
1.展讯通信“AI模型更新方法及通信装置”专利公布
2.京东方“一种光电子集成基板及其制作方法、光电子集成电路”专利获授权
3.京东方“背光模组及显示装置”专利获授权
4.从德国到伦敦 InterDigital与联想的FRAND之战
5.北京大学集成电路学院/集成电路高精尖创新中心共6篇论文入选CICC 2024会议论文
1.展讯通信“AI模型更新方法及通信装置”专利公布
天眼查显示,展讯通信(上海)有限公司“AI模型更新方法及通信装置”专利公布,申请公布日为2024年5月7日,申请公布号为CN117997738A。
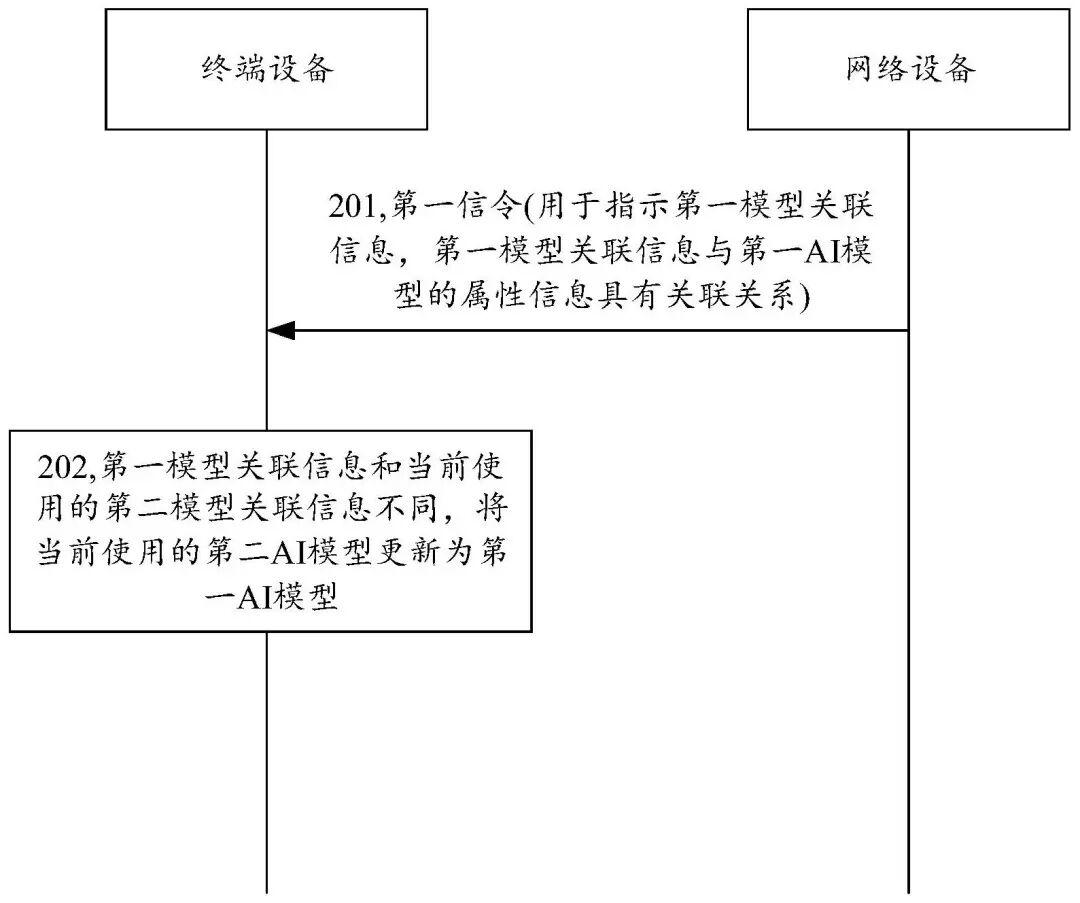
本申请提供一种AI模型更新方法及通信装置,该方法可包括:接收来自网络设备的第一信令,第一信令用于指示第一模型关联信息,第一模型关联信息与第一AI模型的属性信息具有关联关系;第一模型关联信息和当前使用的第二模型关联信息不同,将当前使用的第二AI模型更新为第一AI模型。采用本申请,网络设备可通过信令触发终端设备更新AI模型,使得终端设备可以快速地更新AI模型,从而有助于提高通信效率。
2.京东方“一种光电子集成基板及其制作方法、光电子集成电路”专利获授权
天眼查显示,京东方科技集团股份有限公司近日取得一项名为“一种光电子集成基板及其制作方法、光电子集成电路”的专利,授权公告号为CN113571536B,授权公告日为2024年5月7日,申请日为2021年7月26日。
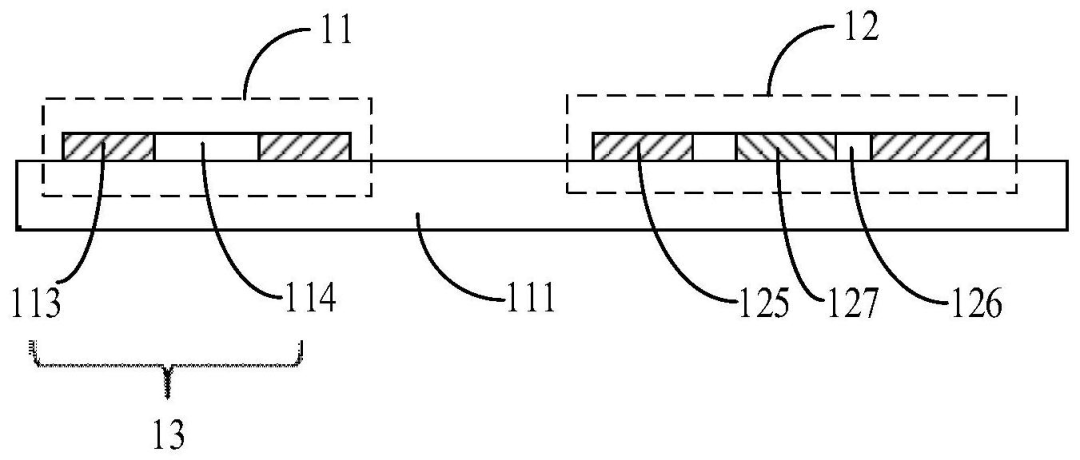
本申请实施例提供了一种光电子集成基板及其制作方法、光电子集成电路。该光电子集成基板包括:衬底、电子元件和光学元件,电子元件位于衬底一侧,包括薄膜晶体管,薄膜晶体管包括半导体有源层;光学元件位于衬底一侧,包括光电二极管,光电二极管包括N型半导体层、本征半导体层和P型半导体层,N型半导体层、本征半导体层和P型半导体层均与半导体有源层同层设置。本申请实施例提供的显示基板的光电子集成基板光电二极管与薄膜晶体管的制作工艺兼容性较高,能够减少mask的数量,降低制造成本,并且可以在确保蓝光信号光吸收的基础上,减少对长波长环境光的吸收,增强光电二极管的光谱选择性,有利于降低误码率。
3.京东方“背光模组及显示装置”专利获授权
京东方科技集团股份有限公司近日取得一项名为“背光模组及显示装置”的专利,授权公告号为CN220913481U,授权公告日为2024年5月07日,申请日为2023年8月30日。
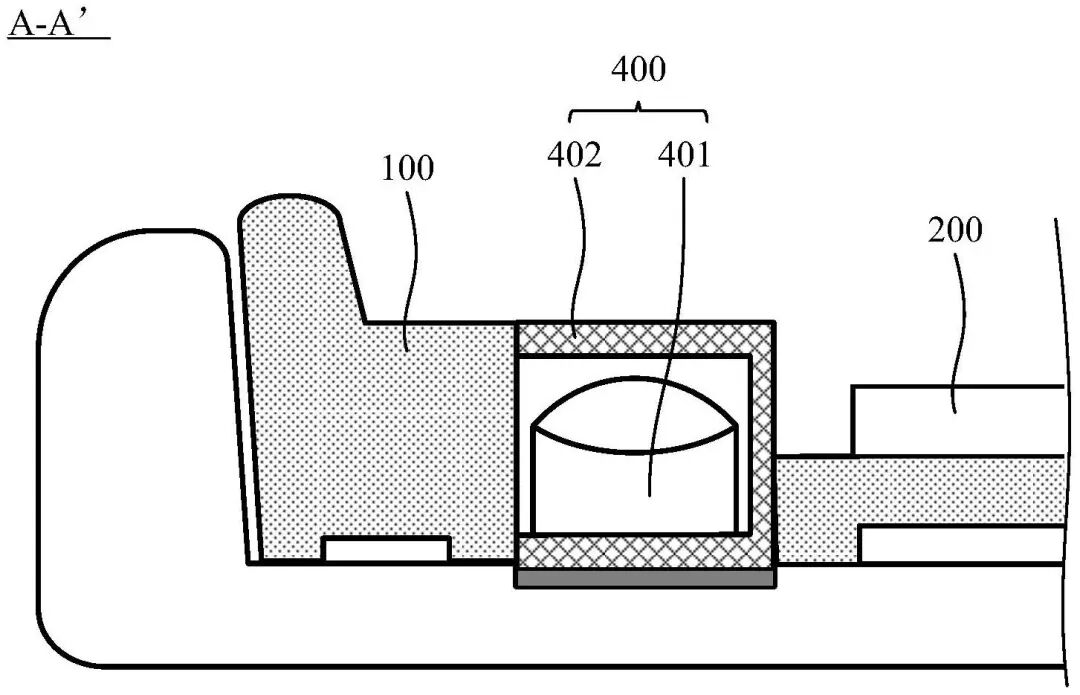
