ChatGPT中输入提示:
你是一个Python编程专家,写一个脚本,具体任务步骤如下:
循环接受用户输入的YouTube视频地址;
获取用户输入的YouTube视频地址(用户一次可能输入一个URL,也可能一次输入多个,确保能自动识别出多个不同的http地址);
如果这是单个视频,那么用yt-dlp库下载视频中的音频流,保存到文件夹:"F:\aivideo",格式为MP3;
如果这是一个列表,那么用yt-dlp库下载列表中所有视频的音频流(格式为MP3),保存到文件夹:"F:\aivideo"的子文件夹,子文件夹名称为列表名;
注意:
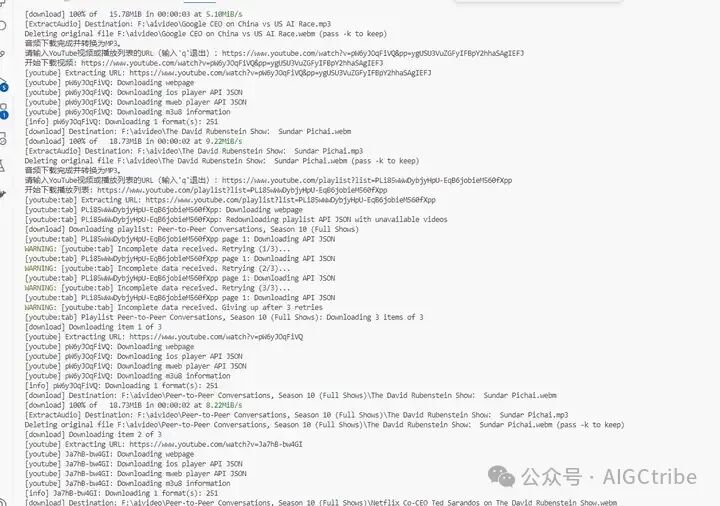
每一步都要输出信息到屏幕上;
Mp3的文件名在保存前要进行处理,去掉和Windows系统中符合命名规范的特殊字符;
ChatGPT给出的源代码:
import os
import re
import yt_dlp
# 定义保存目录
SAVE_DIR = "F:\\aivideo"
# 处理文件名中不允许的特殊字符
def sanitize_filename(filename):
return re.sub(r'[\\/*?:"<>|]', "", filename)
# 下载单个视频音频
def download_single_video(url):
try:
ydl_opts = {
'format': 'bestaudio/best',
'outtmpl': os.path.join(SAVE_DIR, '%(title)s.%(ext)s'),
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
'noplaylist': True
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info_dict = ydl.extract_info(url, download=False)
video_title = sanitize_filename(info_dict.get('title', 'unknown'))
ydl_opts['outtmpl'] = os.path.join(SAVE_DIR, f'{video_title}.mp3')
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
print(f"正在下载单个视频音频: {video_title}")
ydl.download([url])
print(f"下载完成: {video_title}.mp3")
except Exception as e:
print(f"下载失败: {str(e)}")
# 下载播放列表中的音频
def download_playlist(url):
try:
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}]
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info_dict = ydl.extract_info(url, download=False)
playlist_title = sanitize_filename(info_dict.get('title', 'unknown_playlist'))
playlist_dir = os.path.join(SAVE_DIR, playlist_title)
if not os.path.exists(playlist_dir):
os.makedirs(playlist_dir)
ydl_opts['outtmpl'] = os.path.join(playlist_dir, '%(title)s.%(ext)s')
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
print(f"正在下载播放列表: {playlist_title}")
ydl.download([url])
print(f"下载完成,音频保存在: {playlist_dir}")
except Exception as e:
print(f"下载失败: {str(e)}")
# 检测输入中的多个URL
def extract_urls(input_string):
# 正则表达式匹配URL
url_pattern = re.compile(r'https?://[^\s]+')
return url_pattern.findall(input_string)
# 循环接受用户输入
while True:
input_urls = input("请输入YouTube视频或播放列表地址(输入 'q' 退出):")
if input_urls.lower() == 'q':
break
urls = extract_urls(input_urls)
if not urls:
print("未检测到有效的URL,请重新输入。")
continue
for url in urls:
if "playlist" in url:
download_playlist(url)
else:
download_single_video(url)
代码说明:
sanitize_filename函数:通过正则表达式去除文件名中的特殊字符,确保符合Windows系统的文件命名规则。
download_single_video函数:用于下载单个YouTube视频的音频,格式为MP3,并保存在F:\aivideo目录下。
download_playlist函数:用于下载播放列表中的所有视频音频,音频以MP3格式保存在以播放列表名称命名的子文件夹中。
extract_urls函数:使用正则表达式从用户输入中提取所有的HTTP/HTTPS URL,可以一次输入多个URL,程序会自动识别并处理。
循环输入:脚本会循环接受用户输入,直到用户输入'q'退出。
如何使用:
确保已经安装yt-dlp:可以通过以下命令安装:
复制代码
pip install yt-dlp
运行脚本,用户可以一次输入一个或多个YouTube视频或播放列表地址,程序会自动识别地址并下载音频。
每一步操作都有清晰的提示信息输出,帮助用户了解下载进度。