加利福尼亚大学欧文分校UCI医疗中心放射科、北加利福尼亚凯撒医疗集团等单位2024年在Radiology (JCR Q1, IF: 12.1) 杂志上发表了测试ChatGPT从转录的放射学发现中生成差分诊断的能力与局限性。测试ChatGPT从转录的放射学发现中生成差分诊断的能力与局限性
摘要
背景:在医学领域,ChatGPT作为一种潜在有用工具的兴趣日益增长,这突显了对其能力和局限性进行系统评估的必要性。
目的:评估ChatGPT从转录的放射学发现中产生的差分诊断的准确性、可靠性和重复性。
材料和方法:从涵盖多种成像方式、亚专科和解剖病理学的放射学教科书系列中选取的病例被转换成标准化的提示,输入到ChatGPT(GPT-3.5和GPT-4算法;2023年4月3日至6月1日)。通过与教科书中提供的最终诊断和前3个差分诊断进行比较(作为真实情况),分析响应的准确性。可靠性,基于算法幻觉的频率定义,通过识别事实上不正确的陈述和编造的引用来评估。使用McNemar测试和广义估计方程模型框架对算法进行比较。通过为每个亚专科的10个病例从两种算法中获得10个独立响应,并计算平均配对百分比一致性和Krippendorff α值,来测量测试-重测的重复性。
结果:
在多个放射学亚专科中共收集了339个病例。GPT-3.5和GPT-4对于最终诊断的总体准确性分别为53.7%(182/339)和66.1%(224/339;P < .001)。GPT-3.5和GPT-4的平均差分得分(即,与原始文献差分诊断相匹配的前3个诊断的比例)分别为0.50和0.54(P = .06)。在GPT-3.5和GPT-4响应中提供的引用中,分别有39.9%(401/1006)和14.3%(161/1124;P < .001)是编造的。GPT-3.5和GPT-4分别在16.2%(55/339)和4.7%(16/339;P < .001)的病例中生成了错误陈述。最终诊断和前3个差分诊断在亚专科之间的平均配对百分比一致性范围分别为59%–98%和23%–49%。
结论:当使用最新的模型(GPT-4)并且提示为单一诊断时,ChatGPT取得了最佳结果。与GPT-3.5相比,GPT-4的幻觉频率较低,但两种模型的重复性都是一个问题。

图1 | 研究流程图。包括病例的选择、算法的应用、响应的生成和分析,以及统计分析的过程。
ChatGPT,作为大型语言模型(LLMs)GPT-3.5和GPT-4(OpenAI)的界面,是人工智能领域的一项里程碑式的进步。尽管ChatGPT最初是作为文本预测和对话模型设计的,但初步测试显示,它在各种任务中生成和表达微妙且恰当的上下文响应的能力令人瞩目。这种能力与以往的人工智能工具形成鲜明对比,后者通常只针对相对特定的任务。OpenAI的最新LLM,GPT-4,在各种任务上相较于其前身GPT-3.5表现出了进一步的改进,包括在医学执照考试中。
鉴于ChatGPT的广泛能力,人们提出了这样一个问题:这类模型在需要诊断推理的医学挑战中将如何表现。支持医学诊断的算法已经开发了几十年,目前最常见于两种形式:面向患者的“症状检查器”和面向医生的决策支持系统。将ChatGPT作为差分诊断生成器首次应用于医学中,针对常见主要症状的临床小故事,其诊断准确率达到了53.3%。另一项在更复杂的诊断案例中的研究表明,GPT-4生成的顶级诊断准确率为39%,而在模型的差分诊断中包含真实诊断的准确率为64%。在放射学中的应用表明,GPT-4与专家的差分一致性达到了68.8%,在放射学中的诊断准确性为54%,差分准确性为61%。
尽管这些结果令人印象深刻,但必须承认ChatGPT的局限性。GPT-4的训练数据包括了截至2021年9月的材料,限制了算法处理最新发展或知识的能力。此外,存在一个与LLMs相关的“幻觉”效应,即可能不准确的自信回应。此外,用户对ChatGPT答案的一致性提出了质疑,并经常发现矛盾。这些担忧促使在医学和科学领域应用ChatGPT和LLMs时需要谨慎。
患者病例
研究使用的是《放射学中的Top 3差分诊断》系列,该系列提供了独立创建的、去标识化的回顾性患者病例,以及专家审查的诊断和差分诊断。
由于病例是公开可用且去标识化的,因此不需要知情同意和机构审查委员会的批准。研究包括以下放射学亚专科:胸部和心脏、胃肠和泌尿生殖系统、肌肉骨骼、神经、乳腺、核医学以及血管和介入放射学。从主要教科书的每个部分开始收集病例,目标是每个部分至少包括50个病例,或者如果病例数量少于50个,则包括所有可用的病例。某些病例被排除在分析之外:(a) 最终诊断未包含在前3个差分诊断中的病例,(b) 未提供前3个差分诊断的病例,以及 (c) 前3个差分诊断包括非医疗诊断的病例,包括但不限于成像伪影或技术错误。从该系列的专科教科书中额外随机选择病例以增加病例量。
五名研究生三年级的放射学住院医师(S.H.S., K.H., G.C., R. Hill, 和 J.T.),在平均有14年经验的三名主治放射科医师(R. Houshyar, V.Y., 和 M.T.)的监督下,根据每个病例的图像和标题转录放射学发现,进行轻微编辑以保留纯粹的描述性语言。标题中的所有语言,如果陈述了诊断或对发现的解释,都被转换为仅描述放射学发现的特征。附录S1中提供了一个示例。
响应生成
GPT-3.5和GPT-4算法通过ChatGPT接入,被要求为每个病例生成一个前3名的差分诊断、一个最可能的诊断,以及支持其答案的引用。为了创建一个共同的提示格式并塑造算法响应的正确组成,每个患者病例后面都添加了一个标准查询:“这个场景的前3个差分诊断是什么?请解释原因,并提供你的引用,使用标准的AMA格式。这个场景的最可能诊断是什么?请解释原因,并提供你的引用,使用标准的AMA格式。”查询和提示被创建为直接和简洁的目的。提示分别呈现给GPT-3.5和GPT-4算法(在2023年4月3日至6月1日之间),以生成响应。为了最大化独立性,每个单独的病例都使用算法的新实例。
如果算法提供了不完整的响应(即,如果缺少完整答案的任何部分),则重新生成响应,直到提供缺失的组件;接受第一个完整的答案。
响应分析
算法响应通常包含以下三个类别的信息:诊断答案、支持答案的陈述和作为答案证据提供的引用。算法提供的诊断答案包括前3个差分诊断和“最可能”诊断,这些与原始病例文献中提供的相应差分和最终诊断进行比较以确定准确性。顶级1准确性和顶级3准确性定义为生成的响应与原始文献中提供的最终诊断和完整差分诊断相匹配的百分比。另外,定义了差分得分,作为前3个诊断与原始文献差分诊断相匹配的比例,以给予那些没有完全匹配教科书差分诊断的响应部分学分;例如,如果模型产生的前3个诊断只有一个与教科书差分诊断相匹配,则给出0.33(1 of 3)的得分。在准确性分析中不考虑前3个诊断的排序。
