
人工智能生成内容(AIGC)技术,以文本到图像生成为代表,导致了深度伪造的恶意使用,引发了关于多媒体内容可信度的担忧。将传统伪造检测方法适应于扩散模型颇具挑战。
因此,本文提出了一种专门为扩散模型设计的伪造检测方法,称为三合一检测器。三合一检测器通过CLIP编码器融入粗粒度文本特征,并与像素域中的细粒度伪影连贯地整合,以实现全面的多模态检测。为了提高对扩散生成图像特征的敏感性,设计了一个多光谱通道注意力融合单元(MCAF),通过自适应融合不同的频段提取光谱不一致性,并进一步整合两种模态的空间共现。
广泛的实验验证了作者的三合一检测器方法优于几种最先进的方法,在所有数据集上的性能具有竞争力,并且在扩散数据集上的迁移性提高了17.6%。
1 Introduction
最近,扩散模型在图像生成领域迅速发展。以文本图像生成为代表的AI生成技术显著降低了合成图像创作的门槛。不幸的是,这种能力有可能被滥用于恶意目的。例如,文本图像生成可以用于零样本场景中,针对全球知名政治行人制作深度伪造攻击[1]。这种滥用可能会在社会结构中产生严重的信任问题。扩散生成机制与之前的做法不同,现有的检测方法在其可迁移性方面表现不佳。因此,开发针对扩散模型的伪造检测方法具有重要意义。
最近有一些关于扩散模型生成图像检测的研究,有些研究[2][3]采用在不同数据集上训练的卷积神经网络提取特征并进行分类。钟等人[4]提出了一种检测模型,通过分析图像中丰富纹理和弱纹理区域之间的像素相关性提取差异特征,但仅考虑纹理的单个特征导致数据泛化能力差等。黄等人[5]提出将图像文本双模态特征堆叠到虚假内容的检测中,但在语义空间并未实现对齐。
为了应对这一挑战,作者的工作分析了扩散模型和真实图像的差异表征。研究发现,提示输入对生成图像是否更真实有显著影响[6],文本提示的语义粗糙度和其语义空间的结构完整性直接影响扩散模型生成的质量,可以预期文本的相关特性在特征 Level 上对扩散模型生成的图像检测也有影响。鉴于U-Net已在各种扩散模型中得到广泛应用,U-Net中包含的上采样层也已成为扩散模型的重要组成部分,上采样层带来的频域内容变化也具有作为通用扩散伪造检测的巨大潜力。如图1所示,通过频域变换,作者发现真实图像的频域在所有方向上更平衡,而扩散生成的图像在特定方向上集中。

图1:扩散生成过程及经过DCT变换后真实和伪造图像的频谱比较。
作者提出了一种名为Trinity Detector的新方法。Trinity Detector提供了一种可靠的方式来区分真实图像和扩散生成的图像。确切地说,Trinity Detector方法包括两部分:(1)作者专门设计了一个多光谱通道注意力融合单元,通过自适应融合不同频段来提取真实图像与扩散模型生成图像之间的光谱不一致性,进一步结合这两种模态的空间共存。(2)通过CLIP编码器引入文本信息的粗粒度特征与像素域中的细粒度人工制品进行语义空间对齐融合。
此外,为了训练和评估扩散生成图像检测器,作者创建了一个全面的扩散生成数据集,其中包括通过在Stable Diffusion和GLIDE上训练生成的图像。
总之,本文的主要贡献有几点:
- 作者提出了一种名为Trinity Detector的新伪造检测方法,它利用注意力机制融合频域和文本辅助视觉内容进行扩散图像伪造检测。
