第32期文献分享会-BMC Medicine最新文章-基于机器学习识别糖尿病患者
杂志情况

文章情况
研究目的
提出一个机器学习模型DRING(空腹血糖正常个体的糖尿病风险),用于从NFG个体中识别遗漏的糖尿病患者,同时通过特征重要性分析揭示糖尿病的危险因素。
Methods
数据集:研究使用了来自三个中国队列的超过60,000名具有正常空腹血糖(NFG)的个体的体检数据。通过预处理之后,三个数据集D1 D2 D3分别保留61059、369、3247个样本,分别包含603、3、21名糖尿病患者
排除标准和分组:WHO诊断标准:糖尿病患者通过糖化血红蛋白(HbA1c)水平定义,即HbA1c ≥ 48 mmol/mol(或6.5%)。排除缺失值和异常值的样本。根据阈值6.5%的HbA1c水平分为糖尿病组和正常组
数据集特征:所有数据集包含27个体格检查特征,包括性别、年龄、身高、体重指数(BMI)、空腹血糖(FBG)、白细胞计数(WBC)、中性粒细胞(NEU)、中性粒细胞绝对计数(ANC)、淋巴细胞(LYM)、淋巴细胞绝对计数(ALC)、单核细胞(MONO)、单核细胞绝对计数(AMC)、嗜酸性粒细胞(EOS)、嗜酸性粒细胞绝对计数(AEC)、嗜碱性粒细胞(BASO)、嗜碱性粒细胞绝对计数(ABC)、血红蛋自(HGB)、红细胞压积(HCT)、平均红细胞体积(MCW)、平均红细胞血红蛋白(MCH)、红细胞分布宽度(RDW)、血小板(PLT)、平均血小板体积(MPV)、血小板分布宽度(PDW)、血小板减少(PCT)、红细胞计数(RBC)和平均红细胞血红蛋白浓度(MCHC)
模型构建:逻辑回归 随机森林 支持向量机 深度神经网络(DNN)
-
数据不平衡处理:在训练集上采用SMOTE方法对正样本进行过采样
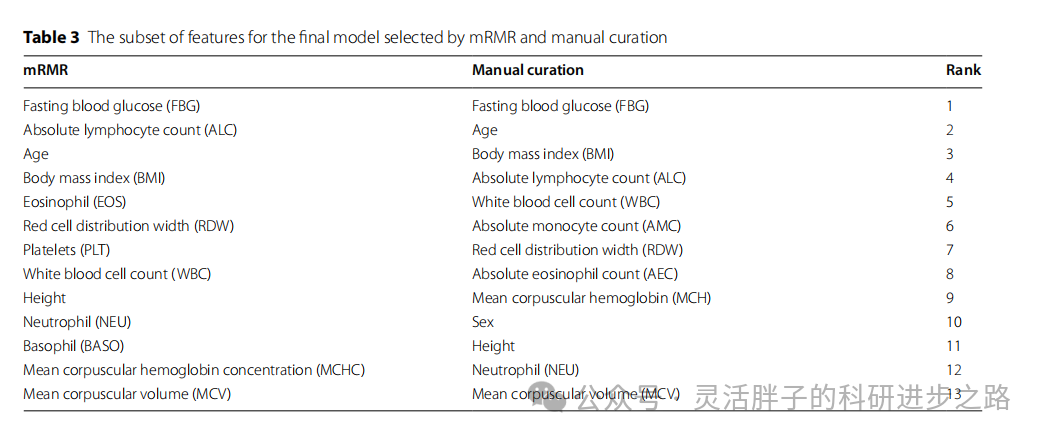