本申请公开了一种背光模组及显示装置,属于显示技术领域。背光模组包括:框体,以及位于框体内的导光板、侧入式的光源和功能组件。通过将功能组件集成在框体内,使得背光模组不仅具有向液晶显示面板提供光源的功能,还具有传感器的功能。这样,将这种背光模组集成在显示装置内后,无需在显示装置的正面预留额外用来放置传感器的区域。进一步的,由于框体和支撑架均可以用于支撑液晶显示面板,因此,无需在框体中设置宽度较大的支撑台来支撑液晶显示面板,便可以保证液晶显示面板与背光模组之间能够稳定的连接。如此,可以有效的降低显示装置的边框,从而可以进一步的提高显示装置的屏占比。
4.从德国到伦敦 InterDigital与联想的FRAND之战
5月初,InterDigital获得了慕尼黑地区法院对联想的禁令,现在,两家公司的全球斗争中心已经转移到伦敦,6月10日,英国上诉法院将审查高等法院法官詹姆斯·梅勒做出的影响深远的FRAND裁决。
据悉,5月2日,慕尼黑地区法院裁定联想不得再在德国销售侵犯InterDigital欧洲专利EP 2127420B1的移动设备。法院还将联想列为不情愿的被许可方,尽管联想已经提交了许可邀约。现在,两个对手将在即将在伦敦开始的FRAND审判中再次面对面。
其实一审裁决对InterDigital来说是一个巨大的成功,因为这是该公司在德国对联想提起的唯一诉讼。InterDigital尚未强制执行该判决,如果这样做,联想将不能在德国销售具有4G和5G功能的平板电脑、智能手机和个人电脑,同时还要支付损害赔偿金。
联想在自己的新闻声明中表示,“我们尊重慕尼黑法院的裁决,但对此结果不认可,因为我们认为InterDigital违反了自己的法律义务,即按照FRAND条款将其技术许可给联想或我们的第三方供应商。”联想宣布,该公司将继续争取许可谈判的透明度,并反对那些为其专利组合寻求过高费率的公司。“我们期待着下一阶段的诉讼和我们的上诉。”
关于集微知产
“集微知产”由曾在华为、富士康、中芯国际等世界500强企业工作多年的知识产权专家、律师、专利代理人、商标代理人以及资深专利审查员组成,熟悉中欧美知识产权法律理论和实务。依托爱集微在ICT领域的长期积累,围绕半导体及其智能应用领域,在高价值专利培育、投融资知识产权尽职调查、上市知识产权辅导、竞争对手情报策略、专利风险预警和防控、专利价值评估和资产盘点、贯标和专利大赛辅导等业务上具有突出实力。在全球知识产权申请、挖掘布局、专利分析、诉讼、许可谈判、交易、运营、一站式托管服务、专利标准化、专利池建设等方面拥有丰富的经验。我们的愿景是成为“ICT领域卓越的知识产权战略合作伙伴”。
