专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
微软在官网发布了专用于游戏领域的创新大模型——Muse。
虽然Muse基于Transformer架构,但创建游戏场景的方式却非常独特,并不依赖传统的文本提示,而是通过游戏画面和控制器操作的序列化数据作为输入提示,从而生成连贯的游戏场景和玩法,同时更符合游戏机制和物理规则的游戏内容。
例如,仅通过一张游戏截图,Muse 就能迅速生成多个可能的后续游戏画面,并通过 Xbox 手柄控制角色生成与开发者操作相匹配的后续游戏内容,游戏开发效率非常高。

游戏开发是一个高度复杂的过程,涉及创意构思、角色设计、场景搭建、玩法策划等多个环节,需要众多专业人员协同合作。
以一个小型独立游戏工作室开发新游戏关卡为例,CEO 提出新角色概念后,角色开发人员需花费数天甚至数周时间绘制概念草图并反复修改,随后3D模型师进行建模,动画师负责角色动画制作,程序员编写角色行为代码,最后由关卡设计师与环境师共同打造适配的关卡。
整个流程繁琐复杂,且需要大量的创意投入和时间成本。现在,通过Muse可以轻松完成这些复杂的开发流程。
Muse架构简单介绍
Muse与ChatGPT一样使用了著名的Transformer作为核心架构。为了将游戏画面和玩家操作转化为模型能够处理的序列化数据,还引入了VQGAN图像编码器。
VQGAN的作用是将游戏画面中的每一帧图像编码为一系列离散的tokens,不仅保留了原始图像的关键信息,还能够被Transformer模型高效处理。
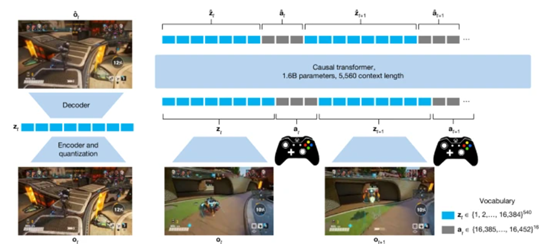
每个游戏画面被编码为540个离散tokens,这些标记构成了模型输入的一部分,帮助模型能够在生成过程中灵活地处理图像数据,同时保持对游戏画面细节的高保真度。
玩家的操作也被离散化处理,以适配模型的输入格式。玩家控制器的按钮操作被直接编码为离散值,而摇杆的连续操作则被划分为11个离散区间。
在训练过程中,Muse利用了大规模的计算资源和优化策略,例如,1.6B参数的Muse模型在训练时使用了高达1×10²²算力,使得模型能够在复杂的3D游戏环境中学习到更精细的动态关系,从而生成更加真实和连贯的游戏玩法序列。
为了进一步提升模型的性能,微软还在训练过程中采用了AdamW优化器,并结合了余弦退火学习率策略,在训练过程中动态调整学习率,从而提高模型的收敛速度和最终性能。模型还采用了批量归一化和权重衰减等技术,以防止过拟合并提高模型的泛化能力。
高质量训练数据
为了提升Muse模型的生成性能,微软与Ninja Theory工作室合作获取了《Bleeding Edge》的大量真实玩家游戏数据。
为了收集训练数据,微软从游戏中提取了超过50万场玩家的游戏会话,涵盖了各种游戏场景、角色行为和玩家操作。同时对这些数据经过清洗和匿名化处理,以确保玩家隐私和数据安全。
游戏画面的图像帧被提取为300×180像素的分辨率,以确保模型能够捕捉到足够的细节;控制器操作则被离散化处理,包括按钮操作和摇杆的移动方向。这些数据被整合为时间序列,每个序列包含10帧图像和对应的控制器操作,形成了模型的输入和输出对。
最终,从这些数据中提炼出了两个数据集:7 Maps和 Skygarden 数据集。7 Maps 数据集包含 60,986 场比赛,约500,000个玩家轨迹,数据总量达到27T,相当于7年多的游戏时间。
经过下采样到10Hz后,约有 14 亿帧数据,并按照80:10:10 的比例划分为训练集、验证集和测试集。Skygarden 数据集则聚焦于单个地图,包含 66,709 个玩家轨迹,约 3.1 亿帧数据,同样进行了80:10:10 的划分和10Hz下采样处理。
Muse测试数据
为了测试Muse的性能,微软使用了连贯性、多样性和持续性三种测试基准进行了综合评估。
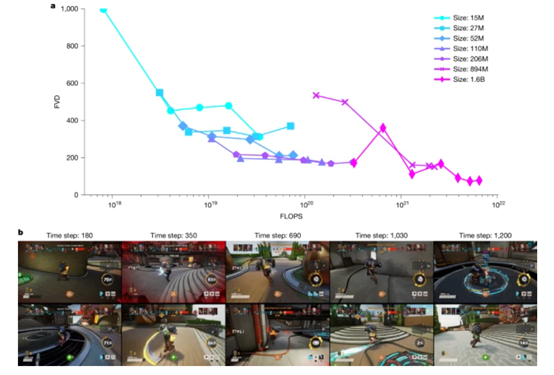
在连贯性测试中,团队使用了FVD指标来衡量生成游戏画面与真实游戏画面之间的相似度。结果显示,随着模型规模的增大和计算资源的增加,FVD指标显著降低,表明生成的游戏画面与真实画面之间的差异越来越小。
例如,1.6B参数的MUSE模型在高分辨率图像上的表现尤为出色,能够生成长达2分钟的连贯游戏画面。

在多样性测试中,团队使用了Wasserstein距离来衡量生成动作与真实人类动作之间的分布差异。测试结果表明,MUSE模型能够生成多种不同的游戏玩法,且生成的动作分布与人类玩家的真实动作分布高度一致。
此外,团队还通过定性分析展示了模型生成的多样化行为,例如,玩家角色可以选择不同的路径、使用不同的技能,甚至在外观上也存在差异。

持续性测试则通过在游戏画面中插入新的元素,包括游戏角色、道具或地图等元素,来评估模型是否能够将这些修改融入后续生成的画面中。
结果显示,当模型在生成过程中被提示包含这些修改后的画面时,能以超过85%持续生成包含这些元素的画面。这表明MUSE模型能够有效地支持创意人员的迭代创作过程。
微软游戏研究负责人KatjaHofmann表示,研发Muse的主要原因是2022年11月OpenAI发布了ChatGPT。当时意识到基于 Transformer 架构的AI模型在大量数据训练下的巨大商业潜力,同时手中也有丰富的游戏数据,于是想利用这些数据训练出更好的游戏模型。
目前,Muse模型可以在微软的Azure AI Foundry上体验。
本文素材来源微软,如有侵权请联系删除
END