- 作者提出了一个多光谱通道注意力融合单元(MCAF),通过自适应融合不同频段来提取真实图像与扩散模型生成图像之间的光谱不一致性。
- 作者生成了一个基于扩散模型的图像文本对数据集,用于对扩散生成图像检测器进行基准测试。
- 大量实验表明,作者的方法在扩散生成图像上表现出色,具有强大的泛化能力和优秀的鲁棒性。
2 Related Work
Diffusion Model Image Generation
受到非平衡热力学的启发,Ho等人[7]提出了一代新的范式,即去噪扩散概率模型(DDPMs),这些模型一出现就与PGGAN[8]的性能相媲美。从那时起,越来越多的研究者开始关注扩散模型。Song等人[9]将DDPM推广到通过一类非马尔可夫扩散过程进行去噪的隐式模型(DDIMs),这使得在较少的采样步骤中产生更多高质量的样本。
后来的ADM[10]发现了一种更有效的架构,通过分类器引导进一步实现了与其他生成模型相比的最先进性能。LDM[11]通过交叉注意力机制调节输入扩散模型,并 Proposal 引入带有潜在空间的潜在扩散模型。近期流行的Stable Diffusion v1和v2基于LDM,并进一步改进以达到在文本到图像生成中惊人的性能。同期发布的DALLE和DALLE2利用先验模型根据CLIP[12]生成输入文本的图像嵌入,然后通过使用基于扩散的解码器从这个嵌入中生成图像。
Fake Image Detection Techniques
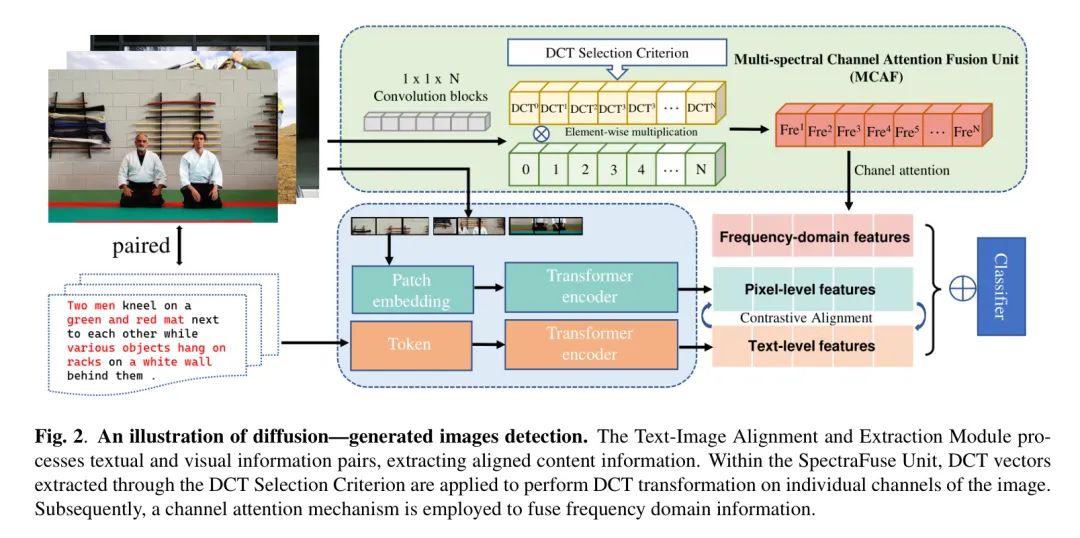
图2:扩散生成图像检测的说明。 文本-图像对齐与提取模块处理文本和视觉信息对,提取对齐的内容信息。在SpectraFuse单元中,通过DCT选择准则提取的DCT向量被用于对图像的单个通道执行DCT变换。随后,采用通道注意力机制来融合频域信息。
在过去的几年里,生成图像检测已经得到了广泛的研究。早期的研究者聚焦于伪造图像篡改边界上的细微变化,基于边界伪迹和统计特征的变化来确定图像的真实性[13][14],Wang等人[15]使用监控神经元对GAN生成的图像进行法医检查。然而,他们忽视了对于不可见生成模型的一般化能力,除了空间伪迹检测外还有基于频率的方法。随后,Frank等人[16]提出在频域中,由于生成器在生成图像时存在上采样操作,GAN具有特殊的纹理。然而,随着扩散建模的快速发展,一个用于检测扩散模型生成图像的通用且健壮的检测器尚未被开发出来。
作者注意到,扩散生成图像检测问题也在一些近期作品中被提出,例如,指出了由于缺乏对目标和表面的显式3D建模导致阴影和反射图像不对称的问题[17]。还有一些基于预训练的文本图像检测的工作,但它们并未提出伪造图像检测技术发展的新范式,仅仅是简单利用了现有工作的几种[6]。
还有一些论文通过测量输入图像与预训练的扩散模型重建的图像之间的误差来进行检测[18],但这种性能可能会受到扩散模型的影响,因为不同的扩散模型可能会产生不同大小的重建误差,需要提出一些更一般化的方法,考虑到当前扩散模型的激增。与它们不同,作者的工作专注于探索一个可泛化的检测器,该检测器可应用于大规模扩散模型。
3 Method
在本论文中,作者提出了一种名为Trinity Detector的新方法,用于检测扩散生成的图像。本节的其余部分组织如下:首先,作者简要回顾了DDPM和DCT;然后,作者详细介绍了Trinity Detector用于检测扩散生成图像的细节;最后,作者介绍了一个新的数据集,即扩散生成图形对数据集,用于训练和评估扩散生成图像检测器。
