在数据科学里有一个热门术语——机器学习生命周期。
听起来很奇怪,但实质上就是:
机器学习是一个积极且动态的过程,没有严格的起点或终点。
一旦模型训练并部署后,随着时间的推移,很可能需要重新训练,从而重启整个周期。
然而,周期内的步骤需要按照一定的顺序仔细执行。
当你在网上搜索机器学习生命周期时,每个来源给出的步骤数量和名称可能略有不同。
但大部分生命周期都包含以下环节:问题定义、数据收集和预处理、特征工程、模型选择和训练、模型评估、部署和监控。
今天就让我们来仔细分析这些步骤,解释什么是机器学习的生命周期。
这篇文章中的代码、数据集和一份为大家查漏补缺的人工智能学习路线图一起打包好了,大家可以添加小助手获取!

你想要解决什么问题或回答什么疑问?你是否需要机器学习,还是可以使用更简单的方法(如统计学)?
问题:客户希望预测一天内的小时级消耗量,以便识别消耗趋势,即一天中的哪些小时和一周中的哪些天消耗似乎最高。
他们将利用这些信息来寻找减少全天及高负荷时段消耗的方法。
目标:预测未来24小时的电能消耗
所需方法:为了提高准确性,需要采用机器学习。
简单的模型(如移动平均模型)不会考虑诸如一天中的小时和一周中的天数等重要特征,也无法展示这些特征与目标变量之间的关系。
所需数据:带有适当时间戳的小时级消耗数据
所需数据量:至少1年的历史数据(我们将分析的数据集包含10年的历史数据)
可解释性:我们需要一个至少能够解释哪些特征对预测贡献最大的模型
指标:我们希望在测试集上实现的平均绝对百分比误差(MAPE)为10%或更低。
同时,我们还想查看均方根误差(RMSE)等指标,并用于模型优化和调整。
我们将使用的数据集来自Kaggle(CC0公共领域许可证)。
它是一个小时级能源消耗数据集,包含电力数据,数据集包含日期/时间戳以及以兆瓦(MW)为单位的电力消耗。
在Python中,首先需要将数据加载到DataFrame中。
从Kaggle下载了CSV格式的数据集,并将其加载到Python笔记本脚本中:
import pandas as pd
df = pd.read_csv("AEP_hourly.csv")
调用df.head()将显示DataFrame的前5行。最好调用它来检查数据的整体结构并查看你拥有的列。
下一步是进行探索性数据分析(EDA)。
EDA包括:
通过描述性统计和值计数从数值上探索数据
通过图形和图表从视觉上探索数据
根据探索结果做出一般性的初步推断
以下是一些可以用来启动EDA过程的简单单行代码:
这是该数据集的输出结果:
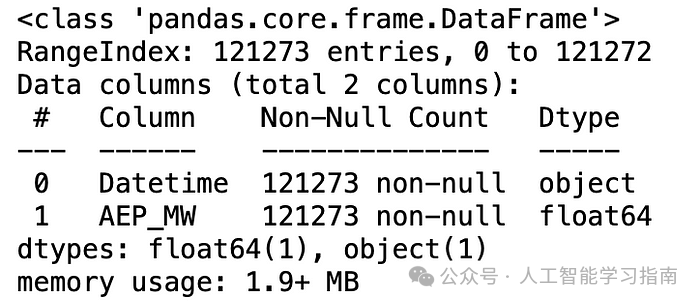
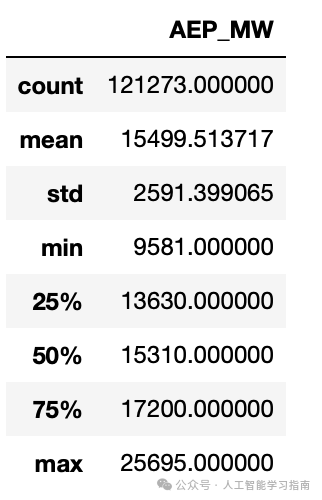
另一个有用的方法是df.value_counts()。它会计算你列中的唯一值的数量,并告诉你每个值在DataFrame(每列)中存在多少个。
由于我们处理的不是分类数据,因此这对于本数据集来说并不那么重要。
视觉EDA通常涉及以各种方式直观地检查数据。
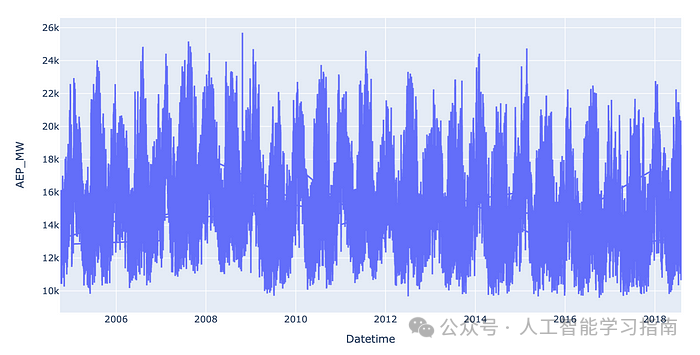
对于此类时间序列数据集,最简单的一个起点是简单地将数据绘制为散点图或折线图。
import plotly.express as px
px.line(df, x="Datetime", y="AEP_MW")
这将产生以下输出:
你还可以创建以下常见可视化内容,用于EDA目的:
特征与目标之间的相关性图
特征与其他特征之间的相关性图
带有回归线和R^2的线性回归散点图
时间序列数据的趋势和季节性
时间序列数据的自相关图
你生成哪种EDA图表取决于你处理的数据类型,因此差异很大。
通常,你需要查找数据中可能影响你稍后将在模型中包含的特征的趋势。
大家可以看到生成的折线图上有随机线条横跨屏幕,这意味着一些时间戳是无序的。
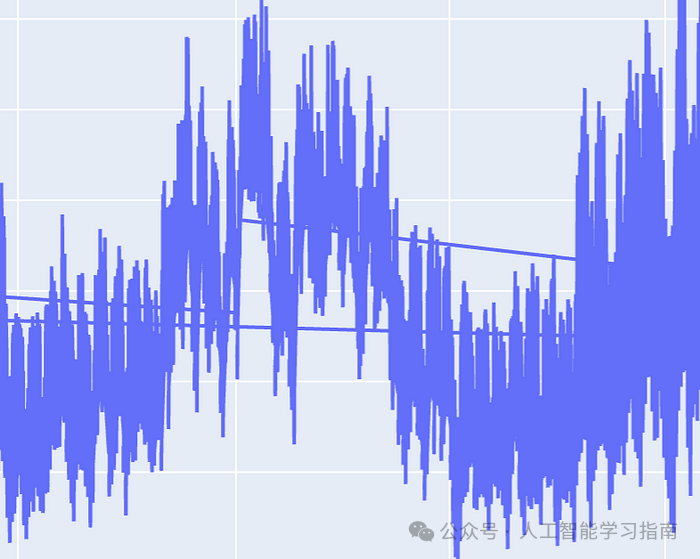
为了解决这个问题,我们将日期时间列转换为pd.datetime对象,以便对其调用pandas特定函数,然后对该列进行排序。
代码
现在图表看起来好多了:
