经常有面试题问到 MySQL not in 走索引吗?偶尔也会有同事说,千万别用 not in, 不走索引性能贼差,not in 性能好不好和对应的字段的区分度有关,那么这是真的吗?
今天小匠就带大家深入了解一下这个问题,首先我们需要使用 explain 关键字,所以需要了解一下这个关键字。explain 即为执行计划,可以输出某条 MySQL 语句的执行信息,以便让我们可以判断是否命中索引,是否需要优化。
文章提纲
首先我们创建一个表,插入一些数据以方便下文的测试。
CREATE TABLE test (
id INT NOT NULL AUTO_INCREMENT,
second_key INT,
text VARCHAR(100),
PRIMARY KEY (id),
KEY idx_second_key (second_key)
) Engine=InnoDB CHARSET=utf8;
INSERT INTO test VALUES
(1, 10, 't1'),
(2, 20, 't2'),
(3, 30, 't3'),
(4, 40, 't4'),
(5, 50, 't5'),
(6, 60, 't6'),
(7, 70, 't7'),
(8, 80, 't8');
运行 explain 命令我们得到如下内容
mysql> explain select * from test \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 13
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
这里内容很多,但是值得我们关注的只有这几个字段
下面我们逐一讲解下
type 表示 MySQL 在执行当前语句时候执行的类型,有这几个值 system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL。
- system 比较少见,当引擎是 MyISAM 或者 Memory 的时候并且只有一条记录,就是 system,表示可以系统级别的精准访问,这个不常见可以忽略。
- const 查询命中的是主键或者唯一二级索引等值匹配的时候。比如
where id = 1 - eq_ref 连表时候可以使用主键或者唯一索引进行等值匹配的时候。
- ref 和 ref_or_null, 当非唯一索引和常量进行等值匹配的时候。只是 ref_or_null 表示查询条件是
where second_key is null - fulltext, index_merge不常见跳过。
- unique_subquery 和 index_subquery 表示联合语句使用 in 语句的时候命中了唯一索引或者普通索引的等值查询。
-
range 表示使用索引的范围查询,比如
where second_key > 10 and second_key < 90 - index 我们命中了索引,但是需要全部扫描索引。
- All,这个太直观了,就是说没有使用索引,走的是全表扫描。
接下来说一下 rows,MySQL 在执行语句的时候,评估预计扫描的行数。
最后就是关键的内容 Extra,别看他是扩展。但是它很重要,因为他更好的辅助你定位 MySQL 到底如何执行的这个语句。我们选择一些重点说一说。
- Using index,当我们查询条件和返回内容都存在索引里面,就可以走覆盖索引,不需要回表,比如
select second_key from test where second_key = 10 - Using index condition,经典的索引下推,虽然命中了索引,但是并不是严格匹配,需要使用索引进行扫描对比,最后再进行回表,比如
select * from test where second_key > 10 and second_key like '%0'; - Using where,当我们使用全表扫描时,并且 Where 中有引发全表扫描的条件时,会命中。比如
select * from test where text = 't' - Using filesort,查询没有命中任何索引,需要在内存或者硬盘中排序的,比如
select * from test where text = 't' order by text desc limit 10
你也可以发现,无论是 type 还是 Extra,他们都是从前往后性能越来越差的,所以我们在优化 SQL 的时候,要尽量往前面的优化。好了到这里我们就简单介绍了完了关键词了,但是到我们可以分析 not in 是否命中索引还差点内容。我们需要了解一下 MySQL 的索引原理。下面是一个 B+ Tree 的索引图,也是 MySQL 索引的原理。
MySQL 每一个索引都会构建一棵树,我们也要做能做心中有“树”。那么我心中的两棵树是这个样子。
为了快速讲述本文重点,图片适当的忽略的一些 B+ 树的细节。
- 第一棵树是主键索引,每一个 Page 就是 B+树中最重要的概念——页,这里我们也叫它节点。非叶子节点不存储数据,只存储指向子节点的指针,叶子节点存储主键和其他所有列值。其中每个节点通过双向指针链接左右节点组成了双向链表,页内部每个块可以理解为一条记录,页内多条记录通过单向指针链接,组成单链表,所有的页和页内的记录都是根据主键从左到右递增的。
- 第二棵树是二级索引,非叶子节点不存储数据,只存储指向子节点的指针,叶子节点存储二级索引和主键,所有的页和页内的记录都是根据二级索引从左到右递增的,这些是和主键索引最大的不同,其余的一样。
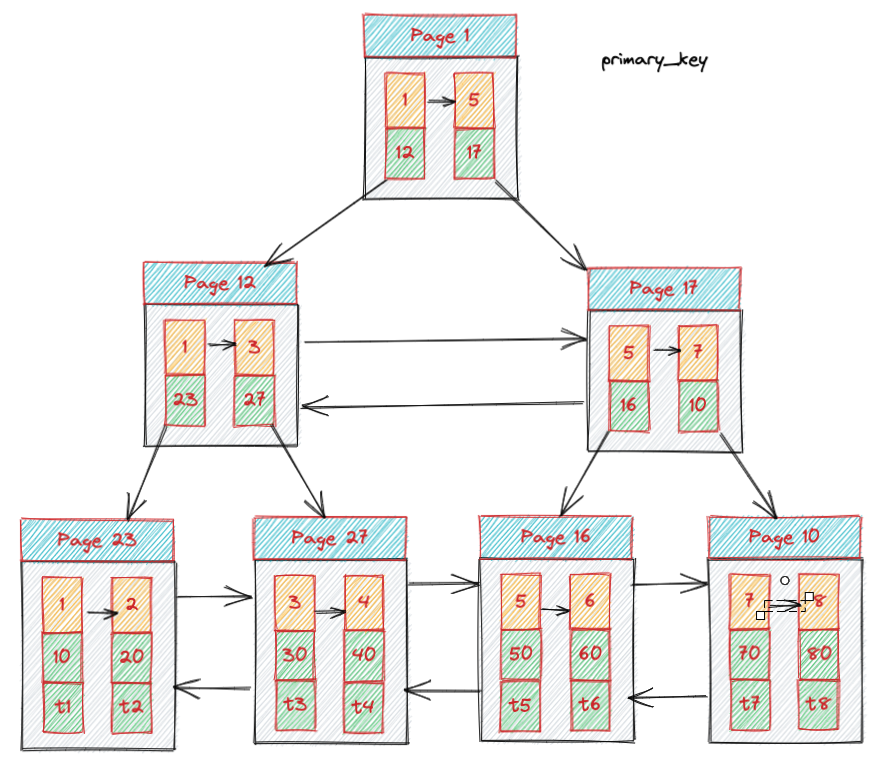
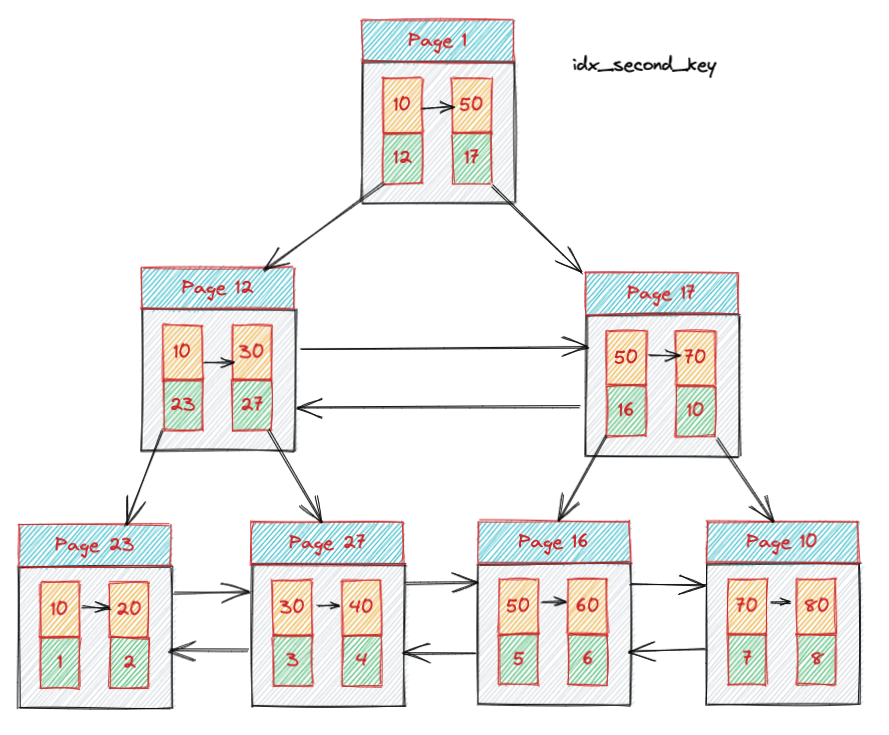
那么我们开始分析一下索引的查询原理
select * from test where second_key = 40;
这条语句的查询流程是:
- 因为 second_key 有索引,所以走的是 idx_second_key 二级索引生成的树。
- 通过检查 Page 1 发现我们需要查询的记录在 Page 12 所属的叶子节点内。
- 通过查询 Page 12 发现我们需要查询的记录在 Page 27 节点内。
