2025 年 1 月 20 日,中国杭州的初创公司深度求索(DeepSeek)发布了一款大语言模型(LLM)——DeepSeek-R1,这是一个部分开源(训练数据未公开,因此并非完全开源)的“推理”模型,其能够以与 OpenAI 于 2024 年年底发布的最先进的专注于“推理”的大语言模型 ChatGPT-o1 相近的水平解决一些科学问题。
更重要的是,DeepSeek-R1 的训练成本远低于美国科技巨头们开发的主流大语言模型,DeepSeek-R1 的高性能与超低成本引起了全世界科学界的惊叹。
2025 年 1 月 28 日,意大利那不勒斯第二大学的研究人员在预印本平台 medRxiv 上发表了题为:Comparative Evaluation of Advanced AI Reasoning Models in Pediatric Clinical Decision Support: ChatGPT o1 vs. DeepSeek-R1 的论文。
研究团队在儿科临床决策支持中比较评估了两款 AI 推理模型:ChatGPT o1 vs. DeepSeek-R1。评估结果显示,ChatGPT o1 的准确率胜过 DeepSeek-R1(92.8% vs 87.0%)。
ChatGPT o1 所使用的“思维链”(CoT)推理技术使得回答更加结构化和可靠,降低了出错的风险。DeepSeek-R1 虽然回答正确率稍低,但因其开源的特性以及新兴的自我反思能力,展现出了更出色的可及性和适应性。
采用先进的推理模型,例如 ChatGPT o1 和 DeepSeek-R1,在临床决策支持方面迈出了关键一步,尤其是在儿科领域。ChatGPT o1 采用“思维链”(Chain-of-Thought,CoT)推理来增强结构化问题的解决能力,该模型的访问是通过每月付费订阅获得的,每周限制 50 条消息;而 DeepSeek-R1 则通过“强化学习”(Reinforcement Learning,RL)引入了自我反思能力,该模型是免费开源的,每天限制 50 条消息。该研究旨在利用 MedQA 数据集评估 ChatGPT o1 和 DeepSeek-R1 这两款推理模型在儿科场景中的诊断准确性和临床实用性。研究团队从 MedQA 数据集中选取了 500 道儿科领域选择题,并将其呈现 ChatGPT o1 和 DeepSeek-R1。每道选择题都包含四个或更多的选项,其中只有一个是正确答案。研究团队在统一条件下对 ChatGPT o1 和 DeepSeek-R1 进行了评估,评估指标包括回答的准确率、科恩卡帕系数和卡方检验,以评估一致性及统计显著性。通过对答案的分析,确定这两款推理模型在解答临床问题方面的有效性。结果显示,在 500 道问题中,ChatGPT o1 回答正确了 464 道,准确率为 92.8%;DeepSeek-R1 回答正确了 435 道,准确率为 87.0%。有 413 道题 ChatGPT o1 和 DeepSeek-R1 均回答正确,有 14 道题二者均回答错误,有 51 道题 DeepSeek-R1 回答错误而 ChatGPT o1 回答正确,有 22 道题 DeepSeek-R1 回答正确而 ChatGPT o1 回答错误。