另一个需要检查的重要事项是缺失值或空值,在时间序列数据的情况下,你还应该检查0值,并调查它们是否是有效条目或表示缺失数据。
然后,你可以决定是否需要使用数据集的中位数或平均值来删除或替换缺失值。
接下来是处理异常值,必须先检测异常值,然后像处理缺失/空值一样,将其删除或替换。
一种非常简单的识别异常值的方法是z分数,它会告诉你每个数据点与平均值的距离有多远。
如果数据点的z分数>3或
但你可以根据自己的判断和对数据的分析来收紧或放宽此阈值。
from scipy import statsdf["z_score"]=stats.zscore(df["AEP_MW"])
df = df[(df["z_score"]>3) | (df["z_score"]<-3)]]
df.drop("z_score",axis=1,inplace=True)
下一步是选择你的特征,对其进行准备和优化,以便模型使用,将它们拆分为训练/测试拆分框架,并根据需要进行缩放。
特征工程本质上是选择和操作特征的过程,希望从中提取尽可能多的相关信息,以输入到模型中。
特征选择可以手动进行,也可以通过算法进行。为了解决这个问题,由于原始DataFrame仅包含1个特征列(时间戳列),因此我们可以从该时间戳中创建的特征数量有限。
我们无法将时间戳输入到机器学习模型中,因为它不知道如何读取/处理该信息。
因此,我们需要提取时间序列特征(如小时、天、周)并将其编码为数字,以便模型能够理解它们。
给定一个按小时记录的时间戳列,我们可以提取以下特征:
一天中的小时
一周中的小时
一年中的小时
一周中的第几天
一月中的第几天
一年中的第几天
一月中的第几周
一年中的第几周
一年中的第几月
年份
当然,这些特征中有些会相互重叠,我们不需要同时保留“一周中的小时”、“一天中的小时”和“一周中的第几天”,保留“一天中的小时”和“一周中的第几天”或仅保留“一周中的小时”可能就足够了,你可以尝试这两种组合,看看哪种组合的性能最佳。
我们可以将这些特征提取为布尔值(使用如独热编码等方法),也可以使用正弦和余弦函数将它们编码为循环时间序列特征:
当处理如“一周中的第几天”这样的时间序列特征时,将日期时间列转换为数值(如1、2、3……7)对于时间序列机器学习模型来说效果并不好,因为从技术上讲,这些是分类特征而非数值特征,即使我们选择用数字来表示它们。
因此,我们需要使用一种称为独热编码的方法,该方法本质上使用多个列作为指示器,将分类值转换为布尔值。
为了让本文更简洁,这里会直接将时间戳列转换为独热编码的时间序列特征:
df['Hour']=df['Datetime'].dt.hourdf['Month']=df['Datetime'].dt.monthdf['Dayofweek']=df['Datetime'].dt.dayofweek
columns_to_encode = ['Hour', 'Month', 'Dayofweek']df = pd.get_dummies(df, columns=columns_to_encode,dtype=int)

一些模型要求你缩放任何数值特征,这些模型包括线性回归、逻辑回归和神经网络等。
由于在我们的模型中仅使用分类特征,因此无需缩放或标准化特征。
如果我们有额外的数值特征,如温度,则根据所选模型类型,可能需要缩放该列。
在缩放特征之前,重要的是首先要将数据拆分为相应的训练集和测试集。
为此,你可以使用scikit-learn的train_test_split方法,该方法默认将数据拆分为75%的训练集和25%的测试集,或者你也可以手动拆分数据。
需要注意的一点是,scikit-learn的train_test_split会随机拆分数据集,导致行不再按顺序排列。
对于时间序列来说,这不是一个好做法,所以我们可以使用索引自行拆分数据集:
train_size = int(df.shape[0] * 0.75)
features = df.drop(["AEP_MW","Datetime"],axis=1).columns
df_train = df.iloc[0:train_size]df_test = df.iloc[train_size:]
