧图像则展示了细化后的计划,包括更新后的任务3.1'、3.2'以及新增的任务3.3。(b) 对失败任务的计划进行细化。在任务执行后,如果任务3.3失败,细化后的计划将整合已有的成功任务,用更新后的任务3.3'替换原任务3.3,并引入新任务4.1、4.2、4.3和5。2.2 TOOL UTILIZATION AND GENERATION
在数据科学任务中,任务的多样性与专业性要求基于LLM框架具备广泛的工具调用能力。现有的工具调用方式往往局限于API的形式,无法满足任务多样性带来的动态需求。 Data Interpreter 提出了工具集成与生成的方法。通过工具推荐与组织,能够根据任务描述,进行任务分类,从而有效选择合适的工具集。在执行阶段,Data Interpreter根据工具参数描述、工具方法描述文档的结构化信息,动态嵌入和调整工具参数,以适应任务的具体需求。此外,Data Interpreter 还能够通过自我进化,从执行经验中抽象出工具的核心功能,形成通用的代码片段,集成到工具函数库之中。这些工具函数可以在未来的任务中重复使用,从而减少了调试频率,提高了执行效率。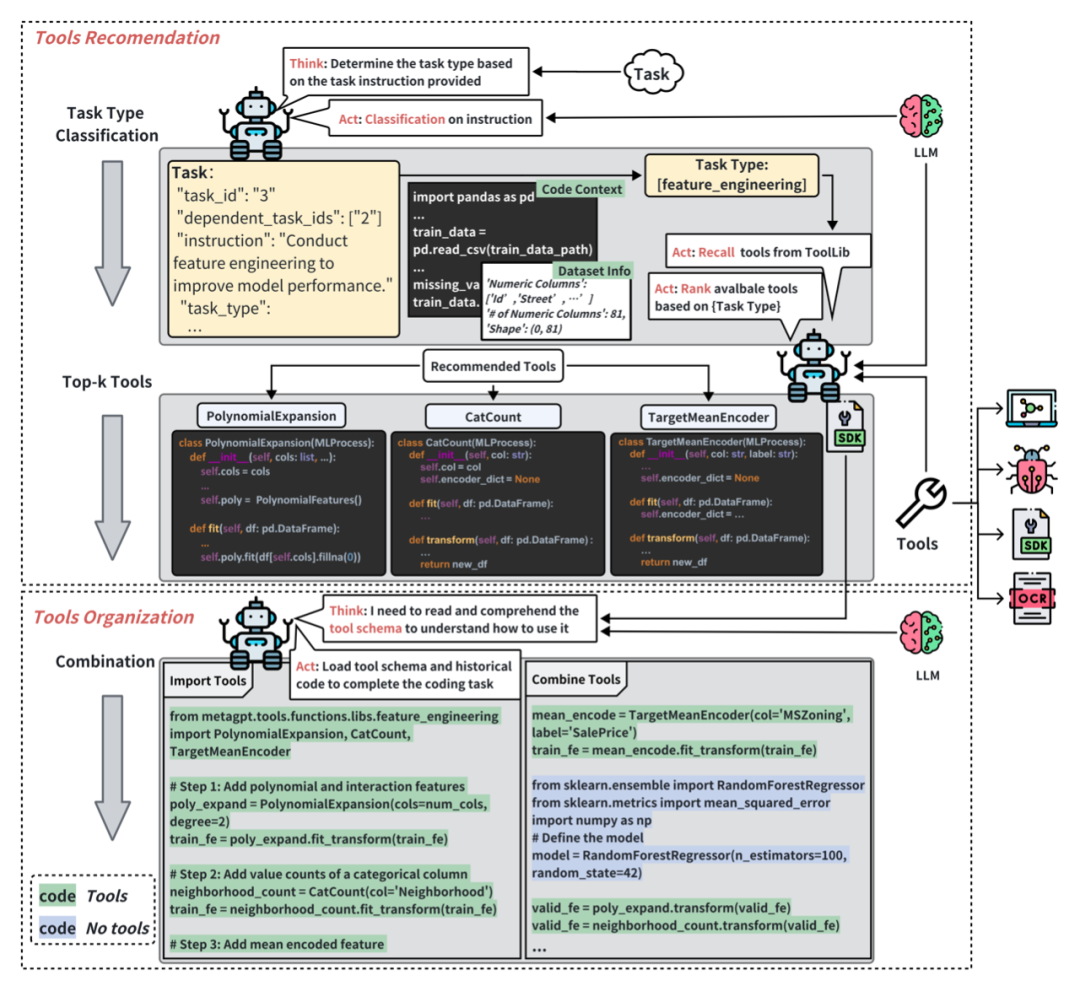
数据解释器中的工具使用流程:工具推荐最初根据任务分类来选择工具。然后根据任务需求组合多个工具使用。
2.3 ENHANCING REASONING WITH VERIFICATION AND EXPERIENCE
解决数据科学问题需要严谨的数据与逻辑验证过程,现有的研究在解决这一类问题的过程中,往往依赖于代码执行后的错误检测或异常捕获,这一方式往往会误解代码执行正确即任务完成,无法发现逻辑错误,难以提升任务实现的有效性。Data Interpreter 通过结合基于置信度的自动验证(Automated Confidece-based Verification)策略,显著提升了其在数据科学问题解决中的推理能力。ACV策略要求Data Interpreter在执行代码后生成验证代码并执行验证,根据执行验证结果校验任务和实现代码的一致性,类似于白盒测试流程。在需要更严谨数值反馈的场景中,如使用LLM进行数学推理,Data Interpreter可以增加多次独立验证,并通过多次结果的置信度排序来进一步提升效果。另一方面,Data Interpreter 利用经验池存储和反思任务执行过程中的经验和教训,能够从过去的成功和失败中学习代码知识,从而在面对新任务时做出更准确的决策。这种结合实时验证和经验学习的方法,显著增强了解释器的推理能力,提升了任务的解决质量。
以MATH内的一个任务说明基于置信度自动验证流程:虚线框内是自动验证的过程,虚线框下方根据验证对多个候选答案进行排序
三、实验分析
在实验部分,Data Interpreter在多个数据科学和现实世界任务上进行了评估。与开源基线相比,Data Interpreter在机器学习任务中综合得分从0.86提升至0.95,其准确率在MATH数据集上提高了26%,在开放式任务中任务完成率提升112%。这一成果不仅为数据科学领域带来了新的里程碑,也为LLM在实际应用中的潜力提供了有力的证明。MATH benchmark [4] 涵盖了从初等代数到微积分等广泛的数学领域。这个基准测试不仅测试了模型对数学知识的掌握程度,还考察了它们在解决复杂数学问题时的推理能力。为了评估Data Interpreter在这一领域的性能,研究团队选择了MATH基准测试中难度最高的Level-5问题,这些问题涉及计数和概率(C.Prob)、数论(N.Theory)、初等代数(Prealg)和微积分(Precalc)等四个类别。如上图所示,以Accuracy作为这个任务的评估指标,Data Interpreter在4个类别上均取得了最好的成绩。特别是在 N.Theory 中,带有Automated Confidence-based Verification (ACV) 策略的Data Interpreter达到了 0.81 的准确率。在机器学习的世界里,精准和效率是衡量一个模型成功与否的关键。为了测试Data Interpreter在这一领域的能力,研究团队精心设计了ML-Benchmark,这是一个集合了Kaggle网站上多种经典机器学习任务的测试集。这些任务不仅覆盖了葡萄酒识别(WR)、Wisconsin乳腺癌(BCW)、Titanic生存预测等经典问题,还包括了房价预测(House Prices)、Santander客户交易预测(SCTP)、识别与年龄相关的状况(ICR)以及Santander价值预测挑战赛(SVPC)等更具挑战性的项目。
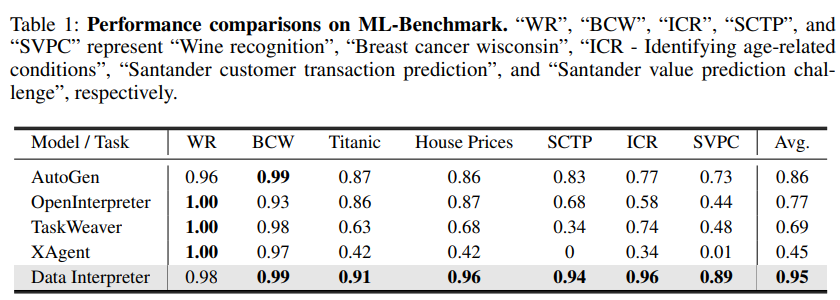
在与其他开源框架的较量中,Data Interpreter展现了其卓越的性能。通过任务完成率(CR)、归一化性能得分(NPS)和综合得分(CS)这三个关键指标,Data Interpreter在七项任务上的平均得分高达0.95,远超AutoGen的0.86,提升了10.3%。特别是在ICR和SVPC这两个数据集上,Data Interpreter的表现尤为出色,分别比AutoGen提高了24.7%和21.2%。
更令人印象深刻的是,Data Interpreter是唯一一个在Titanic、House Prices、SCTP和ICR任务上得分均超过0.9的框架,这标志着它在机器学习任务中不仅能够完成核心步骤,还能在执行过程中持续优化任务效果。
3.3 Open-ended tasks
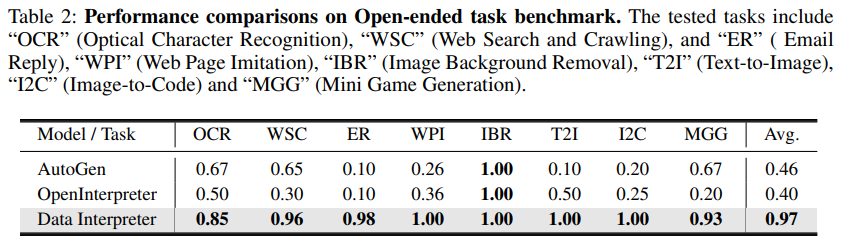
在人工智能的世界里,真正的挑战往往来自于那些开放式的任务,它们不仅要求模型具备广泛的知识,还要求它们能够灵活应对现实世界的复杂性。为了测试Data Interpreter在这类任务中的表现,研究团队精心整理了一个包含20个任务的开放式任务基准。这些任务涵盖了从光学字符识别(OCR)到迷你游戏生成(MGG)等多个领域,包括网络搜索和爬虫(WSC)、电子邮件自动回复(ER)、网页模仿(WPI)、图像背景去除(IBR)、文本转图像(T2I)、图像到HTML代码生成(I2C)等多样化的挑战。在这个实验中,Data Interpreter与AutoGen和Open Interpreter这两个基准模型进行了对比。