5.北京大学集成电路学院/集成电路高精尖创新中心共6篇论文入选CICC 2024会议论文
近日,2024年定制集成电路大会(CICC)在美国科罗拉多州丹佛举行。在本届CICC上,北京大学集成电路学院/集成电路高精尖创新中心共有6篇高水平论文入选,并有博士生李杰的高速ADC芯片论文荣获本届大会杰出学生论文奖。部分师生赴美参加了此次盛会,向国际集成电路设计领域的同行展示了北京大学最新的研究成果。上述6篇论文内容涉及高速ADC芯片、高能效电容传感器读出芯片、存内计算芯片、通用AI加速芯片等前沿领域。论文的详情如下:
1. 高速模数转换器ADC芯片,喜获杰出学生论文奖
高速模数转换器是高速通信系统中的重要模块。对于通信速率要求的提升同样对模数转换器的转换速率提出了更高的要求。
针对以上瓶颈,北京大学集成电路学院沈林晓研究员课题组(黄如院士-叶乐博雅特聘教授团队)提出了一款利用比较器亚稳态信息提高分辨率和加快转换速率的逐次逼近型模数转换器。比较器亚稳态的存在是限制逐次逼近模数转换器速率提升的一个因素。本工作则利用比较器亚稳态的时间信息来获得两位的分辨率,在降低了闪烁码出现概率的同时加速了整体的转换速率。而针对环境变化的影响,本工作提出了一种片上自适应的时间校准模块。
基于上述电路层面的创新,课题组研制了一款基于22nm CMOS工艺的高速高能效的模数转换器芯片。该芯片在1GS/s的采样率下实现了47.2dB SNDR的精度和4.15mW的功耗,在相近分辨率的单通道模数转换器中达到了较高的精度和保持了较高的能效(22.23fJ/conv.-step FoMw)。
该工作以An 8b 1GS/s SAR ADC with Metastability-based Resolution/Speed Enhancement and Background Calibration Achieving 47.2dB SNDR at Nyquist Input为题,发表于今年CICC,并获得了当年的杰出学生论文奖 (2024 Michael A. Zachariah Outstanding Student Paper Award),由文章第一作者北京大学集成电路学院博士生李杰进行宣讲,文章的通讯作者是沈林晓研究员和叶乐博雅特聘教授。
2. 深度可分离神经网络存内计算处理芯片
边缘端人工智能设备快响应、长续航和可便捷的应用需求对芯片硬件的能量效率和面积效率提出了挑战。
