本文约1000字,建议阅读5分钟
本论文介绍了几种概率机器学习算法,可用于贝叶斯优化循环中,以发现新分子。

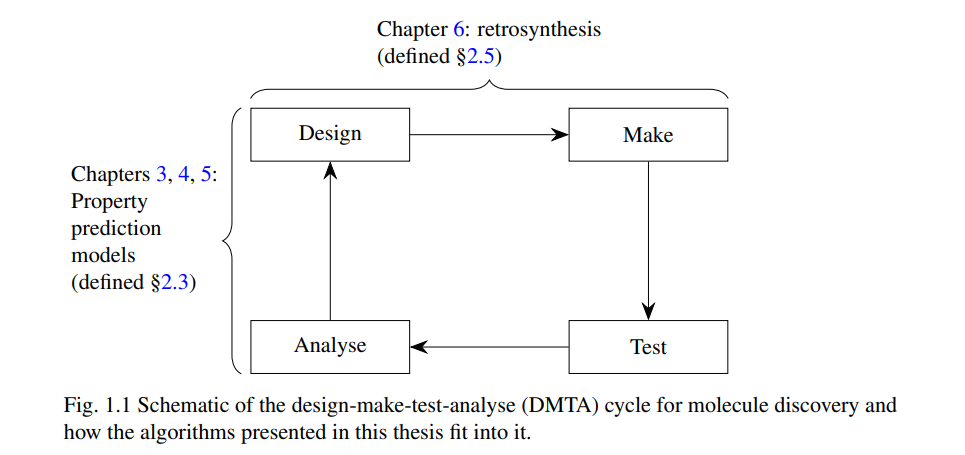
发现新分子使人类能够解决健康、农业、能源等领域的问题。分子发现的关键挑战在于,所有可能分子的空间远大于我们能够通过有限资源进行实验测试的分子数量。面对这一挑战,最好的选择是根据我们当前的知识和每次测试可能获得的信息预期,明智地选择要测试的分子。在机器学习中,这种方法通常称为贝叶斯优化,并且已被应用于许多其他问题,如调优机器学习模型的超参数。尽管理论上贝叶斯优化可以直接应用于新分子的发现问题,但分子的离散特性意味着需要新的模型和算法,才能使贝叶斯优化在实践中发挥作用。本论文介绍了几种概率机器学习算法,可用于贝叶斯优化循环中,以发现新分子。带权重重新训练的潜在空间优化(第3章)和基于隐函数定理的自适应深度核拟合(第4章)是两种使用高斯过程与深度神经网络核函数相结合的算法,用于建模分子结构与某些感兴趣性质之间的关系。Tanimoto随机特征(第5章)则允许将一种已建立的化学信息学模型(近似)应用于大规模数据集。最后,逆合成回退(第6章)采用了一种新的概率形式化的逆合成问题,来估计一个分子是否可以合成,从而决定它是否应该被贝叶斯优化考虑。这些算法共同构成了一套工具,可以用来自动化和智能地发现新分子。



数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU









