
划重点:
- 3 个月增长 300%,OpenAI 企业版 ChatGPT 用户规模突破 60 万
- 谷歌安卓版 Gmail 将迎新特性:整合 Gemini,帮用户总结邮件内容
- 5 月起 Meta Threads / Instagram将对 AI 生成内容添加水印标记
- xAI或正寻求 30 亿美元融资,估值达 180 亿美元
- YouTube CEO 点名 OpenAI:若利用其视频训练 AI 模型属违规行为
- 通义千问开源320亿参数模型,已实现7款大语言模型全开源
- 百度文心一言上线新功能,可快速定制自己的 AI 声音
资讯详情:
3 个月增长 300%,OpenAI 企业版 ChatGPT 用户规模突破 60 万
OpenAI 首席运营官布拉德・莱特凯普(Brad Lightcap)表示,当前企业版 ChatGPT 注册用户数量超过 60 万。
OpenAI 于 2023 年 8 月发布企业版 ChatGPT,不仅可以无限制地快速访问强大的 GPT-4 模型,还可以进行更深入的数据分析,帮助企业快速理解信息,并且可以向 ChatGPT 提出更复杂的问题。
OpenAI 曾于 2024 年 1 月发布报告,表示企业版 ChatGPT 注册用户数量为15 万,也就是说在过去短短 3 个月时间里,注册用户数增加了 45 万,增长 300%。
莱特凯普在采访中表示:“今年将会成为企业推广普及 AI 的一年,已经显现出强大的驱动力”。
莱特凯普透露,OpenAI 目前约有 1200 名员工,计划在东京开设办事处。

谷歌安卓版Gmail 将迎新特性:整合 Gemini,帮用户总结邮件内容博主@AssembleDebug 近日发布推文,挖掘安卓版 Gmail v2024.03.31.621006929 版本更新,发现谷歌正在测试“Summarize this email”功能,帮用户总结当前邮件内容。
根据曝光的截图,Gmail 新版在邮件标题下方会出现“Summarize this email”按钮,只是现阶段该功能没有生效,但从名称判断可以确认是总结当前邮件内容。
网友推测在点击该按钮之后,将在屏幕底部弹出一个窗口,以要点形式显示电子邮件的摘要。这与网页上的操作方式有些类似,只是网页版会跳出侧边栏,而安卓版会显示一个弹窗。
相关资料显示安卓版Gmail 在顶部的“...”菜单中也出现了“Gemini”条目,现阶段同样没有生效,用户点击之后只是会跳出一个空白页面。

5 月起 Meta Threads / Instagram将对 AI 生成内容添加水印标记
据ZAKER新闻报道,Meta 公司昨日发布新闻稿,宣布将在5 月起在自家 Instagram、Threads 及 Facebook 平台为 AI 内容添加“水印标记”。
Meta 在新闻稿中声称,这些变化来自公司内部监督委员会的建议、公共调查的结果和“学术界、民间社会组织和其他方面”的建议。
Meta公司将使用算法及真人检测“可能由 AI 生成的内容“,而用户也可以自行在图片中注释”相关图片由 AI 生成”,此类消息将作为水印添加至用户图片中,以便于他人甄别。

xAI或正寻求 30 亿美元融资,估值达 180 亿美元
据BlockBeats报道,Elon Musk)旗下的人工智能创业公司 xAI 正与投资者洽谈融资事宜。此次融资规模达到 30 亿美元,这将使 xAI 的估值达到 180 亿美元。
报道称,考虑参与 xAI 融资的投资方包括风投公司 Gigafund 和投资人 Steve Jurvetson。Gigafund 由曾联合创办 PayPal 的 Stephen Oskoui 和 Luke Nosek 于 2017 年 7 月联合创立。Jurvetson 则是另一家风投公司 Future Ventures 的联合创始人。xAI 此次融资的具体条款尚未敲定,相关计划也可能发生变化。
值得注意的是,Gigafund 和 Jurvetson 都与马斯克旗下的公司渊源颇深,他们此前曾投资过 SpaceX、特斯拉、Boring Company 和 Neuralink 等公司。

YouTube CEO 点名 OpenAI:若利用其视频训练 AI 模型属违规行为
据Readhub报道,YouTube 首席执行官尼尔・莫汉(Neal Mohan)近日在采访中公开表示,尽管没有直接证据表明 OpenAI 使用 YouTube 视频来训练 Sora(文本生成视频的 AI 模型),但警告称这种行为违反了 YouTube 现行的平台服务条款。
莫汉在接受彭博社采访时强调,下载 YouTube 视频,然后用于训练 Sora 等 AI 模型显然违反了平台的相关条款。
莫汉表示:“从创作者的角度来看,当创作者将他们的辛勤劳动上传到我们的平台时,他们有一定的期望。其中之一就是符合 YouTube 的服务条款,不允许下载文字稿或视频片段等内容,这明显违反了我们的服务条款。这些就是我们平台上内容的行事规则”。
莫汉承认谷歌培训旗下的 Gemini 模型时,使用了 YouTube 上的一些内容,但我们在使用这些内容之前,已经得到了创作者的授权,并遵循了 YouTube 与创作者之间的个人合同。