支持陈述和引用被分析是否存在幻觉,定义为事实上不正确的信息或编造的引用。关于标准和识别事实上不正确的信息和编造的引用的额外信息,请参见附录S1。
重复性分析
为了重复性分析,从每个亚专科中选择了10个病例,并使用GPT-3.5和GPT-4为每个病例生成了10个独立响应。记录了每个响应的最可能诊断、前3个差分诊断和差分得分。在最终诊断类别中,每个独特的响应以及差分诊断类别中每个独特的响应组合都被赋予了唯一的连续整数,然后进行统计分析。
统计分析
使用配对McNemar测试和Edward连续性校正比较两个模型之间的顶级1和顶级3准确性。使用泊松分布的广义估计方程模型框架比较模型之间的平均差分得分。同样使用泊松分布的广义估计方程模型框架比较模型之间的错误陈述和编造引用的频率。平均配对百分比一致性和Krippendorff α用于估计测试-重测重复性。平均配对百分比一致性描述了随机配对的重复测试一致的频率,百分比越高表示更频繁的一致性。Krippendorff α通常用作测试-重测可靠性的指标,对于编码名义数据,1.0表示完美的可靠性,而0.0表示没有可靠性。P < .05被认为表示统计学上的显著差异。所有统计分析都在R(版本4.2.2;R项目统计计算)中由两位作者(S.H.S.和A.L.N.)执行。
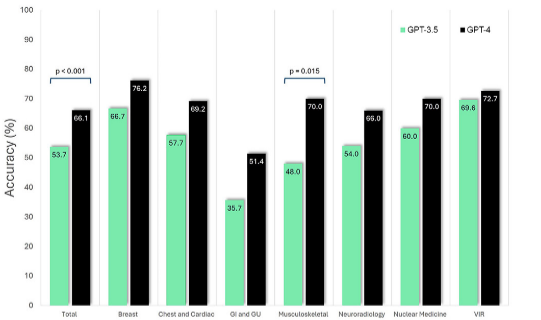
GPT-3.5与GPT-4在总样本和不同测试亚专科中的top1诊断准确性。显示了GPT-3.5和GPT-4在top1诊断准确性方面的表现,并在不同的放射学亚专科中进行了比较。使用McNemar测试评估统计学意义,并标注了P < .05的比较结果。这个图表有助于直观地比较两个模型在总体和各个亚专科中的性能。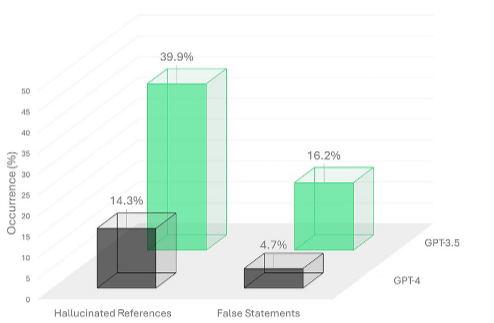
GPT-3.5与GPT-4生成的幻觉引用和错误陈述。展示了GPT-3.5和GPT-4在生成幻觉引用和错误陈述方面的比较。幻觉引用是指那些在现实世界中没有对应物的引用,而错误陈述则是指包含不正确推理或信息的陈述。显示了新一代模型(GPT-4)在减少这两种问题方面的改进。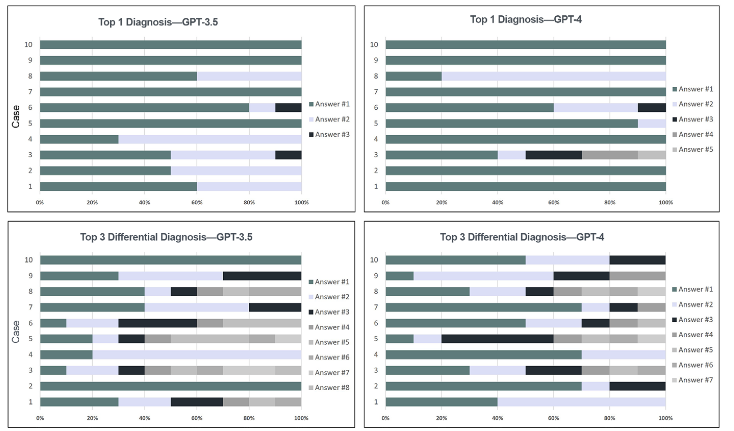
胃肠和泌尿生殖亚专科中ChatGPT生成响应的频率和多样性。
展示了在胃肠和泌尿生殖亚专科中,ChatGPT对于top1诊断和前3个差分诊断的响应频率和多样性。它通过不同的颜色条来表示每个病例生成的10个独立响应中的独特答案或答案组合。这个图表有助于理解算法在特定亚专科中的一致性和变化性。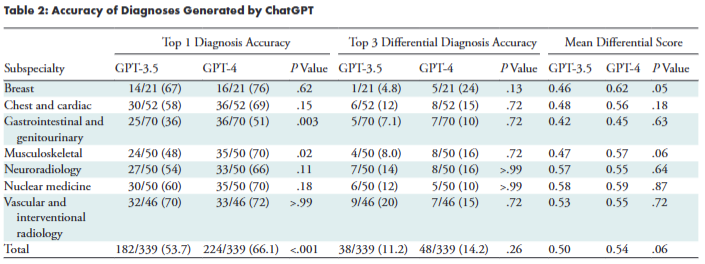
Radiology, vol. 313, no. 1, Oct. 2024, p. e232346, https://doi.org/10.1148/radiol.232346.











