一、引言
深度神经网络在近期取得了诸多科学成果——从让探测器在崎岖的火星地形上着陆,到打造功能强大的聊天机器人,再到革新疾病诊断方式。深度神经网络通常将非结构化数据(例如文本、文档图像扫描、卫星和其他图像、视频和音频)映射到一个连续的向量空间。在上述例子中,这些向量被用于计算操控航天器的指令,根据提示以自回归方式预测下一个出现的单词,或者识别图像中是否存在肿瘤。类似地,经济学家可能会使用神经网络来识别街景图像中非正式摊贩的存在,或者衡量公司文件或政府文档中提及的主题或人物。从本质上讲,深度学习是一种从经验示例中学习数据表征的方法。这些表征将高维非结构化数据简化为连续向量。深度神经网络在多个抽象层次学习表征,通过结合非线性神经网络模块,每个模块利用习得的权重,将神经网络前一层的表征转换为稍显抽象的表征(“深度”一词即表示这些多层的转换)。这些权重通过最小化损失函数来估计,该损失函数会将模型针对某项任务的预测结果与实际示例进行比较。
相较于直接处理原始文本或图像,为何要使用神经网络将原始数据转换为这些向量表征呢?首先,深度神经网络并非仅从当下的问题中学习。相反,它们在接触大规模数据的过程中,会将相关信息融入其参数之中。在预训练阶段,一个现代语言模型或视觉模型会接触数百万的文本或图像,从而学习语言或视觉的基本结构。在处理非结构化数据时,接触海量数据对于实现卓越的性能至关重要,因为人类语言和视觉极其复杂。这一原理被称为迁移学习,它是深度神经方法取得成功的核心所在。此外,原始像素或单词缺乏语境,而语境对于解读其含义必不可少。深度神经网络提供了一种强大的方法来计算融入语境的表征。它们将词汇或像素映射为向量,这些向量依赖于邻近的其他词汇或像素,其参数主要通过大规模预训练习得。
最后,原始文本和图像在计算上很笨拙。相比之下,针对连续向量计算有高度优化的工具。例如,Silcock et al. (2023) 在一块中端图形处理器(GPU)上,仅3小时内就完成了1014次精确的向量相似度计算。这意味着数据能够以前所未有的规模进行分析。理论需要通过数据来检验,虽然更多的数据无法解决因果关系方面的难题,但总体而言,它能为经济学家提供更精细的信息,以检验各种假设。
本综述旨在弥合深度学习前沿研究与经济应用之间的差距。它聚焦于从非结构化文本或图像中估算低维结构化数据,这种情况适用于基本事实不存在争议,但因问题规模庞大而需实现自动化提取的场景。然后,这些结构化数据可用于因果分析或描述性分析,无论是作为结果变量、内生变量、工具变量还是控制变量。目前经济学家手动完成或通过传统方法执行的任务(如记录链接、文本分类、文档扫描数字化),从此可以更准确地大规模自动化。深度学习还有助于提取新的数据。与 Gentzkow, Kelly and Taddy (2019)之前的综述一样,本综述强调将文本作为数据,但采用的是自该文章发表以来所开发的方法。
本综述中的许多应用都属于广义的分类范畴:将高维非结构化数据映射到离散类别中。这些类别可以识别卫星图像中存在的物体类型,或者文档图像扫描件中的数字和文字。另外,其还可以识别文本的主题、文本转载的原始出处,或者文本中提及的特定个人或地点。语言模型可用于将原始文本编码为低维密集向量表征,一种是针对全文的,另一种是针对每个单独词汇的(其中“密集”表示向量在每个位置都有非零值)。研究人员可以通过在语言模型中添加一个分类器层,利用这些向量表征来预测文本是否涉及特定主题、提及了哪些地点等等。图像分类的原理与之类似。生成式人工智能模型也可以被激发来进行这些分类估算。或者,研究人员也可以直接使用被称为嵌入的密集向量表征。

图1展示了进行分类的流程图。首先要问的问题是:“类别是否事先已列举?” 有时,类别并不明确,或者研究人员在将模型应用于新场景时,可能希望在不重新训练模型的情况下添加类别,这时分类器会利用语言模型或视觉模型的最后一层,为每个类别计算一个分数。因此,只有在类别已明确指定且在训练中出现时,才能对其进行估计。如果类别未明确指定,研究人员需要直接使用嵌入(embeddings)。此外如果类别众多,例如在记录链接中,每个唯一实体都可视为一个类别,由于估计分类器存在计算限制,那么研究者同样需要使用嵌入向量。
当类别事先已明确指定且数量适中时,分类器或生成式人工智能可能都很适合解决该问题。 如果应用场景与用于预训练神经网络的数据不同(在处理历史数据、文档扫描数据或某些特定专业场景时这种情况很常见)那么与预训练语料库相比就会存在显著的领域偏移,可能需要调整定制的分类器以实现良好性能。类别的定义细节也很重要。对于简单任务,使用现成的生成式人工智能模型(如OpenAI的GPT)将分类构建为文本生成可能效果良好。对于更细微复杂的任务,经过定制训练的分类器可以通过接触细粒度的示例从而更好地捕捉其中的细微差别。如果拿不准,研究人员可以先尝试现成的方法,若性能不理想,再转而使用定制的分类器。本综述表明,虽然在文本分类任务中,定制训练的分类器通常优于GPT,但生成式人工智能和定制分类器在简单任务上都表现出色。本综述还会考量这些方法的成本。

表1总结了本综述中的各项应用。其中大多数可归结为分类问题,本文还回顾了回归分析,即在回归中使用神经网络从文本或图像中估算连续值。在深度学习出现之前,不同领域的问题采用截然不同的解决方式,大量依赖针对特定语言的具体特征或特定类型图像等精心设计的规则;而深度学习具有显著的泛化能力。自然语言处理(NLP)、计算机视觉和音频处理在本综述所讨论的各种不同应用中,都采用相同的前沿神经网络架构。诸多神经网络应用超出了本综述的范围。它未涵盖如Korinek(2023)所探讨的,语言模型如何更广泛地用于提高经济学家的工作效率。它也不涉及深度学习之外的机器学习方法,比如那些应用于结构化数据的方法(这类方法通常使用较浅的网络), Athey和Imbens(2019)的一篇综述对这些方法进行了总结。此外,本文不研究使用深度神经网络来计算组合优化和高维动态随机一般均衡(DSGE)问题的近似解。计算这些近似解需要训练一个神经网络,将原始问题映射到一个连续向量空间,同时保留问题的基本属性。这样做很有用,因为在这个空间中计算近似解比传统方法要快得多,从而能够对大得多的问题进行近似求解。
这与本综述所涵盖的方法有许多相似之处,但应用差异较大,需要单独论述。读者可参考Fern'andez-Villaverde (2024)和Vitercik(2023)的课程。最后,有一小部分文献在因果框架中直接使用深度神经网络。例如,Lynn、Kummerfeld和Mihalcea(2020)使用分类器和实验来研究文本的变化如何对决策产生因果影响。虽然在对文本进行实验性操控时,这种方法有其用武之地,但研究人员通常希望从高维非结构化数据中提取低维表征(例如文本的主题、卫星图像中的物体、表格扫描中的数字、哪些文本记录指向同一家公司),并在因果估计方程中使用这些低维表征,而非非结构化数据本身。因此,本文重点在于预测这些低维特征。由于相关文献较新且发展迅速,本综述未尝试总结这些预测在经济研究中的应用情况。
读者可能想知道这篇综述多久会过时。不妨想想那个常用的比喻:神经网络就像乐高积木,不同的神经网络组件可以通过各种方式组合,以达成不同目标,或者为实现同一目标而采用更先进的版本。本综述聚焦于一些框架,随着相关研究的推进,在这些框架中很容易替换新的神经网络组件,例如,用视觉变换器(Dosovitskiy et al.,2020)替代旧的卷积神经网络,或者用最新的语言模型更新BERT语言模型主干(Devlin et al.,2019)。技术和实施细节——这些内容最有可能随着研究进展而变化——可在配套的EconDL网站获取:https://econdl.github.io/。该网站提供了一个按核心主题组织的知识库,还包含指向面向经济学家的开源软件包以及利用深度学习构建大规模数据集的流程的链接。感兴趣的读者可以找到讲义笔记,以及指向博客文章、教科书内容、开放课件和原始论文的链接。EconDL还为本文综述的许多应用提供了demo notebooks链接。该网站将持续更新,而且一些软件包明确支持随着研究进展替换新的神经网络。
本文结构如下:第一部分概述深度学习,第二部分介绍基础架构。第三部分讨论深度学习的数据要求,第四部分探讨偏差和不确定性量化,第五部分阐述可复用性和可重复性。接下来我们转向应用部分。第六部分介绍事先定义好类别且类别数量不多的分类问题,比较分类器和生成式人工智能。接着,第七部分深入探讨嵌入模型,当类别数量众多或事先未指定类别时,嵌入模型很有用。第八部分考虑回归问题。对于本文综述所涉及的应用,还有其他处理方式。第九部分着重说明为何本文强调的方法最有可能适合学术研究人员所面临的限制条件。第十部分为结论。
2.1 什么是深度学习
深度神经网络学习原始数据的表示形式,以提取对特定任务有用的信息。其利用具有多层结构的神经网络将原始数据映射为这些表示形式,从而把高维非结构化数据简化为连续向量。
为了针对给定任务有意义地表示数据,神经网络某一层中的节点(向量表示中的数字)会通过与一个非线性函数相结合,转变为下一层的节点,该非线性函数的权重是通过学习得到的参数。这些参数(数量从数百万到数十亿不等)通过最小化成本函数来估计,该函数将模型在某些任务上的预测结果(例如,预测文本中被屏蔽的词汇)与真实示例进行比较。对于不熟悉神经网络的人,我推荐Sanderson(2017)的入门视频。
数十年来,新型架构和方法的发展,使得优化具有数百万到数十亿参数的神经网络成为可能。这些进展虽然在这篇较为宽泛的综述范围之外,但在EconDL知识库中有相关讨论。特别是,在估计深度网络方面的许多开创性贡献来自卷积神经网络领域的文献,知识库的相关文章对此有所探讨。从零开始训练一个深度神经网络需要大量数据,有几个大规模数据集是该领域的常用数据:ImageNet——一个包含1400万张图像的数据集,用于图像分类及相关任务 (Deng et al., 2009);以及爬取语料库(例如,经过清理的Colossal Common Crawl (Raffel et al., 2019; Dodge et al., 2021))本质上是对互联网进行快照的大规模公共领域文本数据集。API背后的商业模型也可能获得专有训练数据的许可。从零开始训练一个深度神经模型可能需要高达数百万美元的计算成本,但幸运的是,这种情况很少有必要。
深度学习改变了许多领域,这得益于迁移学习的强大力量:在一个领域训练的深度网络可以适应许多其他领域,所需的经验训练示例(通常几百到几千个)远远少于从零开始训练一个模型所需的数量。例如,一位需要训练主题分类器的研究人员可以前往NLP的核心平台Hugging Face,下载由谷歌、Meta和微软等机构公开提供的预训练前沿语言模型。该语言模型在一个庞大的语料库上进行训练,以预测文本中随机屏蔽的词元(单词或子单词)。通过这种训练,它学会生成文本的有意义的上下文相关向量表征。研究人员可以在预训练语言模型上添加一个分类器层,并使用相对适量的标记数据,针对自己的分类任务对得到的神经网络进行微调。模型数百万参数中的大部分将保持不变,因为模型对语言的基本理解无需更新,但与手头任务最相关的参数将更新,以改进模型预测(Merchant et al., 2020)。
近年来深度学习领域一个引人注目的发现是,即使模型规模已经非常庞大(例如拥有数十亿参数),但继续扩大模型规模仍能带来收益。人类视觉和语言极为复杂,需要表现力丰富的模型来捕捉这种复杂性。例如,假设我们要完成一个简单任务:对图像中包含的十个物体(马、汽车等)中的哪一个进行分类。分类器的输入是每个像素的RGB值,即(x_{1,1}, x_{2,1}...x_{n,n}) 。假设我们使用这些输入来估计一个线性分类器。对于每个类别(j = 1...10) ,得分是(β{j,1,1}x{1,1} + β{j,1,2}x{1,2} · · · + β{j,n,n}x{n,n} + γ{j}),其中βj和γj是估计参数,分类器将根据得分最高的类别进行预测。对于某个类别,在该类别物体通常所在位置的像素,其权重参数会更大。但这种方法本质上很脆弱,因为每个类别每个像素只有一个参数,然而马的姿态、大小、在图像中的位置、颜色或体型等都可能有所不同。在βhorse的图中,可能会看到一匹马站在图像中间,有两个头朝着不同方向,这是因为线性分类器难以给实际中马可能出现位置的像素赋予高值。
而大型神经网络在预测图像中是否有马时,实际上允许有许多这样的 “过滤器”。 再比如,假设我们想分析语句(例如在调查数据中)是积极、消极还是中性情绪。经济学文献中常用的传统方法是词袋法。研究人员在查找表中查找每个单词的情绪,并将它们汇总起来以衡量句子的情绪(图2)。

这种方法的局限性显而易见。考虑以下句子:“我喜欢这篇文章”,“我不喜欢这篇文章”,“我不讨厌这篇文章”,“关于这篇文章,我没有不喜欢的地方”。即使对于这些非常简单的句子,通过累加每个单词的独立表征也无法捕捉到这些不同的情绪。相反,我们需要对单词的非线性组合进行建模,而神经网络是逼近复杂非线性函数的前沿工具。 当使用现代语言模型处理文本时(图2底部面板),一个分词器首先将输入中的每个单词映射到由查找字典分配的一个数字(如果该单词不在字典中,它会被拆分成字典中的子词)。这些数字使用学习到的参数转换为向量,然后通过神经网络,神经网络在每一层逐步将它们转换为输入词元的语义丰富的表征。视觉模型大致类似,以像素或图像块作为输入。除神经网络外,主要的替代方法是使用人工设计的特征。
