本文讲解机器学习的降维部分,包括SVD(奇异值分解)。
1.1 降维概述
1.1.1 维数灾难
维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。
在很多机器学习问题中,训练集中的每条数据经常伴随着上千、甚至上万个特征。要处理这所有的特征的话,不仅会让训练非常缓慢,还会极大增加搜寻良好解决方案的困难。这个问题就是我们常说的维数灾难。
图1-1 维数增加,计算量呈指数增长维数灾难涉及数字分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。在机器学习的建模过程中,通常指的是随着特征数量的增多,计算量会变得很大,如特征达到上亿维的话,在进行计算的时候是算不出来的。有的时候,维度太大也会导致机器学习性能的下降,并不是特征维度越大越好,模型的性能会随着特征的增加先上升后下降。
1.1.2 降维概述
降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维空间,该过程与信息论中有损压缩概念密切相关。同时要明白的,不存在完全无损的降维。
有很多种算法可以完成对原始数据的降维,在这些方法中,降维是通过对原始数据的线性变换实现的。
为什么要降维?主要原因如下:
(1) 高维数据增加了运算的难度。
(2) 高维使得学习算法的泛化能力变弱(例如,在最近邻分类器中,样本复杂度随着维度成指数增长),维度越高,算法的搜索难度和成本就越大。
(3) 降维能够增加数据的可读性,利于发掘数据的有意义的结构。
降维的主要作用有两个:
1.减少冗余特征,降低数据维度
假设我们有两个特征:
:长度用厘米表示的身高;:是用英寸表示的身高。
这两个分开的特征和,实际上表示的内容相同,这样其实可以减少数据到一维,只有一个特征表示身高就够了。很多特征具有线性关系,具有线性关系的特征很多都是冗余的特征,去掉冗余特征对机器学习的计算结果不会有影响。但如果不去掉这些冗余特征,通常会增加计算量,可能会影响机器学习性能。也就是说,降维确保特征之间相互独立。
降维也可以去除数据噪声,可以降低聚类算法的运算开销。
2.数据可视化
降维可以提供一个框架来解释结果。相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有二维或者三维的话,更便于可视化展示。在许多机器学习问题中,降维可以帮助我们将数据可视化,我们便能寻找到一个更好的解决方案。
假使我们有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。
这样做也存在一定的问题,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
t-SNE(t-distributed Stochastic Neighbor Embedding)将数据点之间的相似度转换为概率。原始空间中的相似度由高斯联合概率表示,嵌入空间的相似度由“学生分布”表示。
虽然Isomap,LLE和variants等数据降维和可视化方法,更适合展开单个连续的低维的manifold,但如果要准确的可视化样本间的相似度关系,t-SNE表现更好,因为t-SNE主要是关注数据的局部结构。
1.2 奇异值分解
1.2.1 SVD概述
奇异值分解(Singular Value Decomposition,SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。
SVD可以将一个矩阵分解为三个矩阵的乘积:
一个正交矩阵(Orthogonal Matrix)、一个对角矩阵(Diagonal Matrix)和一个正交矩阵的转置。
主要应用领域包括:
隐性语义分析(Latent Semantic Analysis, LSA)或隐性语义索引(Latent Semantic Indexing, LSI);推荐系统 (Recommender System),可以说是最有价值的应用点;矩阵形式数据(主要是图像数据)的压缩。
1.2.2 SVD 的算法思想
假设矩阵是一个的矩阵,通过SVD是对矩阵进行分解,
那么我们定义矩阵的 SVD 为:
其中是一个的矩阵,是一个的矩阵,除了主对角线上的元素以外全为 0,主对角线上的每个元素都称为奇异值,是一个的矩阵,为的秩。
进行矩阵分解得到:
注意:但是和特征分解不同,SVD 并不要求要分解的矩阵为方阵。
和都是酉矩阵,即满足:。
图1-2可以很形象的看出上面 SVD 的定义:
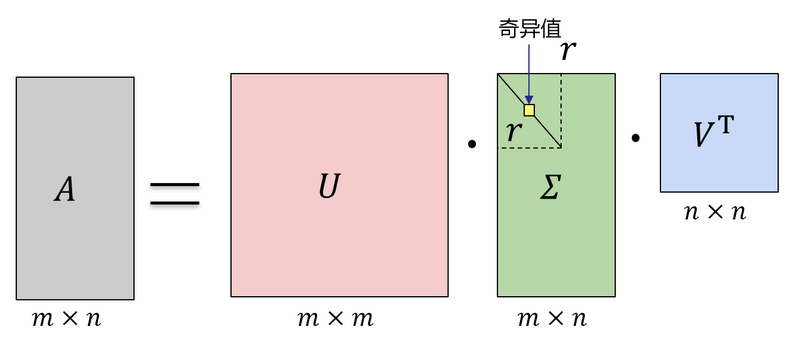
图1-2 SVD的定义那么我们如何求出 SVD 分解后的这三个矩阵呢?
1.矩阵求解
如果我们将和的转置做矩阵乘法,那么会得到的一个方阵
。既然是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
这样我们就可以得到矩阵
的个特征值和对应的个特征向量了。将的所有特征向量组成一个的矩阵,就是我们公式里面的矩阵了。一般我们将中的每个特征向量叫做的左奇异向量。
由于:
上式证明使用了。可以看出的特征向量组成的的确就是我们 SVD 中的矩阵。
2.矩阵求解
如果我们将的转置和做矩阵乘法,那么会得到的一个方阵。既然是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
这样我们就可以得到矩阵的个特征值和对应的个特征向量了。将的所有特征向量组成一个的矩阵,就是我们 SVD 公式里面的矩阵了。一般我们将中的每个特征向量叫做的右奇异向量。
注意:由于
上式证明使用了。可以看出的特征向量组成的的确就是我们 SVD 中的矩阵。
3.矩阵求解
由于奇异值矩阵除了对角线上是奇异值,而其他位置都是 0,那我们只需要求出每个奇异值就可以了。
我们注意到:
则:
由于:
则:
得到:
则:
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵。
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
这样也就是说,我们可以不用来计算奇异值,也可以通过求出的特征值取平方根来求奇异值。
1.2.3 SVD 的算法案例
这里我们用一个简单的例子来说明矩阵是如何进行奇异值分解的。
设矩阵定义为:
则的秩。
首先求出和:
两者都有相同的迹,都是50。
进而求出的特征值和特征向量:
求解得到特征值:,;
由,可以得到奇异值为:,;
特征向量为:和;
接着求出的特征值和特征向量:
同理求得:
,;
和为正交的单位向量:
利用,求奇异值:
最终得到的奇异值分解为:
1.2.4 SVD 的一些应用
SVD分解可以将一个矩阵进行分解,对角矩阵对角线上的特征值递减存放,而且奇异值的减少特别的快,在很多情况下,前甚至的奇异值的和就占了全部的奇异值之和的99%以上的比例。
也就是说,对于奇异值,它跟我们特征分解中的特征值类似,我们也可以用最大的个的奇异值和对应的左右奇异向量来近似描述矩阵。
也就是说:
其中要比小很多,也就是一个大的矩阵可以用三个小的矩阵、、来表示。如图1-3所示,现在我们的矩阵只需要灰色的部分的三个小矩阵就可以近似描述了。

图1-3 SVD的近似计算由于这个重要的性质,SVD 可以用于 PCA 降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于 NLP 中的算法,比如潜在语义索引(LSI)。
下面我们就用一个案例作介绍对 SVD 用于 PCA 降维。
原始图像(矩阵)中共有个元素,取前150个特征,则矩阵可以压缩成这三个矩阵,三个矩阵共有812700个元素。
SVD图像压缩计算过程:
本案例中,原始维度,;
经过SVD分解后的矩阵及维度:
则原始图像压缩后的维度:
如图1-4原始图像(a)和处理后的图像(b)的显示效果,可以看出,尽管图片经过SVD压缩,但图像质量并没有多大损失。

|
|
|---|
| (a) | (b) |
图1-4 原始图像(a)和处理后的图像(b)参考文献
[1] Andrew Ng. Machine Learning[EB/OL]. StanfordUniversity,2014.https://www.coursera.org/course/ml
[2] Hinton G. E., Salakhutdinov R. R. Reducing the Dimensionality of Data with Neural Networks.[J]. Science, 2006.
[3] Jolliffe I T . Principal Component Analysis[J]. Journal of Marketing Research, 2002, 87(4):513.
[4] 李航. 统计学习方法[M]. 北京: 清华大学出版社,2019.
[5] Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning[M]. New York: Springer,2001.
[6] Peter Harrington.机器学习实战[M]. 北京:人民邮电出版社,2013.






