《深度学习图像分割》这本书写写停停,历经三年多,目前在二稿修订中。正式出版之前,计划先在GitHub做逐步的内容和代码开源。
以下为本书第3章节选内容:
近年来,基于深度学习的图像分割技术发展迅猛,涌现出大量创新的模型和算法。然而,构成这些方法的核心技术组件并未发生根本性变化。为了能够系统性的理解深度学习图像分割模型的设计,本章将首先回顾图像分割中的关键技术组件,为后续章节中深度学习分割网络的具体介绍奠定基础。本章将从图像分类网络与编码器、上采样方法与解码器、跳跃连接、空洞卷积、图模型与图像分割后处理方法、深度监督方法、分割模型损失函数与性能评价方法等多个方面来阐述深度学习图像分割的关键技术组件。
3.1 图像分类网络与编码器
在本书第1章中,我们了解到基于深度学习的图像分类、目标检测和图像分割的三大视觉任务本质上是一种任务粒度不断细分的过程。因而,图像分割网络模型的设计非常依赖于图像分类网络。实际上,图像分类网络在图像分割网络模型结构设计中充当了编码器(encoder)的作用,主要用于提取图像各种层次的特征和浓缩图像语义信息,为后续的解码过程提供高质量的特征表达。
随着CNN在图像领域的应用逐步深入,相关深度学习网络结构设计层出不穷。自2012年起,伴随着ImageNet大规模视觉挑战赛(ILSVRC)的举办,每年都有性能卓越的新网络结构问世,为计算机视觉领域注入了深度学习的活力。2012年,Alex Krizhevsky在ILSVRC上提出的AlexNet首次展示了深度卷积神经网络在图像识别中的潜力。AlexNet凭借显著的优势获得了冠军,将ImageNet数据集的Top-5错误率从往年的26%降至16.4%,相比于第二名的传统机器学习模型有了大幅度的提升。这一突破性成果迅速引起了学界和业界的广泛关注,并标志着计算机视觉逐渐进入深度学习主导的时代。AlexNet包含约6亿3千万条连接,6千万个参数和65万个神经元,其设计大大拓展了网络的深度与复杂度。这一网络结构由5层卷积层和3层全连接层组成,前几层卷积后接最大池化层以实现下采样。具体来说,第一、第二和第五层卷积后分别连接了最大池化层,以降低计算复杂度并引入平移不变性;而最后的3个全连接层则用于整合高层特征,实现最终的分类任务。AlexNet的成功不仅在于其显著的性能提升,还在于它证明了深度卷积网络在大规模数据集上的可行性与有效性。
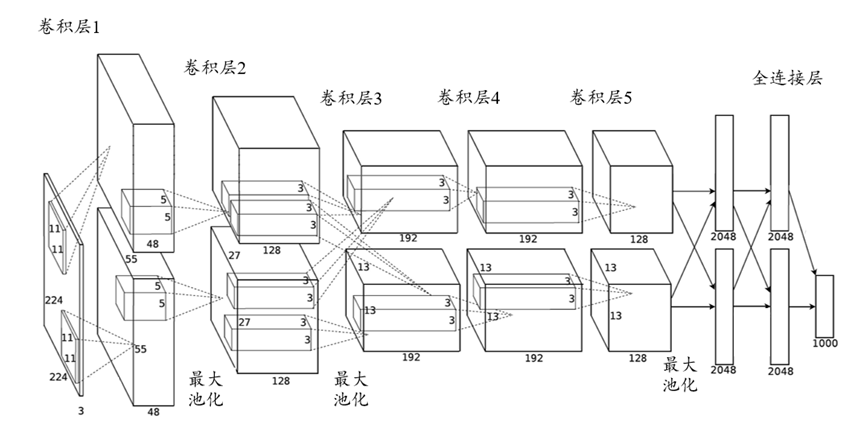
图3-3 AlexNet网络结构