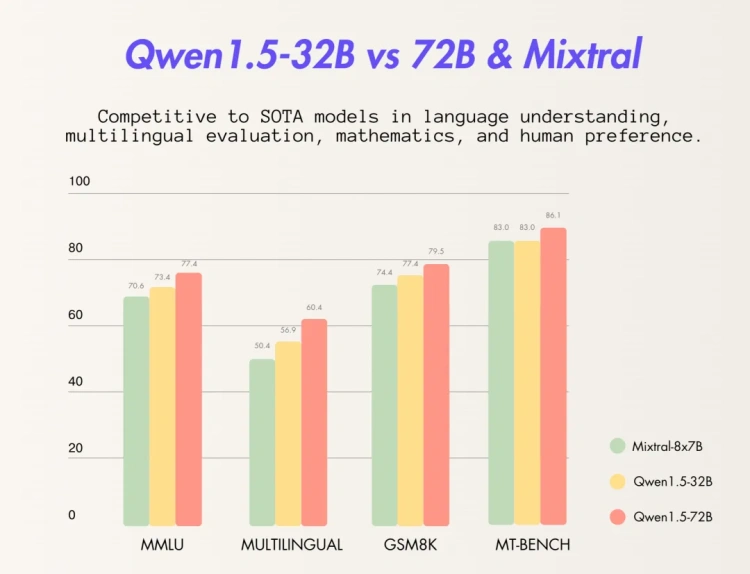
通义千问开源320亿参数模型,已实现7款大语言模型全开源
阿里云通义千问开源320亿参数模型Qwen1.5-32B,可最大限度兼顾性能、效率和内存占用的平衡,为企业和开发者提供更高性价比的模型选择。目前,通义千问共开源了7款大语言模型,在海内外开源社区累计下载量突破300万。
通义千问此前已开源5亿、18亿、40亿、70亿、140亿和720亿参数的6款大语言模型并均已升级至1.5版本,其中,几款小尺寸模型可便捷地在端侧部署,720亿参数模型则拥有业界领先的性能,多次登上HuggingFace等模型榜单。此次开源的320亿参数模型,将在性能、效率和内存占用之间实现更理想的平衡,例如,相比14B模型,32B在智能体场景下能力更强;相比72B,32B的推理成本更低。通义千问团队希望32B开源模型能为下游应用提供更好的解决方案。
百度文心一言上线新功能,可快速定制自己的 AI 声音百度近日宣布,文心一言上线全新功能,可利用 AI 智能体创建专属于自己的 AI 声音。
根据系统提示读出一段话,只需两秒左右的时间,系统便能捕捉到你的声音特点,为你生成一个独特的“语音助手”。在确认声音质量后,你的专属“语音库”就在瞬间构建完成。今后,在与智能体的每一次对话中,你都可以点击播放键,使用自己合成的音色进行语音播报。
用户还可以点击对话框上的通话按钮,与自己构建的数字分身实时对话,音色和音调都与本人完全一致。
北京大学:
《Simple and Scalable Strategies to Continually Pre-train Large Language Models》
论文提出了一种简单的持续学习策略,包括学习率(LR)重新升温、LR重新衰减和重放以前的数据,以应对新数据带来的分布变化。论文的实验结果表明,这种持续学习策略可以在大数据集下匹配从头开始重新训练的性能,同时只使用了一小部分计算资源。此外,论文还提出了一些替代余弦学习率计划的方法,以避免LR重新升温引起的遗忘问题。
论文地址:
https://arxiv.org/abs/2403.08763v2
斯坦福大学:
《Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking》
论文提出了一种基于少量示例的推理学习方法,使用可学习的标记来指示思想的开始和结束,以及扩展的teacher-forcing技术,从而解决了生成推理的计算成本、模型不知如何生成或使用内部思想以及需要预测超出单个下一个标记的关键问题。实验结果表明,Quiet-STaR可以在不需要对任务进行微调的情况下,显著提高语言模型的预测能力,尤其是对于难以预测的标记。
论文地址:
https://arxiv.org/abs/2403.09629v2
《Logits of API-Protected LLMs Leak Proprietary Information》
本论文的关键思路是通过模型图像或模型签名来解锁LLMs的多种能力,包括发现LLM的隐藏大小,获取全词汇输出,检测和消除不同的模型更新,识别给定单个完整LLM输出的源LLM,甚至估计输出层参数。论文通过实验验证了提出的方法的有效性,使用了OpenAI的gpt-3.5-turbo模型进行了实验,并得出了该模型的嵌入大小约为4,096的结论。此外,论文还探讨了LLM提供商如何防范此类攻击,并提出这些能力可以作为一个特性,允许更大的透明度和问责制。
论文地址:
https://arxiv.org/abs/2403.09539v2
伦敦大学国王学院:
《The Topos of Transformer Networks》
论文通过拓扑学的方法,将常见的神经网络架构嵌入到分段线性函数的前拓扑中,而Transformer架构则必须在其拓扑完成度中运行。这表明两者实现了不同的逻辑片段:前者是一阶逻辑,而Transformer是高阶推理器。论文的亮点包括使用拓扑学方法分析Transformer架构的表达能力,探究其与其他神经网络架构的异同;论文还将分析结果与架构搜索和梯度下降相结合,提出了一个新的框架来研究神经网络架构和优化。
论文地址:
https://arxiv.org/abs/2403.18415v1
麻省理工学院:
《The Unreasonable Ineffectiveness of the Deeper Layers》
本论文的实验结果表明,在不同的问答基准测试中,预训练语言模型的性能只有剪枝了大约一半的层数后才会出现明显的下降。作者使用了参数高效的微调方法,例如量化和低秩适配器,使得所有实验都可以在单个A100 GPU上完成。此外,本论文的研究结果表明,层剪枝方法可以与其他参数高效微调策略相辅相成,进一步减少微调的计算资源,并提高推理的内存和延迟。
论文地址:
https://arxiv.org/abs/2403.17887v1