特征选择方式:为了最大限度利用特征的有效信息,同时简化模型,使用了手动管理和最大相关最小冗余(mRMR)来选择关键特征,最终保留了13个特征,并使用LR模型权值系数来衡量每个特征的重要性。
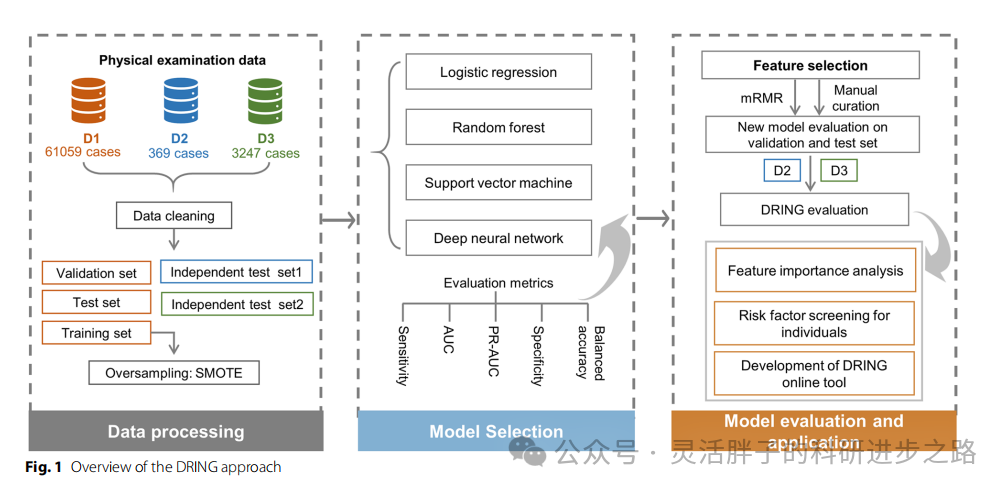
描述性结果
在回顾皖南医学院第一附属医院2015年至2018年间的体检资料时,筛选出了共计61,059例符合特定研究标准的非空腹血糖(NFG)样本。通过对这些样本的深入分析,我们区分了两组个体:一组为伴有糖尿病的NFG患者,另一组则为无糖尿病的健康对照组。对比结果显示,糖尿病组在体质指数(BMI)上平均高出健康组1.08个单位,且其平均年龄显著大于健康组约10.6年。
进一步的数据挖掘揭示了糖尿病组与正常样本之间在多个生理指标上存在显著差异,其中最为突出的五个特征包括:空腹血糖水平(FBG)、患者年龄、体质指数(BMI)、绝对淋巴细胞计数(ALC)以及白细胞计数(WBC)。这些差异在图2中得到了直观的展示,强调了这些指标在糖尿病诊断与风险评估中的重要性。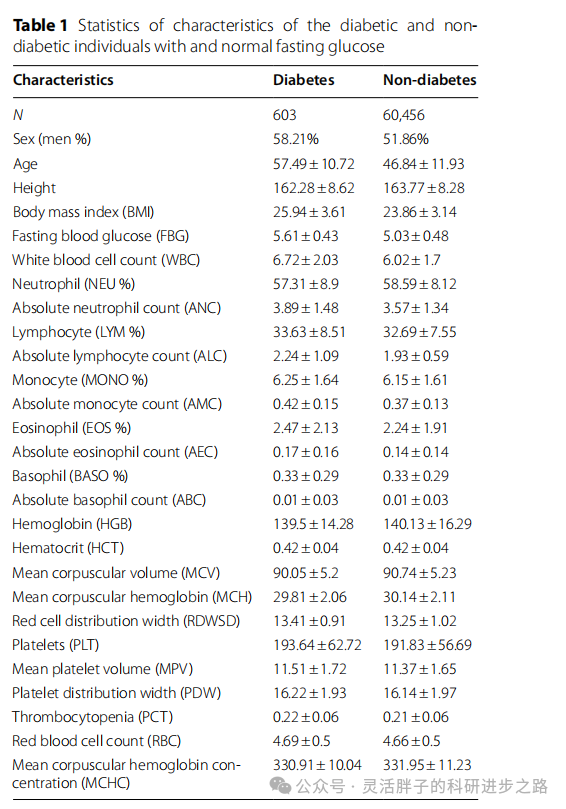
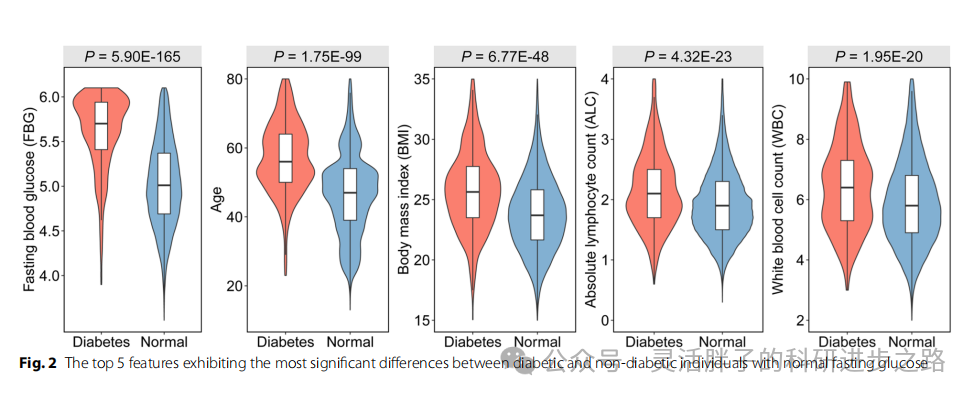
各模型性能
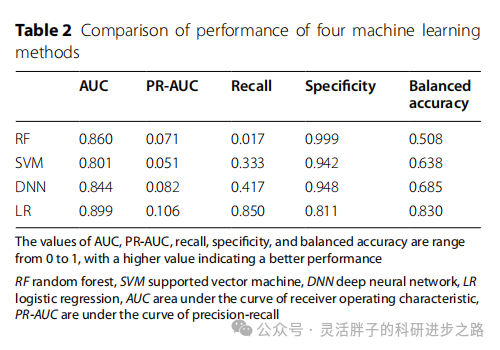
在评估逻辑回归(LR)、随机森林(RF)、支持向量机(SVM)及深度神经网络(DNN)等多种机器学习算法于验证集上的性能时,表2的数据显示,尽管所有模型的精确召回率(PR-AUC)普遍偏低,这主要归因于验证集中糖尿病与正常样本之间显著的不平衡性(超过100倍差异),但逻辑回归模型脱颖而出,其AUC值最高达到0.899,尽管其PR-AUC为0.106。值得注意的是,在PR-AUC、灵敏度及平衡准确度等关键指标上,逻辑回归均显著优于其他考察的模型,因此被选定为构建最终糖尿病预测模型的首选算法。