换句话说,研究人员预先指定处理原始信息的规则。例如,通过编写规则来检测分隔行和列的相连空白区域,可以实现表格数字化的自动化。而对于深度学习,会向模型展示带注释的表格布局示例。深度学习革命在许多不同任务中反复证明,在处理非结构化数据时,从经验示例中学习大大优于人工设计的特征提取。EconDL知识库中讨论了部分相关证据。
深度学习在许多经济应用中可能也会优于特征工程。经济学家想要处理的信息通常既复杂又有噪声。例如,文档扫描会因老化、扫描和历史印刷技术而引入噪声;或者文本数据可能包含光学字符识别(OCR)错误或拼写错误。人类语言很复杂,有许多不同的方式来表达相同的情绪,而且单词的含义会因上下文而显著变化。噪声和复杂性给人工设计的规则带来了例外情况,这些例外情况也必须进行硬编码,同样,例外情况也存在例外。最初看似简单的任务,随着研究人员试图对这些例外情况进行硬编码,可能很快就会变得错综复杂。即使结果令人满意,人工设计的系统也很可能是针对特定情况量身定制的,无法很好地应用于具有不同类型复杂性和噪声的其他数据。
深度学习的另一个潜在优势在于,训练和实现神经网络的方法是标准且可重现的,而人工设计特征提取过程中则不可避免地存在较大的主观性。即便抛开研究人员的自主裁量权不谈,设计规则也需要大量的专业领域知识。例如,在统计机器翻译领域,数十年来众多研究人员致力于设计复杂的机器翻译统计规则。然而,少数研究人员在几个月内开发出的神经网络,其表现却超越了这些系统。随后,神经翻译技术的进一步发展催生了Transformer架构,自那以后,该架构给自然语言处理、计算机视觉、音频及其他领域带来了革命性变化。
2.2 基础深度学习架构
本节简要介绍神经网络架构。对于不熟悉这方面内容的读者,建议查阅EconDL知识库以及其中提供的资源,以获取更详细的讲解。
2.2.1 神经网络基础
神经网络由相互连接的节点层组成,这些节点被称为神经元。每个神经元都有一个值。神经元的值是通过使用激活函数和习得的权重,将前一层神经元的值进行组合计算得出的。这些多层结构将输入(例如经过分词的文本)转换为对完成预期任务有用的向量。
一个典型的激活函数是修正线性单元(RELU):f(x)=max(0,x),其中
w1,w2, . . . ,wn 和b是学习得到的权重和偏置项,i1,i2,. . ,in是来自网络前一层输入到该神经元的值。当我们将数据输入神经网络时,输入值会在每一层由激活函数进行变换,最后一层的节点就是输出。激活函数是神经网络的重要组成部分,因为它们引入了非线性,使网络能够捕捉数据中的非线性关系。EconDL知识库中《卷积神经网络》一文对激活函数有更深入的介绍。为了优化神经网络,我们使用损失函数将输出与真实标签进行比较。
这些标签所衡量的内容取决于目标,例如,对于语言模型是预测被屏蔽的词汇,对于图像模型则是预测图像类别。与任何优化问题一样,我们需要知道损失函数对每个权重的梯度,以便最小化该函数。从输出层开始,反向遍历网络直至输入层,我们对每一层计算损失函数关于该层权重的梯度。这需要使用链式法则。链式法则使我们能够通过将逐层计算得到的导数相乘,来计算损失函数关于网络中任意权重的导数。这就是所谓的反向传播。权重使用梯度下降算法进行调整。对于不熟悉反向传播的读者,推荐观看Sanderson (2017)制作精良的图示化讲解视频。希望深入理解的读者可以阅读Karpathy (2022)的高级反向传播教程。Nielsen (2015) 为之前不了解神经网络的读者提供了教科书式的讲解。Goodfellow, Bengio and Courville (2016) 则面向已熟悉神经网络并希望深入复习的读者提供了教科书式的内容,而Stevens, Antiga and Viehmann (2020)旨在帮助那些希望通过PyTorch实践来学习关键概念的读者。
在普通的前馈神经网络中,一层中的所有神经元都与下一层的所有神经元相连。在实际中,深度全连接网络很少被使用。相反,有几种类型的神经网络在深度学习文献中占据主导地位。本综述重点介绍卷积神经网络(CNN;第二部分第2节)、循环神经网络(RNN;第二部分第3节)以及Transformer(第二部分第4、5、6节)。
2.2.2 卷积神经网络(Convolutional Neural Networks)
卷积神经网络(CNNs)利用了图像中存在的空间结构,在引领深度学习革命中发挥了核心作用。尽管出现了用于图像处理的更新架构——视觉Transformer(第二部分第6节),但CNNs仍被广泛使用,经过适当优化后能达到近乎前沿的性能,并且相较于视觉Transformer,它可能更轻量,也更容易调整。本节对此进行简要介绍。对于不熟悉CNNs的读者,建议参考Sanderson (2020)以图形方式对卷积进行的简短介绍,因为通过视觉来理解以下概念特别有帮助。EconDL知识库的“卷积神经网络”页面还提供了更多资源。
视觉问题起始于具有特定高度(以像素为单位)、宽度(以像素为单位)和深度(例如,RGB图像深度为3)的图像。卷积层是CNN的核心组成部分。该层的参数由一组可学习的滤波器构成,例如3×3、5×5或7×7的权重矩阵。在计算下一层的输出时,这些滤波器仅应用于给定节点紧邻的周边节点,并且会延伸至输入的整个深度。每个滤波器在输入上进行卷积(移动)操作,在每个空间位置产生一个激活值。与全连接层相比,在不同空间位置使用相同权重极大地减少了参数数量。
此外,参数共享确保了无论特征在图像中的位置如何,都能被检测到。这赋予了CNNs一定程度的平移不变性,这是很理想的特性,因为例如,无论马在图像中的位置如何,它仍然是一匹马。小卷积滤波器固有的局部性偏向是符合逻辑的,因为对一个像素的解读,受其相邻像素的影响要大于受远处像素的影响。尽管这些滤波器具有局部性,但通过网络的深度,CNN仍然能够实现广泛的感受野。 CNNs擅长学习层次化特征:较浅的层感受野更为有限,捕捉诸如边缘等简单模式,而较深的层则捕捉日益复杂的结构。除了卷积层,CNNs还使用池化层。如果将M个不同的卷积滤波器应用于神经网络的一层,下一层的深度将为M,因为每个滤波器在每个空间位置都会产生一个激活值。池化层会减小这个深度,防止参数数量变得过大而难以处理。通常,一个CNN由卷积层和池化层交替组成。