ChatGPT o1 与 DeepSeek-R1 模型之间的比较分析,突显了它们在性能和设计原则上的差异,它们在准确率指标和临床应用潜力方面展现出不同。ChatGPT o1 模型以 92.8% 的正确率略胜一筹,高于 DeepSeek-R1 的 87.0%,这表明 ChatGPT o1 在提供正确答案方面更具可靠性。这一特点使得 ChatGPT o1 在临床环境中特别适用,尤其是在诊断错误需降至最低的情况下。例如,在处理有败血症迹象的新生儿等危急情况时,ChatGPT o1 能够提供更可靠的答案,从而降低严重临床后果的风险。这一结果可能归因于其采用了“思维链”(CoT)推理技术,该技术使模型能够通过将复杂问题分解为连续步骤来解决,从而增强结构化推理能力。然而,ChatGPT o1 的可及性受到显著的实际限制,它需要付费订阅,且每周仅允许 50 条消息,这可能会成为其应用的阻碍。在资源有限的环境中,尤其是在密集的教育活动或广泛的临床模拟期间,这种情况尤为明显。DeepSeek-R1 虽然准确率略低,但由于其开源的特性,成为了一种易于获取且创新的解决方案。这一特点使其在资源有限的医疗环境中或需要免费且灵活工具的学术项目中特别有用。DeepSeek-R1 在预训练阶段采用了基于“强化学习”(RL)的方法,使模型能够在不依赖传统监督预训练的情况下发展出高级推理能力。DeepSeek-R1 的一个显著特点是其正在形成的自我反思能力(即自我进化),通过这种能力,模型能够自主验证并优化其逻辑步骤,从而在复杂任务上提升性能。这一能力在诸如“对于疑似病毒性脑炎的儿童,接下来的管理步骤是什么?”这类需要多层次分析的复杂查询中可能特别有用。科恩卡帕系数(K = 0.20)表明,这些模型之间的一致性较低,反映出它们各自独特的推理策略。该系数在 -1到1 之间,-1 代表完全不一致性,0 代表随机一致性,1 代表完全一致性。从技术角度来看,这两个模型各有特色:ChatGPT o1 通过实施“思维链”(CoT)推理等高级技术来最大化结构化推理,使其特别适合复杂的临床环境。而 DeepSeek-R1 则以灵活性和免费可用为特点,使其在资源有限的场景中更具可及性。最后,论文作者表示,这项研究凸显了 ChatGPT o1 在提供准确和连贯的临床推理方面具有优势,使其高度适用于儿科危急情况。而 DeepSeek-R1 凭借其灵活性和可及性,在资源有限的环境中仍是一个宝贵的工具。将这两款模型组合成一个集成系统,可以利用它们的互补优势,优化不同临床情境下的决策支持,例如,将复杂和高风险病例的分析交给 ChatGPT o1,而将 DeepSeek 用于直接回答问题和处理重复性流程,从而确保整体效率更高。此外,有必要开展进一步研究,以探索它们在多学科医疗团队中的整合,以及在真实世界临床环境中的应用。https://www.medrxiv.org/content/10.1101/2025.01.27.25321169v1
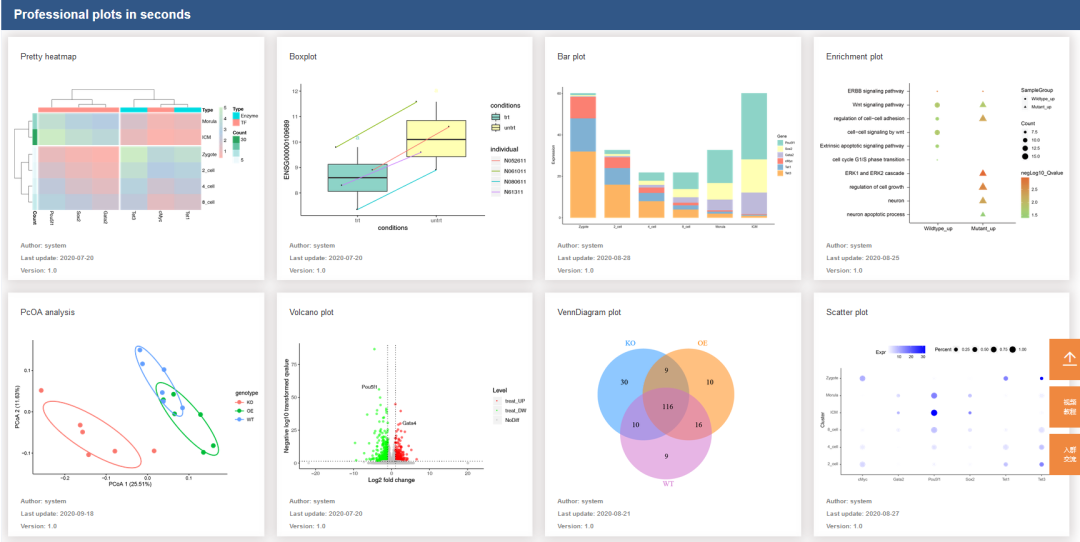
高颜值免费 SCI 在线绘图(点击图片直达)
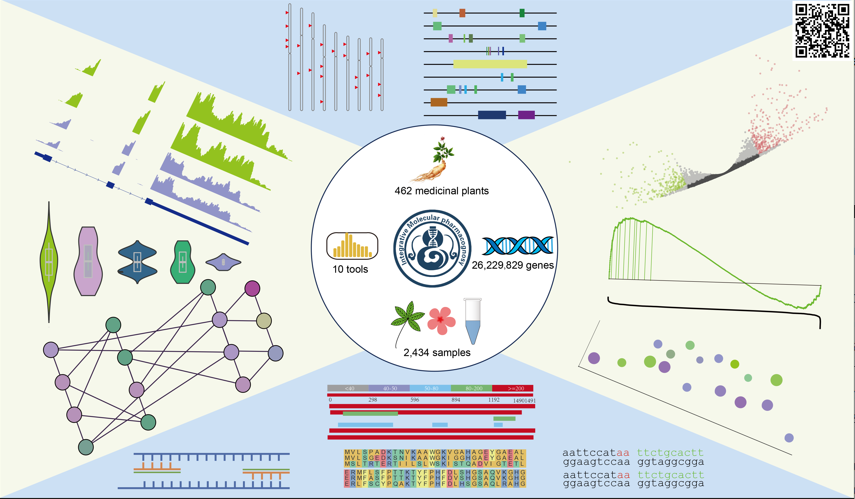
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
机器学习