为了验证逻辑回归模型的稳定性和泛化能力,在训练集上实施了五倍交叉验证,结果显示该模型表现强劲,AUC提升至0.906,PR-AUC显著提升至0.879,灵敏度达到85.9%,平衡准确率也维持在83.4%的高水平。进一步地,在独立的测试集上,逻辑回归模型同样展现了稳健的性能,AUC为0.872,尽管PR-AUC受测试集不平衡性影响较小(0.092),但其灵敏度和平衡精度分别达到了77.9%和79.5%,如图3A和B所示。这些结果表明,结合人口统计学特征与血常规指标,逻辑回归模型能够有效区分糖尿病患者与健康人群,为糖尿病的筛查与诊断提供了有价值的参考。
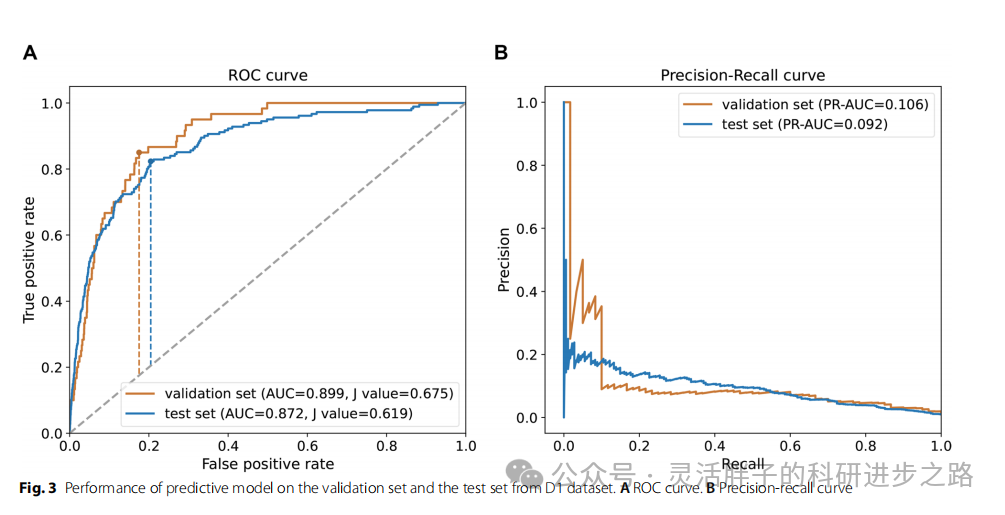
最终模型的特征选择
通过观察相关性热图,我们识别到几组特征之间存在强烈的正相关关系,例如血红蛋白(HGB)与红细胞压积(HCT)、中性粒细胞(NEU)与淋巴细胞(LYM)等,这些高度相关的特征可能会向模型中引入不必要的冗余信息,进而影响模型的决策准确性和稳定性。鉴于此,本研究采取了两种策略来进行特征选择,旨在构建更为精简且高效的预测模型。
首先,采用了基于经验的方法,该方法综合了之前差异性分析的结果与相关性热图的直观展示,经过慎重考虑后,从原始特征集中挑选出了13个关键因素作为模型输入。为了确保实验的一致性和可比性,随后我们实施了最大相关最小冗余法(mRMR),这是一种更为系统化的特征选择方法,旨在寻找与目标变量最大相关且彼此之间最小冗余的特征集。通过应用mRMR算法,我们同样获得了包含13个预测因素的优化特征集。这两种特征选择方法的并行应用,不仅体现了对模型构建严谨性的追求,也为后续分析提供了多重视角下的特征重要性评估。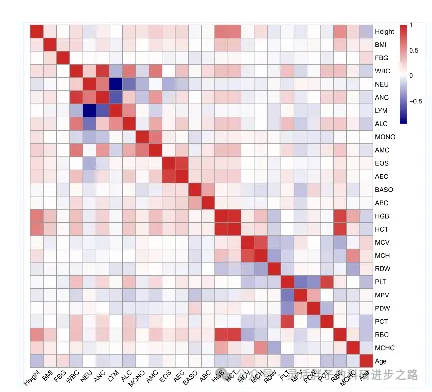
