大家好我是小墨,之前有很多粉丝朋友说ai医学入门很难,那些教程的数学完全看不懂,不知道应该怎么学。
所以我打算新开一个系列,在尽量不用数学公式的情况下给大家把医学中的机器学习和深度学习概念讲清楚(可以起到一个找到合适自己领域的技术再针对性去学习的作用)当然之后还是避免不了要学数学的。
这个系列会很长,所以我会分成很多个部分,这篇文章我们讲的
是 设计原型机器学习系统流程——皮肤癌分类原型系统。
机器学习流程
在本节中,我们将描述构建一个 原型机器学习系统 以执行常规皮肤病评估的流程:区分皮肤病变的良性与恶性。
通过这个实例,我们将介绍机器学习流程(最基本的形式)并阐述其背后的基本概念。
数据收集
由于机器学习建立在从数据中学习的原则上,因此收集数据自然构成了机器学习流程的第一步。
在我们的皮肤病评估示例中,要收集的数据是皮肤病变的图像,每张图像都由人类专家(如皮肤科医生)标记为良性或恶性。

图1:一个包含四类良性病变(上排)和四类恶性病变(下排)的小型分类数据集。图中所展示的图像均来源于国际皮肤成像协作组(ISIC)数据集。
重要的是要注意,虽然皮肤科医生经过训练可以通过视觉检测各种类型的皮肤癌(甚至在疾病的早期阶段),但癌症的最终诊断只能在实验室中对活检病变进行组织病理学检查后得出。
在机器学习的术语中,病理学家为每个样本提供真实情况,而我们教计算机区分两种类型或类别数据(此处为良性病变和恶性病变)的任务被称为分类。
在上图中,我们展示了当前任务的一个小数据集,其中包含八个样本或数据点。
通常,我们希望训练数据集尽可能大和多样化,因为更多的示例能为机器学习系统提供更多的经验,在实践中,机器学习数据集可能包含数百万个数据点。
特征设计
为了区分良性和恶性病变,皮肤科医生会考虑病变的不同属性组合,包括其形态、颜色和大小,这些属性在机器学习的语言中被称为特征。
众所周知,与良性痣相比,恶性病变通常具有更不对称的形状和更不规则的边界,如图1所示的小数据集所反映的那样,虽然量化这些定性特征并非易事,但为了简化起见,我们假设可以轻易地从数据集中的每张图像中提取以下两个特征:首先是对称性,范围从完全对称到高度不对称;
其次是边界形状,范围从完全规则到高度不规则。
通过选择这些特征,每张图像都可以用两个数字在二维特征空间中表示:一个数字测量病变的对称性,确定图像在特征空间中的水平位置。
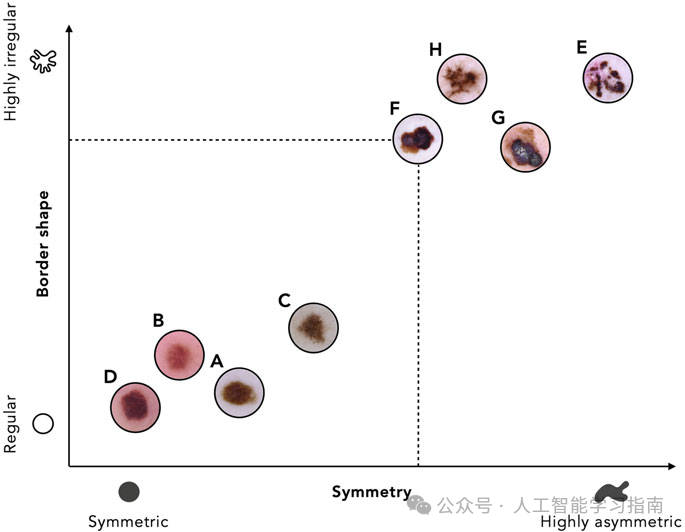
图2中先前所示数据集的特征空间表示。在此图中,横轴和纵轴分别代表对称性和边界形状特征。良性和恶性病变在特征空间中分布于不同区域,这表明所选特征十分恰当。