每个框架对每个任务进行了三次实验,以平均完成率作为评价标准。结果显示,Data Interpreter在开放式任务上的平均完成率为0.97,与AutoGen相比大幅提高了112%。对于去除图像背景(IBR)任务,所有三个框架都获得了1.0的完整分数。在OCR相关任务中,Data Interpreter的平均完成率为0.85,比AutoGen和Open Interpreter分别高出26.8%和70.0%。在需要多个步骤并利用多模态工具/能力的任务中,例如网页模仿 (WPI)、图像到 HTML 代码生成 (I2C)和文本转图像 (T2I),Data Interpreter是唯一能够执行所有步骤的框架。而在电子邮件自动回复 (ER)任务中,AutoGen和Open Interpreter因为无法登录并获取邮箱状态,导致完成率较低,而Data Interpreter可以在执行过程中动态调整任务,从而在完成率上达到0.98。为了进一步探讨相关方法的有效性,我们进行了消融实验。为评估各模块性能,我们在ML-Benchmark上,使用了三种配置进行测试:1)初始设置:基础ReAct框架,包含简单的任务理解提示词以及支持代码执行流程;2)增加了基于分层图结构的动态计划,包括分层规划和每一步骤的动态管理,便于实时调整;3)在2)的基础上增加了工具集成能力。如表3所示,基于分层图结构的动态计划显著提高了0.48分。它通过准备数据集并实时跟踪数据变化有助于获得更优性能,特别是完成率方面效果显著。此外,工具的使用带来了额外9.84%的改进,综合得分达到了0.94分。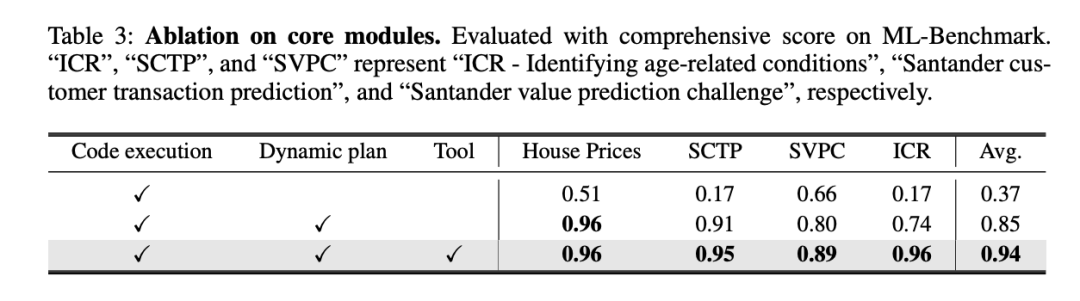
Data Interpreter在包括GPT-4-Turbo、GPT-3.5-Turbo以及不同尺寸的LLMs上进行了实验。在机器学习的任务中,更大尺寸的LLM,例如Qwen-72B-Chat[5] 和Mixtral-8x7B [6]展现出与GPT-3.5-Turbo相当的表现,而较小的模型则性能下降较多。如下图所示,结合Yi-34B-Chat[7] 、Qwen-14B-Chat[5] 和 Llama2-13B-Chat [8],甚至DeepSeek-7B-Chat [9],Data Interpreter 可以有效地处理数据加载及数据分析等步骤。然而,这些模型在执行需要较高编码能力的任务时面临仍受到自身能力限制,通常导致流程无法完成。在open-ended task中,Mixtral-8x7B在3项任务上的完成率较高,但在网络搜索和爬虫(WSC)任务中表现不佳,难以准确地将完整结果输出到CSV文件。与机器学习任务ML-Benchmark类似,规模较小的模型仍由于编码能力受限而遇到执行失败问题。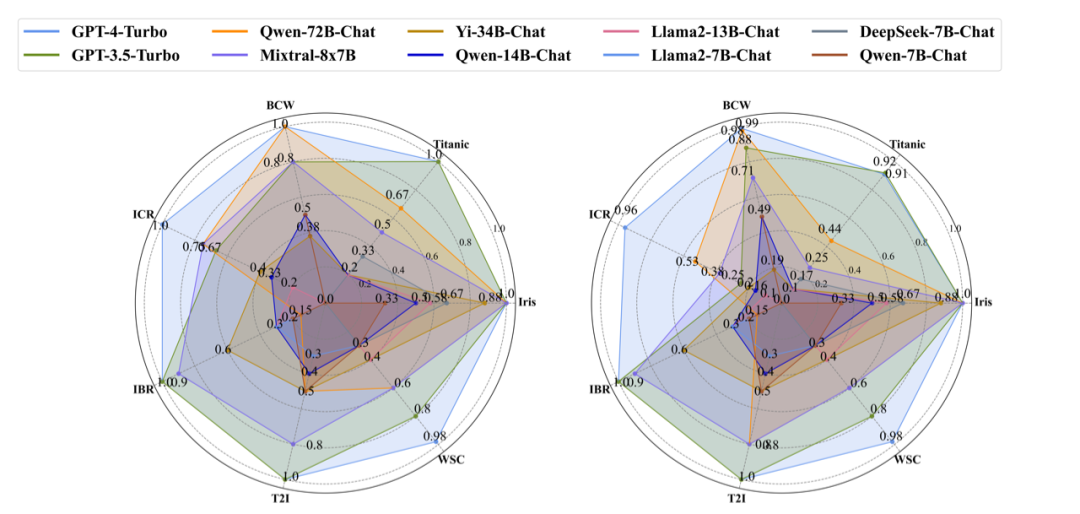
在ML-BenchMark上使用不同尺寸LLM的评估。(左图:完成率,右图:综合得分)经验池大小