最终模型性能
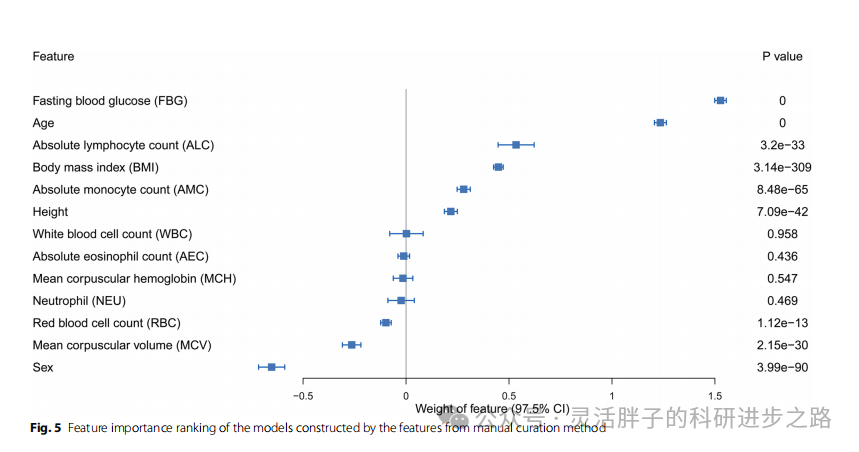
图4反映的是简化模型在测试集和两个外部验证集上的模型性能(备注,由于前述logistic回归最佳,这里用的就只有logistic回归)。可以发现,模型简化后,性能均有所提升,无论是AUC、AUPRC,还是混淆矩阵指标。且可以发现,基于经验法(manual curation)变量构建的模型比mRMR法性能高。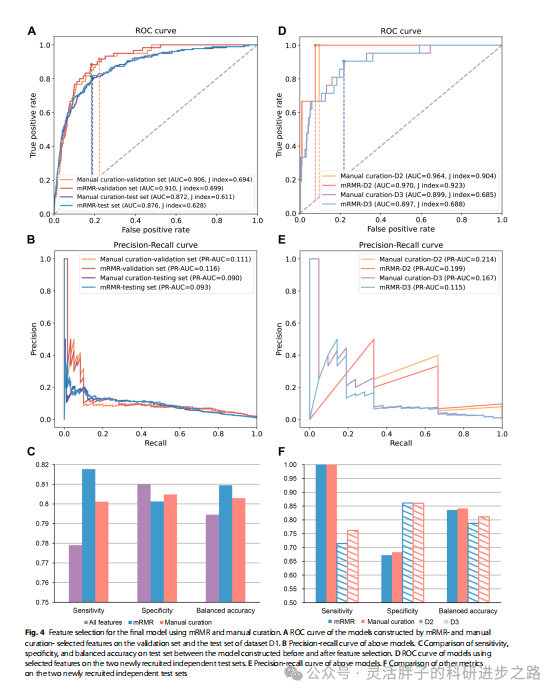
特征重要性排序
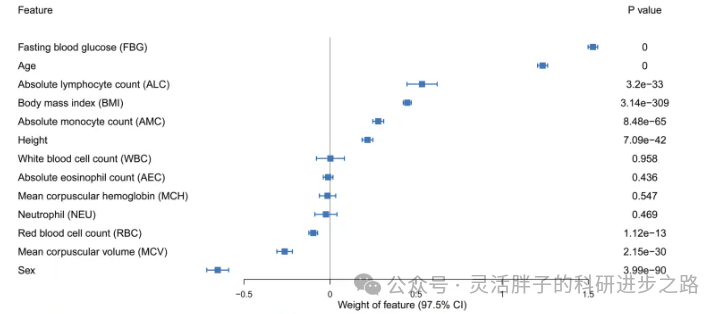
基于上述结果,作者选择了基于manual curation方法构建的logistic回归作为最佳模型,其可解释性结果采用权重系数进行可视化排序。如上图所示,前5个重要因素分别是空腹血糖、年龄、淋巴细胞绝对数、BMI和单核细胞绝对数。有趣的是,本研究观察到性别的重要性甚至超过了BMI,这表明男性和女性患糖尿病的风险存在明显差异。下图为补充分析,即对基于mRMR构建的logistic回归进行可解释性分析,可以发现,前4位变量都是一致的。
个案分析
本研究建立了一个基于排列特征重要性(PFI)原则的个体水平糖尿病危险因素揭示框架,计算了每个特征的贡献大小。作者在文中举了一个例子,该病例来自外部验证集2,其特征如下:绝对嗜酸性粒细胞计数(AEC): 0.23,年龄:69,ALC: 2.29, AMC: 0.51, BMI: 26.04, FBG: 5.76,身高:158.0,平均红细胞血红蛋白(MCH): 29.7, MCV: 89, NEU: 56.50,红细胞分布宽度(RDW): 13,性别:女性,白细胞:7.05。