估计具有多层的神经网络的核心挑战是梯度消失问题(Bengio, Simard and Frasconi, 1994)。反向传播计算成本函数关于网络中每个权重的梯度。这需要应用链式法则来找到损失关于每一层输出的梯度,然后是每一层输出关于其输入的梯度。对于输入的极端值,导数可能会变得非常小。反向传播将小的梯度相乘。因此,当梯度反向传播到早期层时,可能会呈指数级变小。如果初始层的梯度变得极小,学习过程将会非常缓慢,甚至完全停止。EconDL上“卷积神经网络”的文章探讨了CNN架构的演变,包括一些关键创新,这些创新使得对更深层次、更具表现力的网络进行优化成为可能,从而规避了梯度消失问题。
2.2.3 递归神经网络(Recurrent Neural Networks)
卷积神经网络(CNNs)需要固定大小的输入,因为神经网络在初始化时权重矩阵的维度是固定的(大小可变的图像需要调整大小或进行填充)。相比之下,循环神经网络(RNNs)旨在处理大小可变的输入和输出。在历史上,RNNs在自然语言处理(NLP)中发挥了重要作用(Hochreiter and Schmidhuber, 1997; Greff et al., 2016),尽管后来它们已被Transformer取代。虽然研究人员在NLP应用中通常应使用Transformer,但本文介绍RNNs是为了与Transformer进行对比。
RNNs迭代地处理输入序列,例如文本中的词元。在每个时间步,它们维持一个状态,该状态捕捉关于输入序列的历史信息。随着网络处理序列中的每个元素,这个状态会迭代更新,使网络能够 “记住” 变长输入中的先前元素。
长距离依赖关系对于人类语言至关重要。Vaswani et al. (2017)的一个著名例子来说,“The animal didn’t cross the road because it was too tired”(动物没有过马路,因为它太累了)与 “The animal didn’t cross the road because it was too wide”(动物没有过马路,因为路太宽了)。“it”指的是动物还是马路呢?这取决于“it”与输入中其他词元之间的依赖关系。最著名的RNN是双向长短期记忆网络(LSTM,Long Short-Term Memory)。双向性通过正向和反向输入序列来捕捉两个方向的依赖关系。读者可以在EconDL知识库中找到关于LSTMs更详细的介绍。
2.2.4 Transformer
Transformer(Vaswani et al., 2017) 给自然语言处理带来了革命性变化,并在几乎所有深度学习领域都取得了进展,包括视觉、音频、图和强化学习。对于不熟悉的读者,我推荐 (Alammar, 2018b)的博客文章《图解Transformer》,这篇文章被广泛认为是最容易理解的入门介绍。Rush (2018) 对原始论文的注释也是经典参考资料。最初的Transformer是一个神经翻译模型,其关键要素是注意力机制。序列中的所有词元(单词或子单词)被并行输入到模型中,模型会关注上下文中的所有其他词元,为每个词元创建上下文相关的表征。上下文相关的表征与传统的单词静态表征形成对比,在传统表征中,训练语料库中的给定单词总是具有相同的表征。
Transformer解决了RNNs的局部性偏差问题(在RNNs中,随着隐藏状态传递到每个顺序词元,信息会丢失),因为它可以关注序列中的任何词元,无论其距离远近。自注意力机制的计算量与序列长度呈二次方关系,这限制了一次可以输入到模型中的文本长度(上下文窗口)。开源模型中典型的上下文窗口长度为512个词元。对于许多问题,这已经足够(例如,可以将文本分块,或者前512个词元足以形成有意义的文档表征)。也有一些模型采用稀疏注意力机制,允许更长的上下文窗口。
输入被并行输入到Transformer中,而不是像RNN那样按顺序输入,这使得训练能够充分利用GPU的并行计算能力。这使得在更多数据上训练更大的模型在计算上变得可行,并且训练时间也可以更长,所有这些都有助于提升性能。
2.2.5 大语言模型Transformer
大多数现代自然语言处理应用都使用基于Transformer的大语言模型(LLMs)。对于不熟悉大语言模型或需要复习相关知识的读者,我强烈推荐Jay Alammar的博客文章《图解GPT - 2/3》以及《图解BERT》,这些文章以直观的图形方式介绍了基于Transformer的大语言模型架构。
基于Transformer的大语言模型主要有两种类型。生成式(解码器)模型预测序列中的下一个单词。它们通常用于文本生成。由于这类模型是通过预测下一个单词进行训练的,所以在为给定词元创建上下文相关表征时,它们只能关注先前的词元。这被称为因果注意力。相比之下,掩码(编码器)语言模型是双向的:在为序列中的单词创建上下文相关表征时,它们可以关注序列中的所有单词(掩码注意力)。这类模型通过预测被掩码的词元进行训练。当研究人员旨在创建文本表征,且需要将整篇文本输入模型时,通常会使用编码器模型。双向性对这类任务很有帮助,因为一个单词前后的上下文都有助于为其创建语义上有意义的表征。
语言模型也可以结合编码器和解码器Transformer模块,例如Raffel et al. (2019)的研究。 借助Transformer架构,同一个预训练语言模型可以作为多种任务的“主干”,这为迁移学习提供了便利。
图3说明了这一点,该图改编自原始BERT论文(Devlin et al., 2019)中的一幅图。Transformer语言模型会为其输入中的每个词元(单词或子单词)生成一个向量表征,同时还会生成一个代表整个输入文本的表征。第一幅图表明,通过在词元上添加一个分类器头,就可以对全文序列进行分类。该分类器是一个前馈神经网络,它使用学习到的权重,将Transformer最后一层向量中的节点聚合为每个类别的分数。或者,两篇文本可以通过特殊词元分隔后联合嵌入,然后在词元上添加一个分类器,以对文本之间的关系进行分类(图b)。又或者,通过在每个词元嵌入上添加分类器头,就可以对每个单独的词元进行分类(例如,标记它是否指代个人、地点等,图c)。文本跨度也可以被识别(例如,问题的答案,图d)。EconDL知识库中“Transformer语言模型”一文详细介绍了各种不同的Transformer预训练语言模型。
2.2.6 视觉和音频Transformers