北京大学集成电路学院王源教授-唐希源研究员团队首次提出了近存计算与存内计算混合的新型计算架构,针对深度可分离卷积计算,实现了国际领先的能量效率和面积效率。在电路方面,该技术缩短参数访存距离,提升系统的能量利用率。在架构方面,提出输入激活值与输出激活值缓存空间共享的数据流设计,提升系统对存储资源的空间利用率;提出针对深度卷积计算的阵列内自主更新计算模式,提升系统对存储资源的时间利用率。
基于上述创新技术,课题组研制了一款基于28nmCMOS工艺的深度可分离神经网络存内计算处理芯片。在8比特量化的MobileNet-V2模型对CIFAR-10数据集进行推理的测试中,对于深度可分离卷积计算的性能,该芯片能够达到17.2 TOPS/W的能量效率和1.14 TOPS/mm2的面积效率,实现92.47%的推理精度。该芯片突出的能量效率和面积效率在边缘端智能设备中极具应用前景。
该工作以MixCIM: A Hybrid-Cell-Based Computing-in-Memory Macro with Less-Data-Movement and Activation-Memory Reuse for Depthwise Separable Neural Networks为题,发表于今年CICC,文章第一作者北京大学集成电路学院博士生乔鑫进行宣讲,北京大学集成电路学院博士后宋嘉豪为共同一作,通讯作者为唐希源研究员和王源教授。
3.高能效浮点数字存算一体芯片
随着边缘端智能的发展,对芯片的算力、能效、和准确率都提出了更高的要求。然而目前的浮点数字存算一体AI芯片仍然存在数字逻辑电路开销大的问题,限制其应用潜力。
北京大学集成电路学院唐希源研究员团队首次提出了一步计算浮点数字存算一体芯片,该芯片在算法层面采用无乘法的卷积核,并定制了计算电路实现单周期的浮点计算,大幅度降低面积和功耗。同时,课题组提出了输入-权重联合对齐数据流,简化了预对齐移位电路的复杂度。此外,课题组还提出了轻量化的片上模型微调电路设计,实现片上模型更新。基于此,课题组研制了一款基于28nm COMS工艺的浮点数字存算一体芯片,并对该芯片的能量效率和面积效率进行测试。在输入和权重为BF16的精度下,芯片能够达到128TFLOPS/W的能量效率和7.02TOPS/mm2的面积效率,达到了同类工作的国际领先水平。
该工作以A 28nm 128TFLOPS/W Computing-In-Memory Engine Supporting One-Shot Floating-Point NN Inference and On-Device Fine-Tuning for Edge AI为题,发表于今年CICC,文章的第一作者是北京大学集成电路学院博士生刁海康,文章的通讯作者是唐希源研究员。
4. 高能效电容-数字转换器芯片