该个体被正确预测为糖尿病患者,概率为0.977,在所有因素中,年龄和空腹血糖是促使该个体发生糖尿病的关键因素。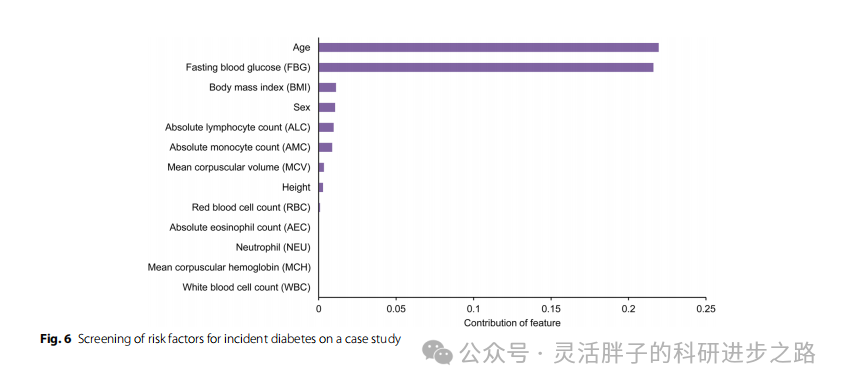
本研究的优势:
这是第一个专门设计的预测模型来识别空腹血糖正常个体中的糖尿病患者,对现有的糖尿病风险预测模型是一个有价值的补充。该模型也被整合到在线工具中,促进了其潜在的临床应用。
本研究的局限性:
1、糖尿病受到种族和环境等多种因素的影响,本研究的方法在中国队列中得到了验证和测试,在其他种群中的表现仍不确定。
2、目前糖尿病风险评估的预测模型多种多样,但由于DRING用于在NFG个体中区分糖尿病患者和健康个体,因此DRING与其他方法之间不具可比性。
3、目前方法的精度较低,受糖尿病患者与正常人分布严重不平衡的影响明显。阳性和阴性样本的比例超过1:100。然而,即使我们的研究纳入了6万多个样本,糖尿病样本的数量也只有600个左右。该比例与现实世界NFG个体中罕见的糖尿病患者是一致的。未来,在预测NFG人群糖尿病风险的模型中引入更多关键特征,如腰臀比、血压和常见生化指标,可能会提高其准确性。
4、进行全面的卫生技术评估是必要的,以促进我们的方法作为糖尿病诊断的决策支持系统。
时间与平台
想要与老师的联系可以联系助教索要腾讯会议密码

 助教微信-程老师
助教微信-程老师本次会议是以下的课程的公开课
基于python的机器学习与模型可解释及影像组学课程-第二期
课程总体设计
本次课程主要涉及基于python的结构化数据的分析及机器学习模型的构建与模型的可解释性方法。另外,由于传统影像组学提取特征后也是结构化数据的处理,将一并讲授。同时,还会讲解影像组学数据的标注与提取。此部分内容主要基于3D slicer软件。