X_train = df_train[features]y_train = df_train["AEP_MW"]X_test = df_test[features]y_test = df_test["AEP_MW"]
在训练最终更复杂的模型之前,先训练一个基线模型总是一个好习惯。
基线模型通常是目标模型的简化版本(例如,如果你的目标是训练一个随机森林模型,那么基线模型可以是决策树)。
基线模型有助于建立基线指标,如基本平均绝对百分比误差(MAPE)、均方根误差(RMSE)、均方误差(MSE)等。
届时,你可以将这些指标与更先进的模型进行比较,这有助于识别数据、特征或超参数方面的问题。
现在,你需要为你的问题选择最佳的最终模型。
这将在很大程度上取决于领域、数据集、计算资源和目标。
在本例中,我将选择随机森林模型,因为它是较为知名的集成模型之一,并且通常对时间序列数据表现良好。
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor() rf.fit(X_train,y_train)
训练完模型后,你需要评估其性能,评估模型主要有两种方法:交叉验证和测试集。
测试集已从训练数据中分离出来,因此我们将使用训练好的模型对测试集进行预测。
但是,测试集仅包含数据的最后25%。我们还想了解模型在不同周、月、小时甚至年份的数据范围内的表现。
这就是交叉验证发挥作用的地方。
交叉验证使用整个训练集,并在数据集的小部分上拟合多个模型,每轮都有较小的“测试”集。
这些测试集在技术上被称为评估集。
交叉验证通常在拆分后的训练集上进行5次评估,然后计算准确率得分(RMSE、MSE、R²、MAPE或你选择的其他指标)的平均值,从而得出交叉验证得分。
下一步是使用在整个数据集上训练的原始模型对之前从未见过或预测过的保留测试集进行预测,这可以让你更好地了解你的模型在未来未知数据上的表现。
from sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_percentage_error
predicted_test = rf.predict(X_test)
rmse = mean_squared_error(y_test.values,predicted_test,squared=False)
print(rmse)
mape = mean_absolute_percentage_error(y_test, predicted_test)print(f"MAPE: {mape * 100:.2f}%")
计算完交叉验证和测试集的指标后,就该进行模型调优和优化了。
首先,要确保模型没有出现过拟合或欠拟合。
过拟合是指训练集/交叉验证的准确率远高于测试集的准确率。
欠拟合则相反。如果模型欠拟合,训练集的准确率会很差。
这基本上意味着模型没有从训练集中正确学习模式。
有几种方法可以处理过拟合和欠拟合,其中最知名的方法之一是超参数调优,即使模型一开始表现良好,这也是一种标准技术。
在我们的例子中,训练集的交叉验证得分为1549,测试集得分为1799。这些数字较大,因为我们处理的数据集中的值普遍较大(平均值:15499)。
测试集和交叉验证得分之间的差异并不大,因此我不太担心模型会出现过拟合或欠拟合。
超参数调优是优化模型性能并使指标达到最佳值的最终微调步骤。
以下是最简单的超参数调优技术之一——网格搜索的示例:
from sklearn.model_selection import GridSearchCV
param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [None, 10, 20, 30], 'min_samples_split': [2, 5, 10] }
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2, scoring='neg_root_mean_squared_error')
grid_search.fit(X_train, y_train)