电容-数字转换器芯片被广泛应用于健康医疗、运动监测等多种新兴物联网应用中。新兴应用对其精度、转换延迟和能效都提出了愈发严格的需求。
北京大学集成电路学院王源教授-唐希源研究员团队研制了一款增量型缩放式电容-数字转换器芯片。在架构方面,该芯片采用了SAR+二阶时间域ΔΣ的缩放式结构。二阶ΔΣ环路利用了带有串联电阻的Gm-C积分器,实现了低成本的前馈路径,保证了宽测量范围下的稳定性和较高的量化精度。在热噪声方面,该芯片采用基于浮动反相放大器的采样热噪声消除技术,突破其限制的精度瓶颈3.8dB。此外,该芯片设计了死区操作将CT环路转化为DT工作,解决了过量环路延迟问题,提供了一个可抵御环路系数变化的高鲁棒性ΔΣ环路。
基于上述技术,课题组研制了一款基于28nm CMOS工艺的电容-数字转换器芯片。该芯片实现了0-5.5pF电容测量范围,信噪比达到84.3dB。在所有高精度(80dB以上)电容-数字转换器中实现了最低的转换延迟(5.3us)和领先的能效水平(181.8dB FoMs)。
该工作以A 181.8dB FoMs Zoom Capacitance-to-Digital Converter with kT/C Noise Cancellation and Dead Band Operation为题发表于CICC,文章的第一作者是北京大学集成电路学院博士生申子龙,文章的通讯作者是唐希源研究员和王源教授。
5. 通用AI加速芯片
AI算法的发展引入了越来越多的数据类型。尽管其核心算子依旧为矩阵乘法,但是由于数据特性的不同,其计算模式存在较大的差别,从而导致传统基于统一计算阵列的AI加速芯片无法高效计算现有的AI算法,算力、能效均受到限制。
针对该问题,北京大学集成电路学院黄如院士-叶乐博雅特聘教授团队研制了一款基于稀疏-密集-静态-动态四象限异构张量引擎的通用AI加速芯片。该工作将AI算法中存在的矩阵乘法根据数据的稀疏性与动态性分为密集特征-权重矩阵乘法(FWMM)、稀疏特征-权重矩阵乘法(SpFWMM)、密集特征-特征矩阵乘法(FFMM)、稀疏特征-特征矩阵乘法(SpFFMM),并分别设计了针对性的异构张量引擎。此外,该工作利用了统一存储池技术与多发射技术进一步提升了芯片算力与能效。
基于上述创新,该工作研制了一款基于TSMC 22nm CMOS工艺的通用AI加速芯片。对于GCN模型在PubMed上的推理,该芯片能效达到了0.09mJ/inference,是同类工作ReCIM与TensorCIM的19.56倍与3.47倍,达到了国际领先水平。