课程目录
| 主题 | 课程内容 |
|---|
| 第一部分、Python 环境构建、基础语法及常见库应用 | 1. conda及Linux基本语法讲解及python环境构建,包和环境的管理
2.python基础语法
3.python数据结构(数组 字典 元祖 集合的概念和作用)、面向对象思维 类的继承
4.重要库的学习和使用,什么场景下使用?(pandasnumpy matplotlib)
5.pandas 库的数据处理和分析:数据读取、清洗、转换、合并、分组和聚合等
6.numpy 库的数值计算和数组操作:数组创建、索引、切片、运算和统计等
7.Matplotlib 库的基本用法及常见 SCl 图表绘制 |
| 第二部分、ChatGPT | 1. chatgpt介绍和使用心得
2.利用chatgpt辅助医学论文SCI画图
3.NLP以及Transformer初步认识和介绍
3. 如何用好chatgpt
- 提示词工程
- 通过chatgpt接口批量抓取数据和处理 |
| 第三部分、Python 机器学习与生存分析 | 1. 机器学习基本概念和算法(包括监督学习和无监督学习方法的应用)
2. 特征选择的方法
3. 机器学习常用的模型
4. 生存分析原理基本介绍
5. Python 机器学习的王者-sklearn库的用法详解
6. 最新机器学习算法的低代码版本-PyCaret库用法详解
7. 常规生存分析方法学实现-lifelines 库详解
8. 基于机器学习/深度学习的生存分析算法的集大成者-PySurvial包用法详解
9. 生存分析文献复现实战 |
| 第四部分、模型可解释 | 1. DeepOmix框架介绍--机器学习及深度学习模型可解释框架
2. DALEX体系-DALEXSHAP/LIME/CAM原理介绍