在AlexNet取得突破性成果之后的几年里,越来越多具有里程碑意义的卷积神经网络结构被提出,包括2013年的ZFNet,2014年的GoogLeNet和VGG,2015年的ResNet,2016年的ResNext以及2017年的SENet,都提出了各具特色和在深度学习发展历史上具有里程碑意义的卷积网络结构。比如VGG的平铺模式的卷积块结构、GoogLeNet的1×1卷积、ResNet的残差连接块、SENet的squeeze-excitation结构等。图3-4是一个Inception模块结构,在网络中并行使用不同尺寸的卷积核(如1×1、3×3、5×5)以捕捉不同尺度的特征。这种组合结构有效地提升了网络的特征表达能力,同时降低了计算复杂度。尤其是1×1卷积的引入,能够显著减少参数量并增强模型的计算效率。
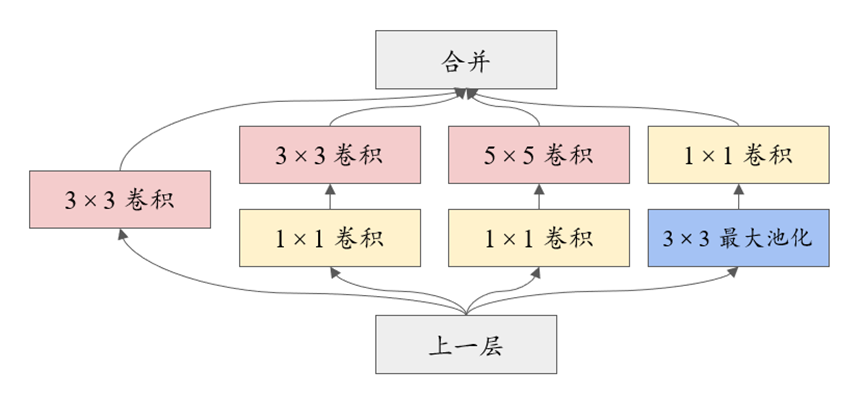
图3-4 Inception模块
后ImageNet时代,深度学习研究持续推动图像分类网络的演进,涌现出DenseNet、EfficientNet、NasNet等新的SOTA(State-of-the-Art)网络结构,这些网络在提高性能的同时也注重参数效率与计算效率。此外,轻量化网络如SqueezeNet、MobileNet、ShuffleNet和Xception逐步走向工业应用,满足了移动设备和实时计算的需求。这些网络无论在设计上多么复杂或精巧,实质上仍然遵循了图像分类的基本任务——对图像进行特征提取和语义压缩,以最终完成分类预测。这一过程的核心结构通常被称为编码器。
编码器的作用在于通过卷积层和池化层的组合对图像进行逐层下采样。每一次卷积和池化操作,都会提取图像的特征并逐步缩小特征图的空间尺寸,但同时增强了其语义分辨能力。在这一过程中,低层次特征(如边缘和纹理)逐渐被压缩,模型则更关注全局语义信息的表达。这样的设计模式在早期的ImageNet网络中已见端倪,并逐渐成为大多数分类网络的通用结构,即通过不断卷积和池化将特征图逐步浓缩,最后通过全连接层输出类别概率。图3-5展示了图像分类任务中的编码器过程。从输入图像到语义标签的分类输出,特征图在逐层卷积池化中不断缩小并浓缩出全局语义信息,这种下采样的过程是图像分类网络结构的核心。
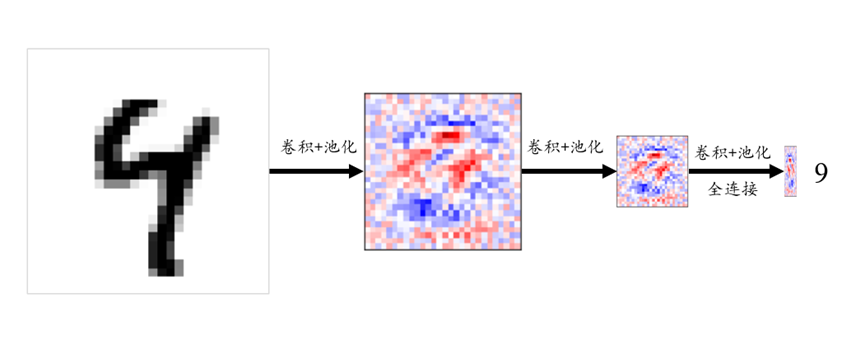
图3-5 编码器过程
3.2 上采样方法与解码器
3.3 跳跃连接
3.4 空洞卷积
3.5 图像分割后处理方法
3.6 深度监督方法
3.7 损失函数与评价指标
《深度学习图像分割》项目配套GitHub地址:
https://github.com/luwill/Deep-Learning-Image-Segmentation
欢迎各位读者阅读以及对本书提出意见与建议!