该工作以Quartet: A 22nm 0.09mJ/inference Digital Compute-in-Memory Versatile AI Accelerator with Heterogeneous Tensor Engines and Off-Chip-Less Dataflow为题,发表于今年CICC,文章的第一作者是北京大学集成电路学院博士生邱一侃,通讯作者是马宇飞研究员。
6. 脉动式数字域存内计算芯片
基于SRAM的数字域存内计算在执行矩阵-向量乘法方面具有较高的效率和精度。然而,网络模型尺寸与存内计算阵列尺寸之间的不匹配,使得AI算法在基于存内计算的AI芯片上部署时存在利用率受限或权重更新的隐藏开销问题,导致系统无法充分发挥存内计算的优势,总体性能受限。
北京大学集成电路学院黄如教授-叶乐博雅特聘教授团队针对以上问题,提出了一种基于脉动数据流的数字域存内计算架构,通过引入脉动式输入的数据流来支持向量级乘法操作,以提高算法和硬件之间映射的灵活性;同时,课题组提出了二维形式的权重更新策略,通过复用脉动数据通路,实现矩阵形式的二维权重更新。此外,课题组还提出了脉动-广播结合的混合输入模式,进一步提高了阵列的计算灵活性和系统效率。
基于以上技术,课题组采用22nm CMOS工艺完成了流片和原型验证,并进行了性能测试和汇报。在满利用率执行全并行INT8向量乘法操作的情况下,与其他工作相比有效计算能效提升至1.67倍。与单一数据流相比,采用脉动-广播混合输入模式能够得到1.25至2.84倍的总体能效提升。
该工作以S2D-CIM: A 22nm 128Kb SRAM-based Systolic Digital Compute-in-Memory Macro with Domino Data Path Supporting Vector Multiplication and 2-D Weight Update为题,发表于今年CICC,文章第一作者是北京大学集成电路学院博士生武蒙,文章的通讯作者是贾天宇研究员和叶乐博雅特聘教授。
关于CICC
在集成电路芯片设计领域,IEEE固态电路协会(Solid-State Circuits Society)主办的定制集成电路会议(CICC)是IC设计领域重要会议之一,以论文录用率低、作品创新性和实用性强著称,每年吸引全球范围内大量学术界、工业界研发人员的关注和参与。会议内容涉及模拟电路设计、生物医学、传感器、显示器和MEMS,数字和混合信号SoC/ASIC/SIP, 嵌入式存储器件等方面,重点讨论如何解决集成电路设计问题的方法,以提高芯片各项性能指标。(来源: 北京大学)