3. DeepOmix之解释传统机器学习模型
4. DeepOmix之解释深度学习模型
5. 模型可解释性文献复现实战 |
| 第五部分、影像组学 | 1.影像组学概述和高分文章详解
2.基于 pyradiomics 提取特征
3.影像数据的预处理和标准化
4.5. 特征提取和特征选择
5.影像组学模型构建(10种+机器学习)和评估 |
授课老师
1.华为云计算部门:李老师
既往长期就职于华为人工智能 EI 部门, 在参与华为深度学习平台 ModelArts 的开发,独立承担能够支持 pytorch 的相关 API 的开发、实现算法的优化。遵循 Pytorch 框架的设计原则和 API 规范,确保接口的稳定性和易用性。
研究经历
- 医学图像分析与抑郁症诊断的 AI 分析,美国(远程合作)
- 该项目由美国马里兰大学的博士候选人 Naibo Zhang 担任咨询。
- PageRank 算法提取脑部特征信息,并应用 KVM、决策树、支持向量机和加权范数算法进行抑郁症诊断。
- 应用生成对抗网络(GAN)模型扩充数据集,克服了样本量的限制,模型准确率达到 99%。
深度学习模型实践:
- 在百度网盘的去水印模型比赛时基于 PMRID UNet 设计出创新模型,该模型可以实现仅使用层次化通过调节逆瓶颈的深度参数及可分离卷积操作,并且还采用了多阶段的训练策略,最终实现了水印图像的像素级回归预测,且模型的性能和效果大大提高了,最终带领团队荣获了三等奖。
- 在百度网盘的文档超分辨率比赛时,在百度的 paddle 深度学习框架下改进了 SwinIR 模型,在不同的训练阶段设计了不同的参数,从而使浅层特征提取和深层特征提取的时间都达到了最快的速度,最后利用 GPU 进行图片的训练和输出,最终取得了优秀奖。
- 参加了 CVPR 2023 1st foundation model challenge-Track2,用掩码数据建模方法,使用 BEiT-3 预训练模型对Baseline 中的图片编码器进行改进,从而增强了图片与文本之间的匹配能力。该自创模型还使用了 RTMDet 目标检测算法,将车和人分开进行训练,针对其特征进行优化,去除相关无用背景,最终提高了模型跨模态匹配的准确性,拿到了前百分之5的优秀成绩。
- 在 AI studio 云服务器上部署 Vicuina 模型,并独立编写 Gradio web server 的页面,训练自己的数据集,实现了中英文的回复响应。
主要负责分析服务及授课内容
部分图表
模型解释:
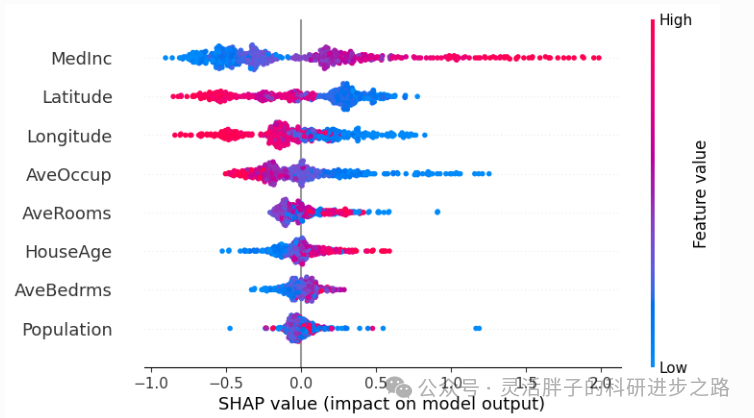

机器学习:
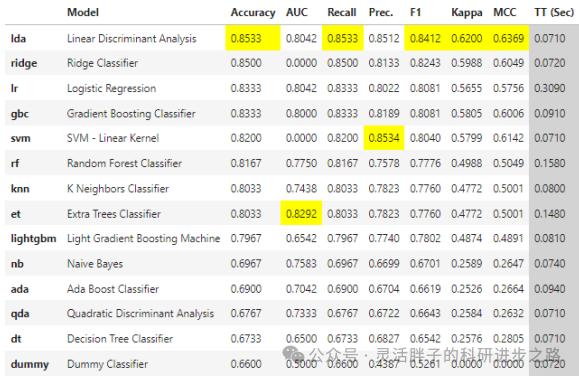
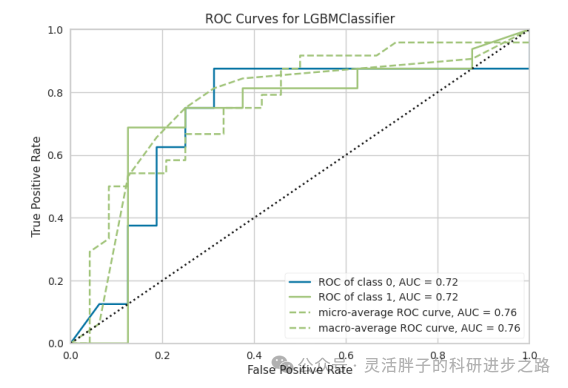
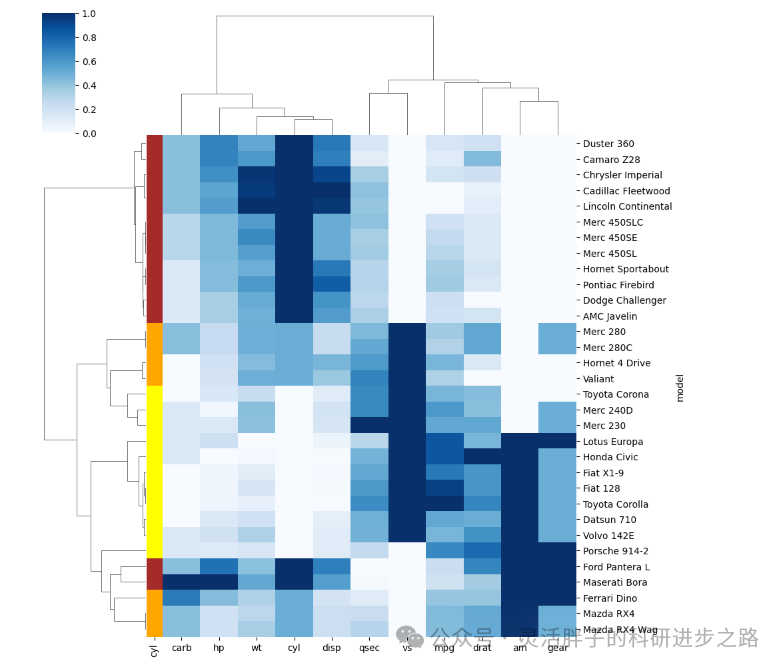
SCI论文图表:
生存分析

 生存模型
生存模型 深度生存模型
深度生存模型


授课形式及时间
授课形式:远程在线实时直播授课。
授课时间:2024年8月开课,总课时不少于30小时,每周利用周末休息时间进行5-8小时的授课,预计5-7周完成所有授课内容。
答疑支持:建立课程专属微信群,1年内课程内容免费答疑。
视频回看:3年内免费无限次回看。
课程售价及售后保证
课程售价:3000元
对公转账等手续务必提前联系助教
承办公司:天企助力(天津)生产力促进有限公司
奖励政策:学员应用所学内容发表IF 10+文章可退还学费(具体要求及流程需要咨询助教)
报名咨询
可联系我的助教进行咨询
 我的助教微信
我的助教微信助教联系电话:18502623993