Denoising Diffusion Probabilistic Models (DDPMs)
DDPMs通过模拟涉及两个马尔可夫链的随机扩散过程来生成图像:一个正向链将数据扰动为噪声,一个反向链将噪声转换回数据。正向链通常是手动设计的,将任何数据分布转换为一个简单的先验分布,而反向链的马尔可夫链通过用深度神经网络参数化过渡核来学习,以反转前者。通过最初从一个先验分布中抽样一个随机向量,然后通过一个反向马尔可夫链进行祖先抽样,生成新的样本。
在正向链过程中,数据分布 $x_{0}\sim q(x_{0})$ 通过过渡核 $q(x_{t}\mid x_{t-1})$ 通过一个马尔可夫过程进行转换,定义为:
$q(x_{1},\ldots,x_{T}\mid x_{0})=\prod_{t=1}^{T}q(x_{t}\mid x_{t-1}), \tag{1}$
在DDPMs中,这个转换核通常是通过添加高斯扰动来设计的,方法是抽样高斯向量 $\epsilon\sim\mathcal{N}(0,I)$ 并应用转换。最后,$x_{t}$ 近似为一个高斯分布,即 $x_{t}\sim q(x_{T})\quad:\int q(x_{T}\mid x_{0})q(x_{0})\,dx_{0}\approx\mathcal{N}(x_{T};0,I)$
反向过程也被表征为一个马尔可夫链:
$p_{\theta}(x_{t-1}\mid x_{t})=\mathcal{N}(x_{t-1};\mu_{\theta}(x_{t},t),\Sigma _{\theta}(x_{t},t)), \tag{2}$
扩散模型利用一个网络 $\Phi(\cdot)$ 来建模真实分布 $p_{\theta}(x_{t-1}\mid x_{t})$,其中 $\theta$ 表示模型参数。相应的近似分布 $q(x_{t-1}\mid x_{t})$ 通常由一个神经网络参数化。整体简化的优化目标包含一个抽样和去噪过程,表述如下:
$L_{\text{sim}}(\theta)=\mathbb{E}_{t,x_{0},\epsilon}\left[\left\|\epsilon- \epsilon_{\theta}(\sqrt{\alpha t}x_{0}+\sqrt{1-\alpha t}\epsilon,t)\right\|^{ 2}\right], \tag{3}$
Discrete Cosine Transform (DCT)
通常,二维(2D)离散余弦变换(DCT)的基础函数为:
$B_{i,j}^{h,w}=\cos\left(\frac{\pi h}{H}\left(i+\frac{1}{2}\right)\right)\cos \left(\frac{\pi w}{W}\left(j+\frac{1}{2}\right)\right), \tag{4}$
因此,二维DCT可以表示为:
$f_{h,w}^{2d}=\sum_{i=0}^{H-1}\sum_{j=0}^{W-1}x_{i,j}^{2d}B_{i,j}^{h,w}, \tag{5}$
$s.t.h\in\{0,1,\ldots,H-1\}$, $w\in\{0,1,\ldots,W-1\}$