另外,我们还针对经验池的大小进行了消融实验。按存储任务级别的经验数量,分别设置经验池大小为0,80和200,我们对比Data Interpreter在不同任务上所需的代码debug次数和执行成本的变化,结果如下所示:随着经验池从1增加至200,平均的debug次数从1.48降低到了0.32,执行成本从0.80美元降低到了0.24美元,这说明经验的累计对于从自然语言描述任务到代码生成能够有明显的帮助。
目前,大型语言模型(LLM)驱动的智能体已经在处理静态和简单任务上展现了令人瞩目的能力。然而,当面对需要多步骤解决的复杂挑战时,它们的表现往往不尽人意,比如机器学习任务。为了突破这一瓶颈,Data Interpreter应运而生,它不仅在机器学习任务上取得了显著进步,更在数学推理和开放式任务中达到了行业领先水平。得益于以下三种技术的融合:基于分层图结构的动态计划、工具集成与生成、基于置信度验证与经验驱动的推理增强。Data Interpreter在数学推理任务, 机器学习任务和复杂的开放性任务上达到了 sota 水平。相对其他开源基线,Data Interpreter在MATH数学推理任务中准确率提升了26%,在ML-Benchmark机器学习任务中将得分从0.86提升至0.95,在开放式任务Open-ended tasks中更是实现了112% 的惊人提升。这些结果不仅标志着基于LLM的智能体在数据科学领域的重大提升,也预示着AI技术在处理更复杂、更动态的任务时将更加得心应手,为人类社会带来更多智能化的解决方案。[1] https://chat.openai.com/?model=gpt-4-codeinterpreter[2] https://github.com/KillianLucas/open-interpreter[3] https://arxiv.org/abs/2311.17541[4] MATH:https://arxiv.org/pdf/2308.07921.pdf[5] Qwen:https://arxiv.org/pdf/2309.16609.pdf[6] Mixtral:https://arxiv.org/pdf/2401.04088.pdf[7] Yi:https://huggingface.co/01-ai/Yi-34B-Chat
[8] Llama2:https://arxiv.org/pdf/2307.09288.pdf[9] DeepSeek:https://arxiv.org/pdf/2401.02954.pdfIllustration From IconScout By Delesign Graphics
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线500+期talk视频,3000+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。
将门是一家以专注于数智核心科技领域的新型创投机构,也是北京市标杆型孵化器。公司致力于通过连接技术与商业,发掘和培育具有全球影响力的科技创新企业,推动企业创新发展与产业升级。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:










