合成生物学技术——设计
Nat Commun. 2024 Aug 27;15(1):7348. doi:
10.1038/s41467-024-51511-6.
多模态深度学习实现了对酶活性位点的高效准确注释。Multi-modal deep learning enables efficient and accurate annotation
of enzymatic active sites.
Wang X(1)(2), Yin X(1)(2), Jiang D(1), Zhao
H(1), Wu Z(1), Zhang O(1), Wang J(1), Li Y(3), Deng Y(4), Liu H(5), Luo P(2),
Han Y(6), Hou T(7), Yao X(8), Hsieh CY(9).
Author information: (1)Innovation Institute
for Artificial Intelligence in Medicine of Zhejiang University, College of
Pharmaceutical Sciences, Zhejiang University, Hangzhou, 310058, Zhejiang,
China. (2)Neher's Biophysics Laboratory for Innovative Drug Discovery, State
Key Laboratory of Quality Research in Chinese Medicine, Macau Institute for
Applied Research in Medicine and Health, Macau University of Science and
Technology, Macao, 999078, China. (3)College of Chemistry and Chemical
Engineering, Lanzhou University, Lanzhou, 730000, Gansu, China. (4)CarbonSilicon
AI Technology Co., Ltd, Hangzhou, 310018, Zhejiang, China. (5)Faculty of
Applied Sciences, Macao Polytechnic University, Macao, 999078, China. (6)Department
of Computer Science and Engineering, Chinese University of Hong Kong, Hong
Kong, 999077, China. (7)Innovation Institute for Artificial Intelligence in
Medicine of Zhejiang University, College of Pharmaceutical Sciences, Zhejiang
University, Hangzhou, 310058, Zhejiang, China. tingjunhou@zju.edu.cn. (8)Faculty
of Applied Sciences, Macao Polytechnic University, Macao, 999078, China.
xjyao@mpu.edu.mo. (9)Innovation Institute for Artificial Intelligence in Medicine
of Zhejiang University, College of Pharmaceutical Sciences, Zhejiang
University, Hangzhou, 310058, Zhejiang, China. kimhsieh@zju.edu.cn.
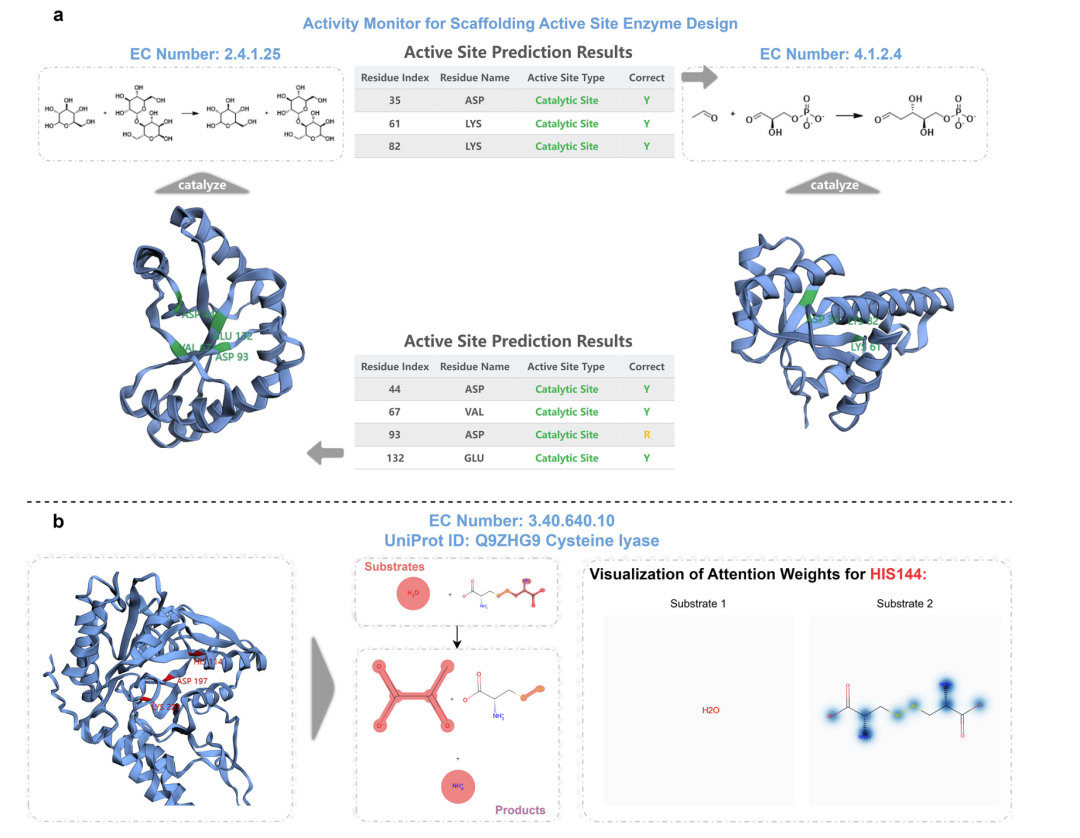
注释酶活性位点对于促进药物发现、疾病研究、酶工程和合成生物学等多个领域的发展至关重要。尽管有许多自动注释算法在发展,但速度和精度之间的巨大权衡限制了它们的大规模实际应用。EasIFA是一种酶活性位点注释算法,它融合了来自蛋白质语言模型的潜在酶表达和三维结构编码器,然后使用多模态交叉注意框架将蛋白质水平的信息与酶反应的知识进行对齐。EasIFA比BLASTp提高了10倍的速度,召回率、精确率、f1评分和MCC分别提高了7.57%、13.08%、9.68%和0.1012。它还超越了基于经验规则的算法和其他最先进的基于PSSM特征的深度学习标注方法,在提高标注质量的同时,实现了650到1400倍的速度提升。这使得EasIFA成为工业和学术环境中传统工具的合适替代品。EasIFA还可以有效地将从粗注释的酶数据库获得的知识转移到更小的高精度数据集,突出其对稀疏和高质量数据库的建模能力。此外,EasIFA显示出作为催化位点监测工具的潜力,用于设计具有超出其自然分布范围的所需功能的酶。
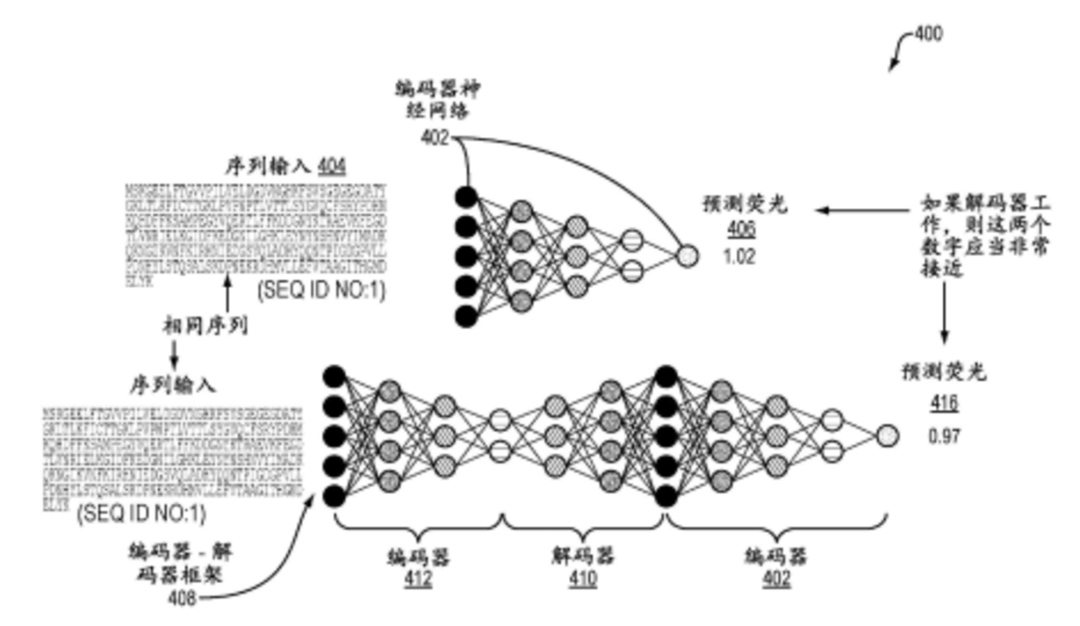
CN115136246A 机器学习引导的多肽设计
一种工程化通过功能评估的改进的生物聚合物序列的方法,该方法包括:(a)向包括预测生物聚合物序列的功能的监督模型和解码器网络的系统提供嵌入起点,该监督模型网络包括编码器网络,该编码器网络提供了将生物聚合物序列嵌入在表示该功能的功能空间中,并且该解码器网络被训练用于在将生物聚合物序列嵌入在该功能空间中的情况下提供概率性生物聚合物序列;(b)根据步长来计算该功能相对于该起点处的嵌入的变化,该计算的变化使得提供该功能空间中的第一更新点;(c)在该功能空间中的第一更新点处在特定阈值内达到该所需的功能水平时,提供该第一更新点;以及(d)从该解码器获得概率性改进的生物聚合物序列。