print("Best Hyperparameters: ", grid_search.best_params_)
网格搜索虽然简单,但速度较慢,随机搜索是一个更快的选项,贝叶斯优化是另一个更快且更智能的选项。
根据网格搜索、随机搜索或贝叶斯搜索得到最佳超参数后,你应获取新的测试集指标,以确保它们确实改进了你的模型。
best_rf = grid_search.best_estimator_y_pred = best_rf.predict(X_test)
rmse_best_rf = mean_squared_error(y_test.values,y_pred,squared=False)
print(rmse_best_rf)
模型评估还可能包括检查模型的可解释性——以随机森林为例,可以查看特征重要性。
特征重要性可以告诉你哪些特征对模型的预测贡献最大。
feature_names = X_train.columnsfeature_importances = rf.feature_importances_
df_importance = pd.DataFrame({ 'Feature': feature_names, 'Importance': feature_importances})
df_importance = df_importance.sort_values(by='Importance', ascending=False)
太棒了——你已经顺利完成了数据收集、清洗、工程化处理、模型训练、评估和调优,并且拥有了一个在规划阶段所设定的标准下表现良好的训练模型。
你需要让这个模型对任何有需求的人开放使用,而不仅仅是局限于你和你的Jupyter笔记本。
模型部署本质上是将训练好的机器学习模型集成到生产环境中,使其能够进行实时预测或支持决策制定。
部署包括:
模型部署是一个复杂的过程,并且有一定的学习曲线,本文只是简单概括,大家想继续学需要阅读更深的资料教程。
现在已经部署了模型,但我们的工作还远远没有结束。
随着新数据的流入、环境的变化和指标的更新,我们必须准备好在必要时更新模型。
模型监控是指跟踪机器学习模型的性能和行为,以确保其在生产环境中继续按预期表现。
随着时间的推移,模型可能会开始退化——这意味着随着数据模式的变化,原始模型的预测能力不再像以前那样好。
可以定期计算平均绝对误差(MAE)或均方误差(MSE)等指标来检测退化。
仪表盘是监控数据模式随时间变化以及跟踪指标和标记异常的好方法。
可以设置警报来标记异常行为(如持续过度预测或预测不足),然后触发自动或手动模型重新训练。
请注意,最后的步骤——监控,往往以模型重新训练结束,这使你回到了起点。
定义新的问题和目标,收集新的数据(或者相同的数据,但意图采用不同的工程化处理),并最终重新训练和部署模型。
因此,你可以看到,机器学习不是一项一劳永逸的任务——它是一个真正的循环。
同样重要的是要注意,这个循环可以在过程中的任何时间点重新开始,而不仅仅是在结束时。
例如,如果在评估阶段发现模型过拟合,你可能需要重新收集数据,以不同的方式构建特征,并选择新的超参数,这将使你在循环中倒退几步或重新开始。
真正记住所有这些步骤的正确顺序并真正理解它们需要很长时间。
并且上面列出的每个步骤都有很多细微差别——这取决于模型类型、你要解决的问题等。
但最好的方法是不断练习,通过重复来学习。
另外我们打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过 5 次),包含时序、图结构、影像三大实验室,我们会根据你的数据类型来选择合适的实验室,根据规划好的路线学习 只需 5 个月左右(很多同学通过学习已经发表了 sci 二区以下、ei 会议等级别论文)如果需要发高区也有其他形式。
大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!

大家想自学的我还给大家准备了一些机器学习、深度学习、神经网络资料大家可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的死党、闺蜜、同学、朋友、老师、敌蜜!