Transformer已经革新了深度学习的许多其他领域,包括计算机视觉。视觉Transformer(ViTs)采用与Transformer语言模型相同的架构,并进行了一些调整以使其适用于图像。与自然语言处理领域不同,在自然语言处理中Transformer语言模型已大幅超越先前技术,而在计算机视觉领域,Transformer相较于卷积神经网络(CNNs)的优势则相对较小。经过适当优化的CNN 通常能与规模相近的ViT 一较高下。此外,目前最小的 CNN(例如Howard et al. (2019)提出的模型)比轻量级 ViT(例如Mehta and Rastegari (2021)提出的模型)还要小,并且在简单任务上也能表现出色。实际上,我建议先从轻量级CNN入手——其训练和部署会更轻松,成本也显著更低——如果轻量级模型无法满足需求,再考虑使用更大的 CNN或ViT模型,并评估其性能。EconDL 上关于视觉Transformer的文章提供了更多关于 ViT 架构的详细信息。
Transformer 处理高度多样化非结构化数据的能力,在其音频应用中得到了显著体现。通过将ViT应用于音频的频谱图图像,实现了当前最优的性能。更令人惊叹的是,在 ImageNet(由超过 1400 万张自然图像(如狗、食物等)组成的主要视觉基准数据集)上进行预训练,能够最大化性能,这有力地展示了即使跨模态的迁移学习效果。
2.2.7 优化神经网络
显然,能够优化神经网络对于在研究中使用它们至关重要。优化器(参见Kingma and Ba (2014); Goh (2017))、初始化(He et al.,2015)和归一化(Ioffe and Szegedy, 2015; Santurkar et al., 2018) 都很重要。为了估计深度神经模型,研究人员还必须选择各种超参数(例如,Li et al. (2017); Falkner, Klein and Hutter (2018))。感兴趣的读者可参考EconDL配套知识库中“训练和优化神经网络基础”一文。EconDL 上的软件包为各种超参数选择了合理的默认值,以使神经网络训练对用户更友好。尽管其中涉及各种细节,但在指导众多学生优化神经网络的过程中,我得到的主要实用经验是,当性能出乎意料地差时,最常见的原因要么是学习率选择不当,要么是输入数据格式不正确。学习率决定了训练过程中优化器在调整权重时所采取步骤的大小。如果学习率过低,模型将无法更新;如果过高,模型权重将剧烈振荡。此外,数据需要采用特定格式,并且可能会实时进行转换(例如,许多神经网络需要固定大小的输入)。神经网络从经验示例中学习,而性能意外不佳往往是因为给它们输入了格式错误的示例。
我还建议深度学习新手使用专门为此设计的云服务器来训练和部署模型。EconDL 教程使用的是谷歌 Colab。在本地安装深度学习软件包需要解决大量的依赖关系,这对于经验有限的人来说可能具有挑战性。对于在研究中大量使用深度学习的更有经验的用户,购买自己的 GPU 通常可以显著节省成本。
三、训练数据集
高质量的训练数据和评估数据是深度学习发挥效用不可或缺的部分。在监督学习中,数据被划分为有标签数据集和无标签数据集。无标签数据集包含深度学习模型将要应用的所有数据,其规模通常远大于有标签数据集。当相关标签能从数据本身自动提取时,深度学习就属于自监督学习。例如,语言模型可以通过预测从大规模文本语料库中随机屏蔽的单词来进行预训练。类似地,掩码策略可应用于图像,用于视觉模型的自监督预训练 (He et al., 2022)。自监督学习最常用于预训练,然后将预训练模型迁移到另一个领域,并应用于无标签数据(可能在目标领域的少量数据上进行额外的监督微调之后)。最后,在无监督学习中,不存在真实标签,因为其目标是发现数据中的潜在结构,并根据相似性对数据进行分组。例如,可以对嵌入向量进行聚类以发现这些关系。
监督学习方法在经济应用中很常见,因为其目标通常是使用神经网络从无标签数据中提取某些特征。经济学家也可能会继续进行自监督预训练。当他们应用的领域与模型预训练的领域差异较大时,这种情况最为常见Gururangan et al. (2020)。例如,一位分析18世纪法律文本的经济史学家,可能首先会在该数据库上继续对语言模型进行预训练(通过预测被屏蔽的词元),以便更好地理解18世纪的法律术语。
无监督学习对数据探索最为有用。在实证经济学中,通常做法是明确提出一个狭义定义的假设并进行统计检验,这往往适用于监督学习应用。然而,使用无监督方法进行系统的数据探索,可能是从新的非结构化数据中收集典型事实的有力工具。
在进行监督学习时,有标签数据会进一步划分为训练数据(用于训练模型)、验证数据(用于调整模型超参数或选择提示)以及测试数据(仅用于计算将在研究结果中报告的模型评估指标)。研究人员始终应拥有高质量、有代表性的测试集来评估模型性能。如果用于评估模型性能的数据不能代表无标签数据集,特别是当无标签数据中有相当一部分在有标签数据中没有对应支持时,模型在评估数据上的性能可能与在无标签数据上的性能相差甚远,而后者才是真正关注的对象。
在理想情况下,可以通过随机抽样创建有代表性的测试集。然而,这并不总是可行的,尤其是当研究人员想要测量的类别严重不平衡时。假设研究人员需要从海量网络语料库中提取感兴趣主题的文本,而相关主题每一万篇文本中仅出现一次。那么,通过随机抽样获取足够多正例的标注要求显然是不可行的。这种情况在社会科学中很常见,研究人员经常需要从海量语料库(如媒体或政府文件)中对相关信息进行分类,而其中只有极少部分内容与感兴趣的主题有关。
虽然关于抽取最具信息性样本进行标注的策略,在主动学习方面已产生了大量机器学习文献(EconDL在文本分类的背景下提供了详细讨论),但当类别不平衡严重时,关于选择有代表性样本用于训练、评估或消除偏差的研究却很少。判别式主动学习(吉辛和沙莱夫 - 施瓦茨,2019)选择那些能使区分有标签数据和无标签数据的难度最大化的样本进行标注,在类别相对平衡的数据中效果良好。但在类别严重不平衡的情况下,它的效果不佳,因为它无法对稀有类别进行充分抽样。其他主动学习方法试图在分类器的决策边界附近抽样,这会对稀有类别进行抽样,并能使预测准确率最大化。然而,这样得到的样本并不具有代表性。
相反,社会科学家经常依据某些关键词的出现来选择要标注的内容。然而,这样做必然无法对所有实例赋予正采样概率,从而增加了某些类型的无标签数据在有标签数据中没有对应支持的可能性。这可能会产生预测偏差,且该偏差会与下游因果估计方程中的误差项系统性相关(研究人员意在使用深度学习模型预测结果于该方程中),因为语义和遗漏变量往往会随时间和空间变化。