- 从 Page 27 的节点内从左向右遍历,得到 40 节点
- 因为二级索引里面没有数据,所以需要回表,回表的时候重新通过 ID 4 查找 primary_key 主键索引树。
- 依照刚才的顺序,最终找到内容在 Page 27 里面的节点,返回。
同时我们运行一下 explain 验证一下,type 是 ref,走的是非唯一索引的等值匹配。
explain select * from test where second_key = 40 \G;
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: ref
possible_keys: idx_second_key
key: idx_second_key
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
上面是一个非常简单的查询,那么我们看一下稍微复杂的。
select * from test where second_key > 10 and second_key 50;
这条语句的查询流程是:
- 因为 second_key 有索引,所以走的是 idx_second_key 二级索引生成的树。
- 因为索引是从左到右递增的,所以我们先找 second_key > 10,通过前面的讲解,我们会定位到 Page 23 的第 2 个节点。
- 因为叶子节点是双向链表,所以我们不需要重新从根节点找其他内容,我们直接从左向右遍历比较,直到内容 >= 50 停止,这样我们会定位到 Page 16 的第 1 个节点停止。
- 那么我们拿到的结果就是 Page 23 和 Page 27 的 20,30,40 节点。
- 然后回表,分别找到 20,30,40 对应的主键 2,3,4 的内容,返回数据。
我们继续运行一下 explain,type 是 range 表示使用索引的范围查询, Extra 里面有了内容。Using index condition 表示 range 查询的时候使用了索引进行比较以后才进行的回表。
explain select * from test where second_key > 10 and second_key 50 \G;
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: range
possible_keys: idx_second_key
key: idx_second_key
key_len: 5
ref: NULL
rows: 3
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
好的,那么进入了本文的高潮阶段,下面的语句怎么执行的你知道吗?
select * from test where second_key not in(10,30,50);
凭着我们的手感,这次先运行 explain 吧,坏了,果不其然,type 是 ALL,全表扫描,小匠你又骗人?这不是没走索引吗?
