在深度学习中,自注意力机制允许模型在处理序列数据时,通过计算序列中不同位置元素之间的相关性得分,
动态地调整对每个元素的关注程度,从而捕捉序列内部的复杂依赖关系。
自注意力机制与注意力机制在处理对象和应用场景上存在差异,自注意力机制更侧重于处理序列内部元素之间的相互作用。
自注意力机制(Self- Attention)是什么?自注意力机制能够动态地捕捉序列中不同位置元素之间的依赖关系,并根据这些依赖关系生成新的序列表示。
它之所以被称为“自注意力”,是因为它在
单一序列中通过计算序列元素之间的相互依赖关系来生成新的特征表示。这与传统的注意力机制有所不同,后者通常涉及两个序列之间的交互。
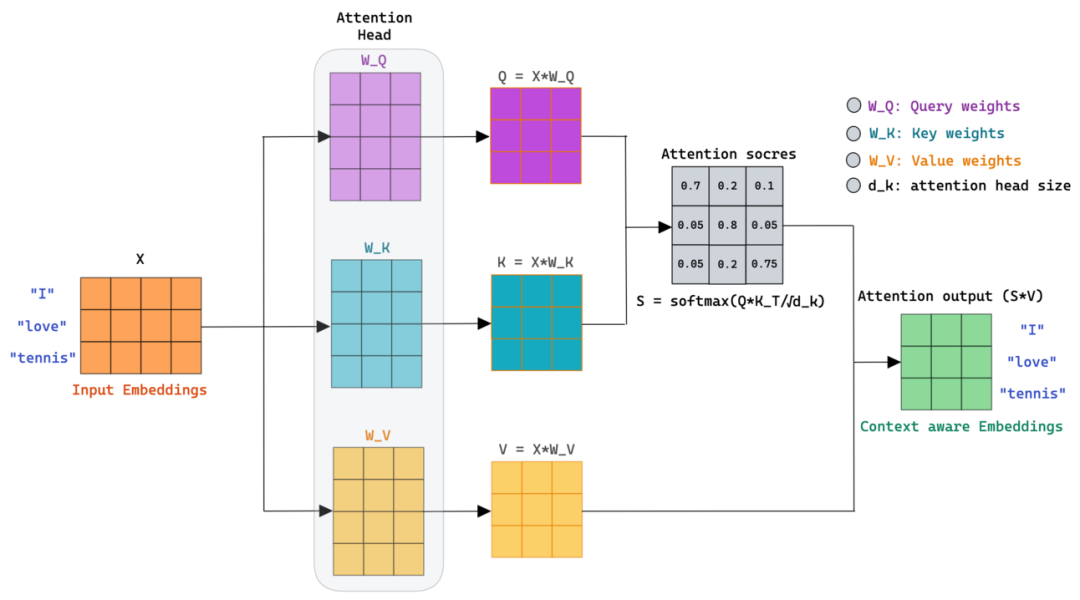
自注意力机制和传统注意力机制区别是什么?传统注意力机制通常涉及目标元素(输出)与源元素(输入)之间的交互,而自注意力机制则专注于输入序列或输出序列内部元素之间的相互作用,其查询和键均来自同一组元素。
如何实现注意力机制?在自注意力机制中,
通过缩放点积计算注意力得分,并利用这些得分对值向量进行加权求和,从而实现了自注意力机制,它能够捕捉序列内部元素之间的依赖关系。
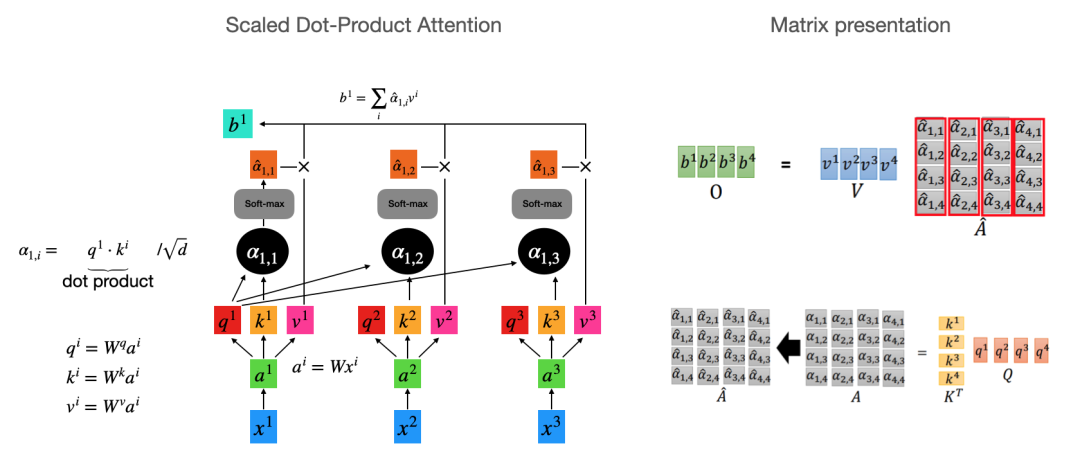
注意力分数是什么?注意力分数用来量化注意力机制中某一部分信息被关注的程度,反映了信息在注意力机制中的重要性。在注意力机制中,模型会根据注意力分数来决定对不同输入信息的关注程度。
Q(Query)、K(Key)、V(Value)通过映射矩阵得到相应的向量,通过计算Q与K的点积相似度并经过softmax归一化得到权重,最后使用这些权重对V进行加权求和
得到输出。