嵌入模型(第七部分)——这类深度神经网络创建了一个空间,其中文本或图像的向量表示之间的距离具有实际意义——提供了一种度量标准,可用于对数据进行分层抽样,以标注用于训练或评估的数据。一篇文本或一幅图像与一组关于某类别的查询(例如,“这篇文章是关于税收政策的”)越接近,它属于该类别的概率就越高,这使得该空间中的距离对分层抽样很有用。分层抽样方法还可为训练提供有价值的负样本:即预训练模型将其置于某个查询附近,但实际上与研究人员所指的该查询并无关联的样本。这是一个活跃的研究领域,经济学家有潜力在此做出重要贡献。EconDL网站会随着该领域研究的进展进行更新。
鉴于迁移学习的强大作用,训练数据不一定需要与无标签数据来自相同的分布,尽管通常来说,随着目标数据与训练数据之间领域差异的增大,预测准确性会下降。很多时候,现有的数据集或可从网络文本中提取的数据集,能够以较低成本创建比研究人员手动标注大得多的训练集。然后,通过在目标数据中规模小得多的一组手工标注数据上进一步微调,来确保在目标数据集上的高性能。
一致性标注(即两个或更多标注者对相同数据点进行标注)对于确保训练和评估数据的质量至关重要。一旦涉及现实世界中的非结构化数据,即使看似简单的任务往往也比预期的更复杂。一致性标注还能确保标注者理解了任务要求并生成高质量的标注。在具有挑战性的标注任务中,研究人员可能希望对所有标注数据进行二次标注,并手动解决标注差异。在更简单的情况下,可能仅需对较小部分数据进行一致性标注,以确保任务定义明确且标注者正确理解了指令。在机器学习论文中,通常期望研究人员报告标注者之间的一致性,以及公布标注者的指导说明,这在经济应用中同样有用。
四、偏差和不确定性量化
使用深度学习解决社会或经济问题存在诸多局限性(例如,可参考The 2024 ACM Conference on Fairness, Accountability, and Transparency的论文,网址:https://facctconference.org/ ,以及Cui and Athey (2022)的研究)。在此,我们的关注点更为狭窄:在原始数据集规模大到手动提取特征需要耗费大量时间精力的情况下,估算或探索那些人们可能达成共识的非结构化数据特征。
在将深度学习应用于需要主观判断的场景时,必须谨慎行事。例如,研究人员发现,标注者自我认定的政治倾向会影响他们在政治情感标注上的不一致性(Shen and Rose, 2021)。深度学习文献中的情感分类大多围绕笔记本电脑、餐厅和电影评论展开,在这些场景中,通常对产品有着明确的情感倾向,且可以通过评分来验证。
而在经济学家关注的许多应用场景中,如媒体数据、政治演讲、公司报告等中的情感倾向,可能更为隐晦,人们对此可能难以达成共识。如果模型所使用的标注反映的是标注者的主观偏见,而非定义明确的客观事实,又或者因为需要区分的内容过于复杂,模型没有足够的示例,那么它将做出不准确的预测,且这些预测可能存在系统性偏差。模型还可能从预训练中继承偏差,人工智能领域有大量关于偏差与公平性的文献(Mehrabi et al.,2021)。通过专注于具有明确定义的客观事实的简单任务,这些挑战可以得到缓解。
经济学家可以在不确定性量化方面做出有价值的贡献,而这在许多深度学习文献中并不常见。共形推理(Conformal inference)可以为预测任务提供不确定性量化。在收集到客观校准数据集的辅助下,共形方法在温和条件下生成具有边际覆盖保证的预测集。经典教程可参考 Shafer and Vovk (2008);近期的相关成果可查阅Chernozhukov, W¨uthrich and Zhu (2021), Cattaneo et al. (2022), and Lei and Cand`es (2020)的研究。渐近驱动的推理通常要求模型参数的估计是无偏的,这对于“黑箱”机器学习预测器来说是个问题,因为这类预测器通常需要在偏差和方差之间进行权衡,以产生均方误差较低的预测。半参数推理领域的大量文献(例如,Robins, Rotnitzky and Zhao (1994))致力于解决这些问题,最终在计量经济学领域催生了大量关于去偏机器学习的文献(例如,Chernozhukov et al. (2018); Chernozhukov, Newey and Singh (2022))。
计量经济学中的去偏机器学习文献与深度学习领域的 “预测驱动推理” 文献有诸多相似之处(例如,Angelopoulos et al. (2023); Zrnic and Cand`es (2023))。广义而言,从非结构化数据中估算结构化特征(深度学习文献的重点)和因果推断(计量经济学文献的重点)是估算缺失数据这一更普遍问题的特殊情况。在因果推断中,潜在结果是缺失的;而在许多深度学习预测应用中,低维结构化特征缺失,因为从高维非结构化数据中手动提取这些特征的成本过高。预测驱动推理文献研究如何利用针对目标总体的高质量客观事实标签辅助样本,对深度学习预测进行去偏。这些信息用于衡量估算所引入的偏差,然后进行校正,最终使研究人员能够在不牺牲从使用在更大数据集上预训练的有偏预测模型中获得的信息的前提下,进行有效的推断。深度学习模型在此被视为一个黑箱。可以证明,预测驱动推理框架等同于去偏机器学习。
五、深度学习中的可重用性和可重现性
深度学习在很大程度上建立在开放科学和开放数据的基础之上,尽管近年来,随着该技术商业潜力日益凸显,明显出现了向专有模型和数据转变的趋势。即便如此,开放资源的数量依然惊人,倘若没有模型和数据集的广泛共享,深度学习也不会取得如今的巨大进展。鉴于迁移学习和大规模预训练的核心地位,若没有开放科学,我们所熟知的这一领域便不会存在。只要数据隐私允许,经济学领域越能围绕大数据营造开放科学的文化氛围,作为一个学科,我们就越能从迁移学习的正外部性中受益。
例如,深度学习研究人员常常受到激励,尽快在GitHub上分享他们的代码,以此声明自己的贡献;或者在数据集构建完成后尽快发布,以便快速发展的学术研究能够长期使用。此外,深度学习的学术发表平台通常要求遵守商定的元数据标准以及数据和代码发布的伦理框架。虽然我并不主张经济学全面采用这些标准,但确实值得思考,是否存在一些模型和数据集发布标准,能够促进深度神经模型在经济学领域的可重复性和可复用性。
深度学习模型和数据的最大平台是Hugging Face。在那里可以找到大量的语言模型和文本数据,通过EconDL链接的演示笔记本中对其中一些示例进行了分析。Hugging Face最近收购了timm,这是一个视觉模型的核心存储库,使得Hugging Face成为许多语言和视觉任务的一站式平台。
六、分类器
