
AI和医学的结合一直是AI+领域的热门研究,但是对于很多学医的同学来说却不知道应该怎么去结合AI,不清楚有哪些方向是可以去研究的,所以今天小墨学长给大家分享一篇发表于 Nature medicine 的《A guide to deep learning in healthcare》也就是医疗健康领域的深度学习指南,由斯坦福大学与谷歌研究院联合出品,被引次数超过 2000次!
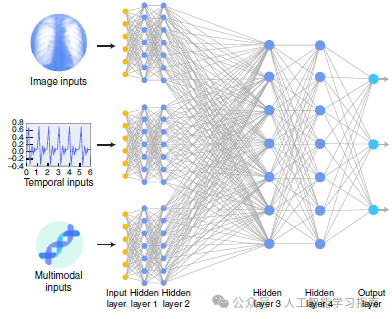
本文针对医疗健康领域,深入探讨了深度学习在计算机视觉、自然语言处理、强化学习以及通用方法中的应用。
大纲
另外为了让大家可以更好的学习AI加医学的知识,我给大家整理了一份AI+医学学习仓库
大家可以添加任意一位小助手让她发给你


医学成像中的计算机视觉
应用
图像级别的诊断在采用基于卷积神经网络(CNN)的方法上取得了显著成功。
值得注意的是,深度学习模型在多种诊断任务中达到了医生级别的准确性,包括从黑色素瘤中识别痣、糖尿病视网膜病变、心血管风险评估、眼底图像和光学相干断层成像(OCT)图像的转诊、乳腺X线图像中的乳腺病变检测以及磁共振成像的脊柱分析等。
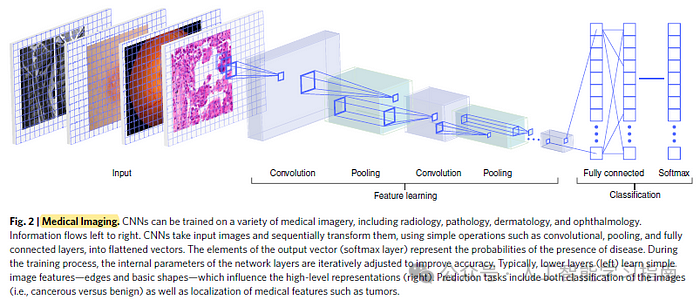
用于医学成像的计算机视觉
挑战
然而,在比较人类与算法性能的研究中,一个关键限制是缺乏临床背景——这些研究仅使用手头图像进行诊断。
这往往增加了人类读者诊断任务的难度,因为在现实临床环境中,医生可以获取医疗图像和补充数据,包括患者病史和健康记录、其他检查、患者陈述等。
构建用于新医学成像任务的监督深度学习系统的另一个限制是,难以获得足够大且标记好的数据集。
非结构化数据的自然语言处理(如电子健康档案EHRs)
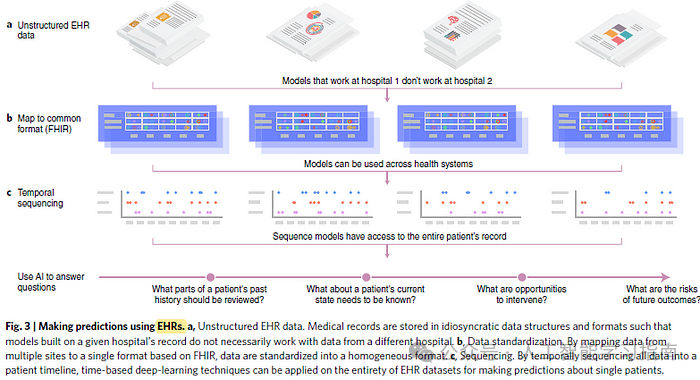
电子健康记录 (EHR) 上的自然语言处理 (NLP)
应用
深度学习通过卷积神经网络和循环神经网络对患者记录中发生的结构化事件的时序进行建模,以预测未来的医疗事件。
这项工作大多集中在重症监护医学信息市场(MIMIC)数据集上,例如预测败血症。
但该数据集仅包含来自单个中心的重症监护室(ICU)患者,因此尚不清楚从这些数据中得出的技术能否推广到更广泛的人群。
下一代自动语音识别和信息提取模型可能会开发出临床语音助手,以准确转录患者就诊情况。
医生在11小时的工作日中,有6小时都在处理电子健康档案中的文件,这导致医生疲惫不堪,减少了与患者相处的时间。