Q、K、V计算过程是什么?对于输入序列的每个单词,通过计算其Query与所有单词Key的点积得到注意力分数,经Softmax归一化后得到注意力权重,再用这些权重对Value向量进行加权求和,以得到包含丰富上下文信息的新单词表示。
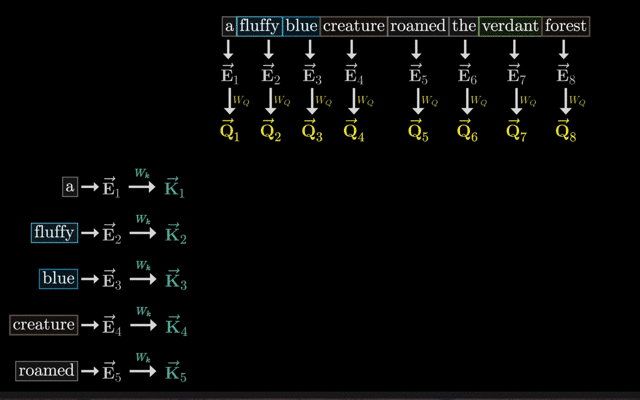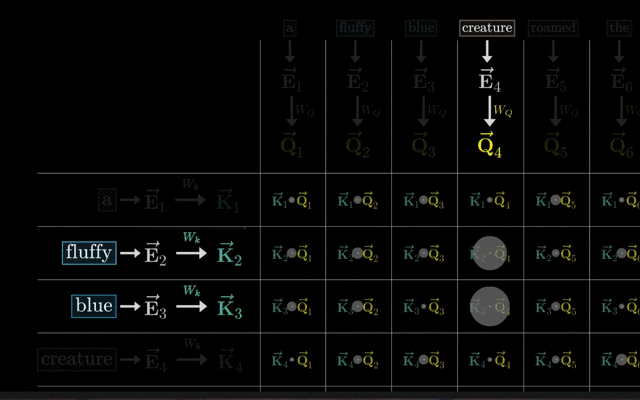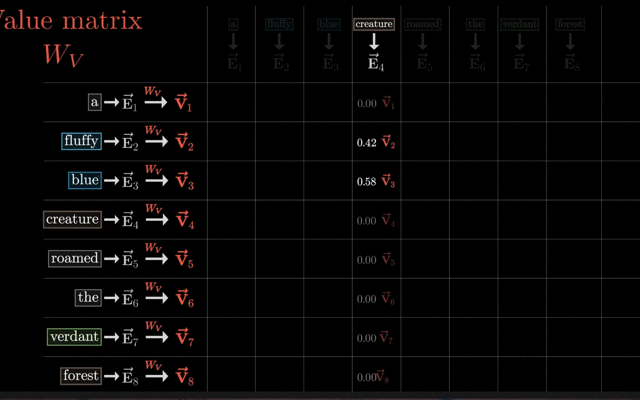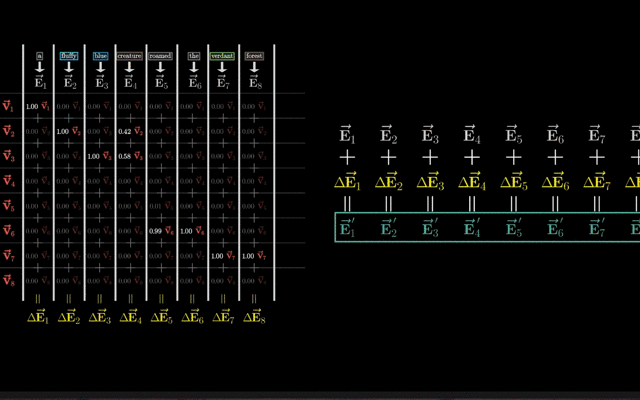
生成Q、K、V向量:对于输入序列中的每个单词,都会生成对应的Query(查询)、Key(键)和Value(值)向量。这些向量通常是通过将单词的嵌入向量(Embedding Vector)输入到一个线性变换层得到的。
计算Q、K的点积(注意力分数):计算Query向量与序列中所有单词的Key向量之间的点积,得到一个分数。这个分数反映了Query向量与每个Key向量之间的相似度,即每个单词与当前位置单词的关联程度。
Softmax函数归一化(注意力权重):这些分数会经过一个Softmax函数进行归一化,得到每个单词的注意力权重。这些权重表示了在理解当前单词时,应该给予序列中其他单词多大的关注。
注意力权重加权求和
(加权和向量):这些注意力权重与对应的Value向量进行加权求和,得到一个加权和向量。这个加权和向量会被用作当前单词的新表示,包含了更丰富的上下文信息。
为了帮助更多人(AI初学者、IT从业者)从零构建AI底层架构,培养Meta Learning能力;提升AI认知,拥抱智能时代。从而建立了“架构师带你玩转AI”知识星球。
【架构师带你玩转AI】:公众号@架构师带你玩转AI 作者,资深架构师。2022年底,ChatGPT横空出世,人工智能时代来临。身为公司技术总监、研发团队Leader,深感未来20年属于智能时代。