在对深度学习进行了介绍之后,我现在转向应用方面。分类在经济分析中往往不可或缺。在大数据时代,研究人员可能首先需要使用分类来提取相关数据。例如,他们可能从大规模的新闻、社交媒体帖子、财报电话会议或立法记录语料库入手,需要从数百万甚至数十亿文本的完整语料库中仅提取关于利率、移民或高等教育的内容。这个规模小得多的语料库随后被用于提取将在某些下游因果估计方程中使用的度量。尽管这一步骤常常被忽视,但有偏差的分类会导致下游因果估计方程中使用的样本出现选择偏差,这可能会严重影响结论的准确性。
另外,研究人员可能会使用分类来估算结构化数据,例如文本中提到的地理位置、文本的情感倾向或主题,或者卫星图像中出现的物体类型。本节首先介绍分类器(第六部分第1节),并描述生成式人工智能在分类中的应用(第六部分第2节)。然后,介绍序列分类,即对文本序列(如句子、段落或文档)赋予类别标签(第六部分第3节)。它比较了定制训练的分类器和生成式人工智能在19种不同文本分类任务中的表现。分类也可以应用于文本中的单个词汇(第六部分第4节)。最后,分类器可用于相互比较文本(第六部分第5节)。为便于阐述,我将重点放在文本分类上。对整幅图像、图像中的像素或物体进行图像分类与文本分类类似,不过使用的是卷积神经网络(CNN)或视觉Transformer,而非语言Transformer。EconDL知识库中题为《Convolutional Neural Networks》的文章对图像分类有深入介绍。
6.1 分类器简介
在传统分类中,神经网络会为N个类别中的每一个预测一个分数,然后将输入归为得分最高的类别。对于不熟悉分类器的人,Sanderson (2017) 在对数字图像进行分类的上下文情境下,对分类进行了精彩的图示讲解。
回想一下神经网络就像乐高积木的类比。Transformer模型之所以强大,关键在于它能够将同一个预训练语言模型作为主干,应用于各种各样的分类任务。
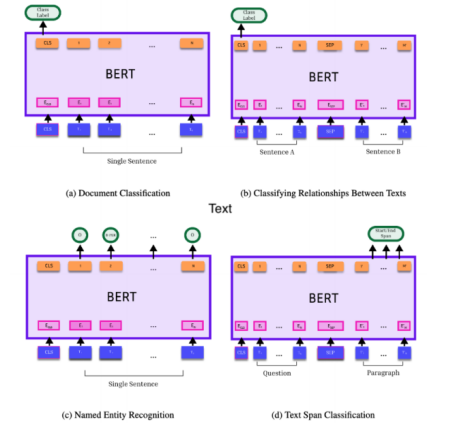
如图3所示,一个Transformer语言模型会为输入中的每个词元(单词或子单词)生成一个向量表示,同时还会生成一个表示,用于总结整个输入文本。通过在表示上添加一个分类器头(图a),就可以对文本序列进行分类。该分类器是一个前馈神经网络,它使用学习到的权重,将向量中的节点聚合为每个类别的分数。如图3的图c所示,同样可以通过在各个词元的向量表示上添加分类器头,对单个词元进行分类。另外,也可以将两篇文本联合嵌入,然后在表示上添加一个分类器,对它们之间的关系进行分类(图b)。 训练分类器是深度学习中最为直接的任务之一。开源软件包LinkTransformer可用于训练文本序列分类器,通过EconDL能获取其演示。在训练分类器时,虽然基础Transformer语言模型可以保持冻结状态,并且Transformer的不同层也可以作为分类器的输入,但通常情况下,所有参数都允许更新,分类器层会连接到Transformer的最后一层。
分类器训练是一个有监督的任务,为了在未标注数据上表现良好,模型在训练过程中必须从每个类别中看到足够数量的示例。在为分类创建标签时,各个类别的标注数据应该相对平衡(例如,在二元分类中,正样本和负样本要平衡)。 为了训练分类器,我们还需要一个合适的损失函数。分类中最常用的两种损失函数是支持向量机(SVM)损失,也称为铰链损失,以及交叉熵损失。给定一个真实标签为yi的样本和神经网络生成的类别分数向量p,SVM损失为:
该损失是对错误类别的得分求和,如果正确类别的得分没有比错误类别的得分至少高出某个阈值,就会施加惩罚。该阈值可设为1,而不会失去通用性,因为它只是对学习到的权重进行缩放。
交叉熵损失衡量的是预测得分分布与真实分布之间的差异。假设有一个用于C类多分类问题的神经网络。设y为一个样本的真实标签,用独热(one-hot )编码向量表示。对于属于类别i的样本,yi = 1,且当j≠i时,yj = 0。设z为神经网络针对该样本生成的原始数值(通常称为logits)。一个分类层会为每个类别生成一个得分。使用softmax函数得到的类别i的预测得分是:
虽然文献中经常将类别得分称为 “概率”,但从统计学意义上讲,它们并非真正的概率。它们的峰值程度取决于神经网络的正则化。真实标签与预测分布之间的交叉熵损失为:
由于y是一个独热向量,因此可简化为:
其中Ptrue class是正确类别的预测概率。 对于支持向量机损失,一旦正确类别的得分超过某个阈值,它就不再关心是否进一步提高正确类别的得分。另一方面,交叉熵损失会促使正确类别的得分趋近于1。这意味着在训练的早期阶段,准确率可能会突然提高,而损失却没有显著变化。在实际场景中,这两种损失通常会产生相当的结果。二元分类器使用F1分数进行评估,这是一个综合了召回率(真阳性数除以真阳性与假阴性数之和)和精确率(真阳性数除以真阳性与假阳性数之和)的指标。
完美的精确率和召回率会使F1分数达到1,而最差的分数是0。F1分数是精确率和召回率的调和平均数,因此往往更接近这两个指标中较小的那个。如果精确率或召回率较低,F1分数也会较低。F1分数比准确率更受青睐,因为如果类别不平衡,总是预测多数类别的话,准确率可能会很高,但这样的结果并不能真实反映模型性能。
6.2 用于分类的生成式AI
像GPT、Claude或Llama这样的大型生成式人工智能模型(在文献中通常被称为基础模型),采用解码器Transformer架构(第二部分第5节),依据给定的提示信息,以自回归的方式生成文本内容。在实际应用场景中,它们还能够借助检索增强型语言建模(retrieval-augmented language modeling,RALM)的设置方式,与外部数据库(例如互联网)建立连接(EconDL上关于检索的文章包含更多有关RALM的信息)。从根本上讲,这些模型在执行分类任务,在每个时间步长自回归地预测离散词汇表中最可能的下一个词元。默认情况下,像GPT这样的模型是随机的;它们从最可能的词元分布中预测下一个词元。
要使用生成式人工智能执行分类任务,用户需要向模型输入提示。在很多方面,像生成式语言模型输入提示并不像通过梯度下降调整分类器那么直接,因为离散提示的空间是无限的,而且关于提示的研究已经形成了大量繁杂的文献。不过,有一些明确的见解值得重点强调。关键在于,提示调整应该在验证集上进行,绝对不能在用于评估性能的测试集上进行。在测试集上调整提示可能会使提示过度拟合测试集的特性,导致测试集上的性能无法代表模型在未标注数据上的性能。关于思维链提示的文献建议将任务分解为简单步骤,使其更易于理解 (Wei et al., 2022)。这与我的经验相符,简单的提示比冗长、详细的提示效果要好得多。