自动转录将缓解这一问题,并促进更实惠的书写服务。
挑战
主要挑战在于从对话中准确分类每个医疗实体的属性和状态,同时准确总结对话内容。
手术任务的强化学习
应用
可以从深度强化学习中受益的医疗健康领域之一是机器人辅助手术(RAS)。
深度学习可以通过使用计算机视觉模型(如CNN)感知手术环境,以及使用强化学习方法学习外科医生的物理动作,来增强RAS的鲁棒性和适应性。
这些技术支持高度重复且时间敏感的手术任务的自动化和加速,如缝合和打结。
计算机视觉技术(如用于目标检测/分割和立体视觉的CNN)可以从图像数据中重建开放伤口的景观,并通过解决路径优化问题生成缝合或打结轨迹。
挑战
这些技术对于全自主机器人手术或微创手术特别有利,以现代腹腔镜手术(MLS)为例,在半自主远程操作期间的主要挑战之一是正确定位手术场景中附近器械的位置和方向。
深度学习在手术机器人领域发展的另一个挑战是数据收集。
深度模仿学习需要大量训练数据集,每个手术动作都需要很多示例。
由于许多手术细微且独特,因此很难为更一般的手术任务收集足够的数据。
基因组学的通用深度学习
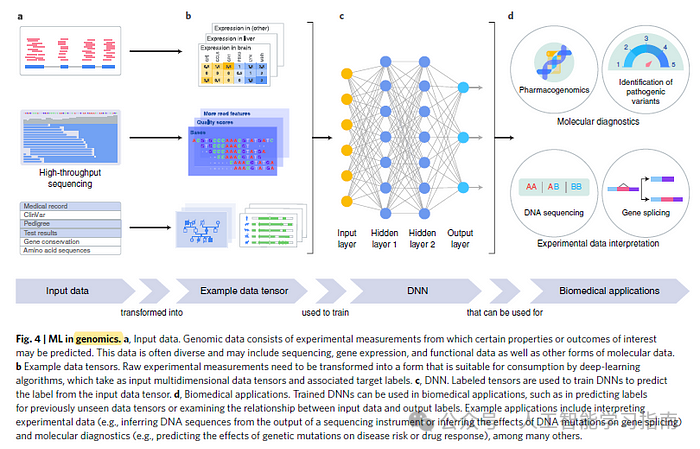
用于基因组学的广义深度学习 (DL)
应用
现代基因组技术收集从个人DNA序列到血液中各种蛋白质数量的广泛测量数据,最终帮助临床医生提供更准确的治疗和诊断。
通用深度学习流程包括获取原始数据(如基因表达数据),将这些原始数据转换为输入数据张量,并通过神经网络输入这些张量,然后如上文所述,为特定的生物医学应用提供支持。
一组机会集中在全基因组关联(GWA)研究上,即大型病例对照研究,旨在发现影响特定性状的因果基因突变。
基因组数据可以直接作为疾病发生和进展的生物标志物。
例如,血液中含有从身体其他部位细胞中释放出来的游离DNA小片段。
这些片段是无创指标,可指示器官排斥反应(即免疫系统攻击移植细胞)、细菌感染和早期癌症。
挑战
分析GWA研究需要能够扩展到非常大患者队列并处理潜在混杂因素的算法。
这些挑战可以通过为深度学习开发的优化工具和技术来解决,包括随机优化和其他现代算法,以及与用于并行计算扩展的软件框架相结合,以及通过处理未见混杂因素的建模技术来解决。
在不久的将来,模型将把外部模态和生物数据的其他来源整合到GWA研究中,例如医学图像或剪接和其他中介分子表型的测量。
生物标志物数据往往噪声较大,需要复杂的分析。