在这里,$\mathbf{f}^{2d}\in\mathbb{R}^{H\times W}$ 表示2D DCT频谱,$\mathbf{x}^{2d}\in\mathbb{R}^{H\times W}$ 是输入,$H$ 是 $\mathbf{x}^{2d}$ 的高度,$W$ 是 $\mathbf{x}^{2d}$ 的宽度。相应地,二维DCT的逆可以表示为:
$x_{i,j}^{2d}=\frac{1}{H}\sum_{h=0}^{H-1}\sum_{w=0}^{W-1}f_{h,w}^{2d}B_{i,j}^{ h,w}, \tag{6}$
$s.t.i\in\{0,1,\ldots,H-1\},j\in\{0,1,\ldots,W-1\}$.
Trinity Detector
作者发现,与真实图像相比,扩散模型生成的图像在频域信息分布上有显著差异。为了解决这个问题,Trinity Detector利用了一种多光谱通道注意力融合单元(MCAF),它利用通道注意力在频域建模和处理通道。这增强了频域特征的表现力,然后与由预训练编码器提取的图像文本特征进行融合。在此基础上,Trinity Detector赋予了区分扩散生成图像与真实图像的判别性属性。总的来说,作者的检测过程如公式7所示,其中$\widetilde{\phi}_{\text{Text}}$和$\widetilde{\phi}_{\text{Image}}$表示在语义空间中提取和对齐文本图像,而$\phi_{\text{Frequency}}$是基于通道注意力机制的自适应融合,以提取多波段频域信息。
$\text{Feature}= \widetilde{\phi}_{\text{Text}}(\text{Text})\oplus\widetilde{\phi} _{\text{Image}}(\text{Image}) \tag{7}$ $\oplus\text{Attention}_{\text{Channel}}(\phi_{\text{Frequency}}( \text{Image})).$
MCAF 为了增强通道压缩并引入更多信息,作者提出了多光谱通道注意力融合单元(MCAF),它将频谱提取扩展到2D DCT的更多频谱成分,从2D DCT的多个频谱成分压缩信息。
最初,通过卷积沿通道维度将输入图像划分为多个部分,表示为$[X_{0},X_{1},\dots,X_{n-1}]$,$X_{i}\in\mathbb{R}^{C^{\prime}\times H\times W},\quad i\in\{0,1,\dots,n-1\}$。对于每个部分,根据DCT选择标准,在选定的频谱成分上应用2D DCT变换。这作为频域通道注意力,表示如下:
$\begin{split} Freq_{i}=&\sum_{h=0}^{H-1}\sum_{w=0}^{W -1}X_{:,h,w}^{i}B_{h,w}^{u_{i},v_{i}}\\ &\text{s.t. }i\in\{0,1,\dots,n-1\}\end{split}, \tag{8}$
整个SpectraFuse过程可以表达为:
$\begin{split} Freq&=FreqAttention\{cat([Freq_{0}, \dots,Freq_{n}])\}\\ &=sigmoid(fc(cat([Freq_{0},\dots,Freq_{n}])))\end{split}, \tag{9}$