另一个数字捕捉病变的边界形状,确定其在特征空间中的垂直位置,如图2所示。
设计适当的特征对于分类系统的整体成功至关重要,优质特征能够使两类数据在特征空间中很好地分离,就像我们在图2中选择特征时的情况一样。
模型训练
在精心设计的特征空间中表示数据后,区分良性和恶性病变的问题就简化为用一条线将每个类别的数据点分开。
在机器学习的术语中,这条线被称为分类模型(或简称分类器),而寻找最佳分类模型的过程被称为模型训练。
一旦训练好分类器,特征空间将被分为两个子空间,分别位于分类器的两侧。
图3显示了一个训练好的线性分类器,它将特征空间分为良性和恶性子空间。
请注意,这个分类器为区分良性和恶性病变提供了一个简单的规则:当病变的特征表示位于线下方(蓝色区域)时,它将被分类为良性;同样,任何位于线上方(黄色区域)的特征表示都将被分类为恶性。
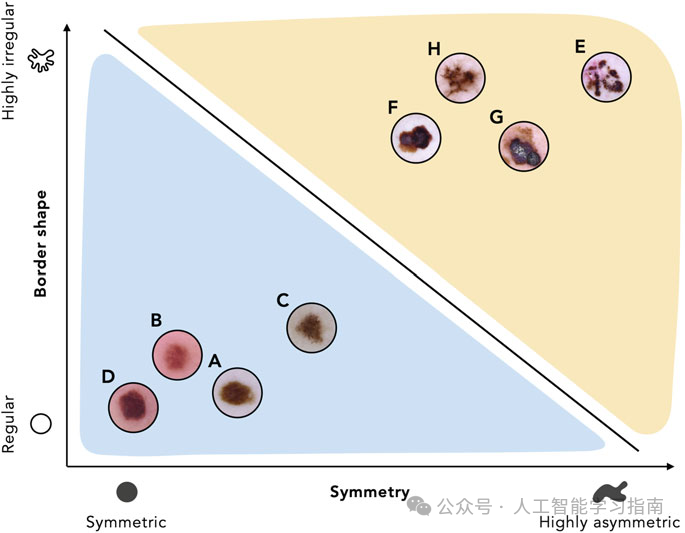
图3模型训练的目标是找到一条合适的直线,用以在特征空间中区分两类数据。图中所示黑色直线代表的线性分类器提供了一条计算规则,用于区分良性和恶性病变。若某病变的特征表示位于直线以下(蓝色区域),则判定为良性;若位于直线以上(黄色区域),则判定为恶性。
模型测试
图3所示的分类模型在分离良性和恶性病变的特征表示方面做得非常出色,没有数据点被错误分类。
然而,这并不意味着我们可以对分类器的有效性过于自信。
分类器的真正考验在于它能否将其所学内容推广到新的或以前未见过的数据实例。
这一评估通过模型测试过程完成,为了测试分类模型,我们必须收集一批新的数据,称为测试数据,如图4所示。
显然,测试数据集与先前在训练期间使用的数据集之间不应有重叠,我们从此将其称为训练数据集。
 图4一组用于测试的良性(上排)和恶性(下排)皮肤病变数据集。
图4一组用于测试的良性(上排)和恶性(下排)皮肤病变数据集。
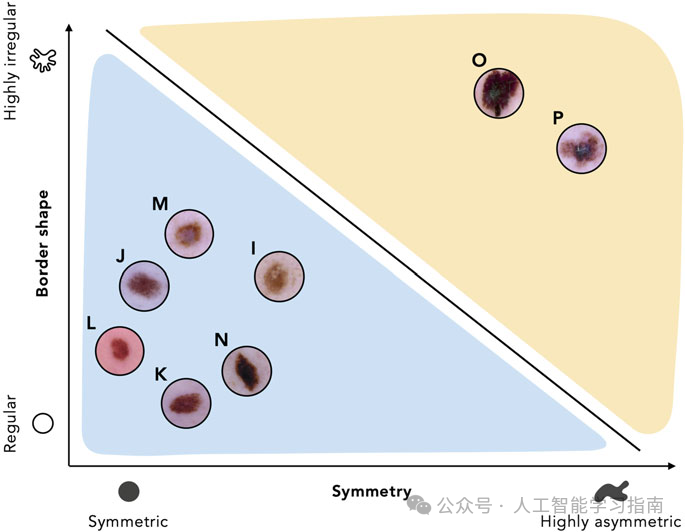
模型测试过程始于使用先前设计的特征集(即对称性和边界形状)获得测试数据集中每张图像的特征表示。
在提取了两个特征后,我们找到每个测试图像在特征空间中相对于训练好的线性分类器的位置。
如图5所示,所有四个良性病变都位于蓝色区域的线下方,因此被分类器正确分类为良性。
同样,四个恶性病变中有两个位于黄色区域的线上方,因此被正确分类为恶性。
然而,有两个恶性病变(即数据点M和N)最终位于蓝色区域的错误一侧,因此被分类器错误分类为良性。