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: ALL
possible_keys: idx_second_key
key: NULL
key_len: NULL
ref: NULL
rows: 8
filtered: 75.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
好吧,尴尬了。再来,那我们换个语句试试吧。
select second_key from test where second_key not in(10,30,50);
再运行一次试试,看能不能搬回来一局。It's Nice。这次就走索引了诶。
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: range
possible_keys: idx_second_key
key: idx_second_key
key_len: 5
ref: NULL
rows: 6
filtered: 100.00
Extra: Using where; Using index
那么为什么第一次没有走索引呢?好了不绕弯子了,我们解密吧。
MySQL 会在选择索引的时候进行优化,如果 MySQL 认为全表扫描比走索引+回表效率高, 那么他会选择全表扫描。回到我们这个例子,全表扫描 rows 是 8,不需要回表;但是如果走索引的话,不仅仅需要扫描 6 次,还需要回表 6 次,那么 MySQL 认为反复的回表的性能消耗还不如直接全表扫描呢,所以 MySQL 默认的优化导致直接走的全表扫描。
那么我就是想 select * 还走索引怎么办呢?好的,安排
select * from test where second_key not in(10,30,50) limit 3;
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: range
possible_keys: idx_second_key
key: idx_second_key
key_len: 5
ref: NULL
rows: 6
filtered: 100.00
Extra: Using index condition
如释重负啊,这次不就是走索引了吗?因为 limit 的增加,让 MySQL 优化的时候发现,索引 + 回表的性能更高一些。所以 not in 只要使用合理,一定会是走索引的,并且真实环境中,我们的记录很多的,MySQL一般不会评估出 ALL 性能更高。。
那么最后还是说一下 not in 走索引的原理吧,这样你就可以更放心大胆的用 not in 了?再次回到我们这个索引图。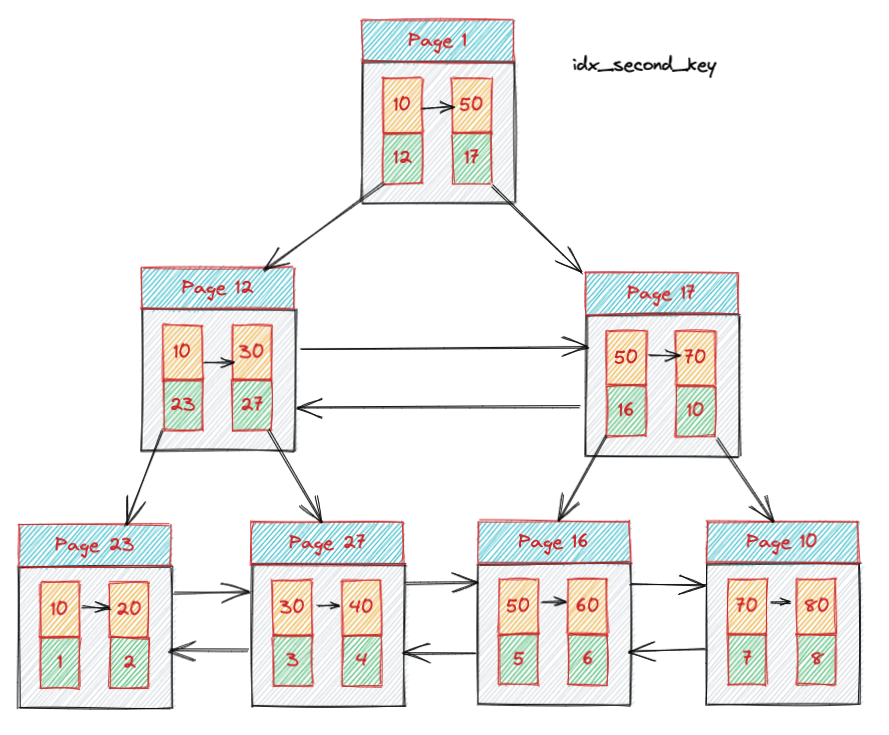
select * from test where second_key not in(10,30,50) limit 3;
这个语句在真正执行的时候其实被拆解了
select * from test where
(second_key 10)
or
(second_key > 10 and second_key 30)
or
(second_key > 30 and second_key 50)
or
(second_key > 50);
上文中我们已经讲过 > and < 这种情况如何使用索引了,那么这个被拆解过的语句你是不是会自己分析了呢?这个语句分解完成以后就相当于,4 个开区间,分别的寻找一次开始节点,然后依照索引查找就可以了,所以在遇到有人和你说 not in 不走索引知道怎么说了吗?
这篇文章是之前筹划的《程序员十万个为什么》 系列文章,如果你有更多的疑问可以给我留言,也可以去查看我的系列文章专辑。
参考资料
[1]《程序员十万个为什么》: https://www.yuque.com/majiangbiji/vx3bzb/iowp57#jaIK3