其中,整个过程可以看作是提取和压缩多通道频域特征,作者的方法将原始关注特定频域的方法扩展到包含多个频谱成分的框架。
DCT选择标准 为了实现多光谱通道注意力,作者采用了Qin等人[19]提出的标准,包括FcaNet-LF(低频)、FcaNet-TS(两步选择)和FcaNet-NAS(神经架构搜索)。通过神经网络探索寻找通道注意力的最佳频谱成分。这部分频谱成分可以表示为:
$\begin{split} Freq_{nas}^{i}=\sum_{(u,v)\in O}\frac{\exp(\alpha(u,v))}{\sum_{(u^{\prime},v^{\prime})\in O}\exp(\alpha(u^{\prime},v^{\prime}))} DCT_{2D}^{u,v}(X_{i}),\end{split} \tag{10}$
图像-文本内容提取模块 结合CLIP展示的强大的文本-图像特征提取和对齐能力,作者的方法策略性地采用了其预训练的文本-图像编码器。利用这个预训练编码器促进了图像特征和语义信息的深层提取和融合。具体来说,作者使用Vit-32作为图像编码器,使用 Transformer 编码器处理文本,创建了一个连贯的多模态表示。
这种综合策略不仅增强了特征提取,而且促进了语义信息的更深层次整合,为作者的 Proposal 方法的有效性和多样性提供了提升。
TxtDiffusionForensics: Dataset for Evaluating Diffusion-Generated Image Detectors
由于缺乏用于从扩散模型生成假图像的公开数据集,本文制作了TxtDiffusion-Forensics数据集,该数据集包括一个扩散模型及其相应的文本对。作者从Flickr30K和MSCOCO公开数据集中选择文本提示,并使用稳定的扩散模型和GLIDE模型生成合成图像。
4 Experiment
在本节中,作者首先描述实验设置,然后提供大量的实验结果来证明作者方法的优势。
Experimental Setup
数据预处理 所有实验都是在作者的TxtDiffusionForensics数据集上进行的。作者随机选择了5000张真实图像和5000张合成图像,每张都配有相应的文本提示,用于训练数据集。用于评估混合检测模型性能的评估测试集由三部分组成。一个数据集由StyleGAN生成,另外两个分别由稳定扩散和GLIDE模型生成。在评估模型性能时,作者采用了分类准确度(ACC)。
** Baseline 方法** 为了验证作者提出方法卓越的性能,作者选择了几种在多种数据集上取得优秀结果的最先进方法进行比较:
CNNDetection [2]:这种方法引入了一种由卷积神经网络(CNN)生成的图像检测模型。该模型在特定的CNN数据集上进行训练,并显示出对其他由CNN生成的图像的泛化能力。
GANDetection [20]:通过在ProGAN和StyleGAN上进行训练,这种方法在泛化方面取得了显著的成功。
DiffusionDetection:DIRE [18]使用预训练的扩散模型来衡量输入图像与重建图像之间的误差。DE-FAKE [6]通过CLIP预训练模型结合图形和文本内容,然后在分类器上进行分类。
Comparison to Existing Detectors
在本研究中,作者使用了从官方仓库获取的预训练权重来评估CNNDetection、GANDetection和DiffusionDetection在作者的精选数据集上的性能。由于DE-FAKE方法尚未开源,作者按照原文中的方法在作者的数据集上复现它。
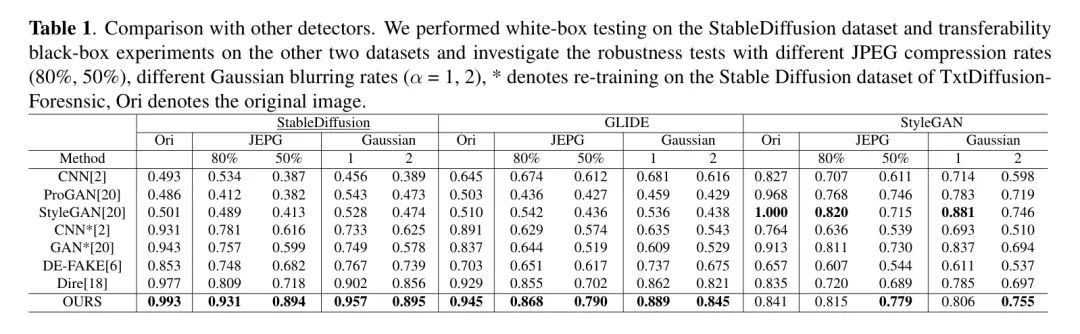
定量结果详见表1。值得注意的是,现有的检测器在处理扩散生成的图像时性能显著下降,准确率(ACC)低于60%。为了解决这一限制,作者使用了扩散生成的图像作为额外的训练数据,并对CNNDetection和GANDetection进行了重新训练。重新训练后的模型在检测由训练期间使用的相同扩散模型生成的图像时,表现出了显著的改进。然而,当面对训练期间未遇到的扩散模型时,它们的性能仍然不尽如人意。相比之下,作者提出的方法,即Trinity Detector,展示了卓越的泛化能力。
Robustness Assessment
除了对未知生成模型的泛化能力之外,对未知扰动的鲁棒性也是一个普遍关注的问题,因为实际上,图像通常会被各种类型的退化所干扰。在这里,作者评估了检测器在两种类型的扰动(即高斯模糊和JPEG压缩)中的鲁棒性。在扰动中加入了高斯模糊($\sigma=1,2$)和JPEG压缩(质量=80%,50%)。作者探索了 Baseline 方法和作者提出的Trinity检测器的鲁棒性。结果展示在表1中。作者观察到,在每一级高斯模糊和JPEG压缩下,作者的DIRE都取得了更好的性能。
Ablation Study
根据第3.2节的描述,作者引入了多光谱通道注意力融合单元(MCAF)。在本节中,作者首先对模块进行详细的消融分析,通过训练仅考虑文本和图像内容的检测器来评估并比较其性能。考虑到并非所有伪造图像都包含文本描述,作者对文本提取单元进行了消融实验,并在使用BLIP进行文本生成的情况下进行了相应的实验。具体结果如表2所示,与所有消融检测器相比,Trinity检测器的性能更优。同时,无论文本是自然语言文本还是BLIP生成的文本,它都比没有文本的检测器表现出更好的结果。
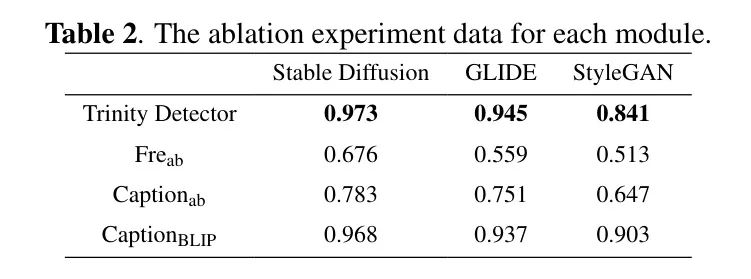
这表明,将频域信息与粗粒度文本和细粒度视觉内容相结合,可以有效放大伪造图像与真实图像之间的差异,从而提高对扩散模型生成的伪造图像的检测效果。
5 Conclusion
在本论文中,作者的目标是开发一个通用检测器以区分由扩散模型生成的图像。为了应对这一挑战,作者引入了Trinity检测器方法。这种方法基于观察,即由扩散模型生成的图像在频域中表现出显著的缺陷。因此,作者引入了一个多光谱通道注意力融合单元,该单元通过自适应通道注意力机制自适应地融合真实图像和由扩散模型生成的图像的不同频段,以提取它们的光谱不一致性,从而区分真实图像和伪造图像。广泛的实验验证了所提出的Trinity检测器方法在检测由扩散模型生成的图像方面,与其他方法相比具有更好的检测性能、鲁棒性和泛化能力。
参考
[1].SUMCHOINOISINIFHL.daSUMAMIH)PUNAF2OLHTASYHSWSINYHMHW NOIINHNDWy UHXHHOMGUAINH.