如果一个问题需要冗长的指令,尽量将其分解为多个问题,在每个步骤向模型输入提示。也有关于为生成式大语言模型演示任务的文献(例如,Khattab et al. (2022))。这是否有用取决于任务的性质,我建议使用验证集来检验演示是否有帮助。Liu et al. (2023) 对提示工程进行了综述。对于像GPT这样的自回归模型,他们推荐前缀提示,例如,“我喜欢这门课。这条评论的情感倾向是什么?”这与完形填空式提示形成对比:“我喜欢这门课,它是一门[z]的课。” 本文研究了截至2024年6月GPT - 3.5和GPT - 4o在历史报纸文章主题分类上的性能。在过去一年里,我用旧模型以及GPT - 4和GPT - 4 Turbo进行过此项测试。
GPT - 4和GPT - 4o的表现相近,略优于GPT - 4 Turbo。我没有看到新版本有任何系统性的改进。具体情况可能因任务而异,因为在某些任务上,更大、更新(因此也更昂贵)的模型无疑会表现得更好。我还测试了另外两款领先的人工智能模型,来自Anthropic的Claude Haiku和Claude Opus。它们的性能明显较差(F1分数通常比GPT低10 - 40分),由于篇幅限制,这里未作报告。性能较差的原因有两个。首先,Claude会拒绝为它认为有害的文本生成输出。Claude的一个显著特点是其“符合道德准则的人工智能”框架,该框架设定了某些道德原则(例如,无害性要求回复应是平和、合乎道德的,并且避免可能在非西方文化中被视为冒犯性的内容)。一些关于过去冲突的文章(大多是对事件的客观报道)以及一系列其他主题(例如,20世纪60年代撰写的关于避孕方法引入的内容)被认为是有害的。
此外,Claude并不总是生成所需的“是/否”格式,因此无法确定文章是否符合主题。GPT则没有出现这些问题。也许通过更多的提示调整可以解决这些问题,或者未来的更新可能会改变这种情况。
无论如何,对于分类器而言,通常很容易解释它为何会出现特定错误,以及如何修正这些错误(比如为它容易混淆的实例类型增加更多训练数据),然而目前的生成式人工智能(GenAI)却更像是一个黑箱。其内部机制更为复杂,这些模型通过强化学习进行训练,以产生模型训练的商业机构认为理想的回复。对于特定的学术应用而言,这可能是个问题,也可能不是,这也凸显了使用测试集进行严格评估的重要性。
生成式人工智能用于分类任务的优点如下:其一,启动成本较低,只需极少的编程专业知识,也无需深入了解其内部运作机制;其二,它可以进行零样本学习(用户无需提供训练数据),而调整分类器则需要训练数据。我们会发现,在文本分类方面,定制训练的分类器往往更具性能优势,尽管生成式人工智能在处理最直接简单的任务时也能表现出色。这与广泛认可的观点一致,即在有足够高质量训练数据的情况下,监督学习任务通常能够达到接近人类水平的性能。
这也引出了生成式人工智能的潜在缺点。使用API背后的大型模型,无法像训练分类器那样进行精细控制。尽管像GPT这样的模型允许用户向模型展示实证示例,但在本文的实验中,这并没有带来性能上的提升。目前还不完全清楚通过提示进行示例展示是如何影响这些模型的,而通过梯度下降提供训练示例如何更新分类器则是清晰明确的。并非所有模型在接受相同数量的训练数据时都能有同等程度的学习效果(如第九部分的实证所示),像定制分类器中使用的轻量级模型往往能非常高效地进行更新。
在可解释性和可重复性方面,定制分类器也具有优势。如果某个模型被弃用,来自商业API的结果可能就无法复现了,而且正如上文所讨论的,商业生成式人工智能模型可能更像一个黑箱。使用开源基础模型,如Meta AI的Llama,可以缓解这些担忧。然而,其启动成本和硬件要求抵消了易用性方面的优势。
最后,使用诸如RoBERTa这样轻量级主干的分类器,在处理大量文本时部署成本较低,而目前商业模型的成本可能非常高昂。如果竞争加剧,且在低成本部署方面的研究取得进展,这种情况可能会有所改变。 为了确定分类器还是生成式人工智能最适合某项任务,我建议首先进行大致估算,以确保使用生成式人工智能在预算范围内。如果在预算范围内,创建测试集和验证集,调整提示并评估其性能。如果性能不理想,就需要一个训练集来调整定制分类器。如果用户事先知道保证可重复性至关重要,或者与网络文本存在较大的领域差异,又或者任务需要精细控制,那么他们可能会直接选择训练一个定制分类器。对于处理机密数据的人员来说,数据隐私要求是需要额外考虑的因素。
6.3 序列分类
经济学家可能希望在文本层面估算各种结构化信息,例如文本的主题、所含内容的类型或情感倾向。为了阐述文本序列分类,本节训练了19种不同的二元主题分类器,并将其应用于大规模历史新闻数据库(Dell et al., 2023; Silcock et al., 2024),同时与生成式人工智能进行比较。对于标注人员来说,要记住19种不同的主题定义来创建多类别标签难度较大,因此采用二元分类。二元分类器无法组合成多类别分类器,因为一个主题的负例可能是另一个主题的正例。为使生成式人工智能的提示简洁,也倾向于采用二元分类。
标注数据由高技能标注人员进行一致性标注,标注差异由人工解决。一致性标注确保了数据的高质量,并有助于形成明确的定义。例如,在犯罪分类器的案例中,标注人员对于关于水门事件的文章是否应被视为相关主题存在分歧,一个零样本模型因水门事件显示1974年犯罪报道大幅激增。虽然这可能是一个合理的定义,但我不希望犯罪报道受到政治丑闻(这类事件报道量极大)的影响而出现偏差,而分类器通过少量标签就能很快学会这一点。 一个常见问题是需要多少标签。这会有所不同。主题越是多样或需要学习更复杂的概念,可能就需要更多标签。
表2给出了本节所考察的各类主题分类任务的拆分统计数据。标注数据被随机拆分为训练数据、验证数据和测试数据。验证数据用于选择超参数、选择模型检查点(确定何时停止训练)以及调整提示词,而测试数据仅用于计算表2。表2所使用的提示词列于附录中。
这些分类器是使用LinkTransformer进行训练的,它支持使用Hugging Face上任何可用的基础语言模型。我们使用了DistilRoBERTa(8200万个参数)(Sanh et al., 2019b)和RoBERTa large(3.35亿个参数)。RoBERTa(Liu et al., 2019)是一种广泛使用的、改进版的BERT。蒸馏语言模型是较小的模型,经过训练以匹配较大模型的性能。蒸馏版本运行速度更快,但通常会有性能损失。 我们在所有分类任务中使用了一组一致的超参数,这些超参数总体上效果似乎不错(学习率为1e - 6或1e - 5,批量大小为8)。在大多数情况下,对于各种不同主题,经过微调的分类器往往优于或等同于GPT的性能,不过对于更简单的任务,GPT的性能可能非常好,特别是GPT - 4o(GPT - 4表现类似)。用于生成这些分类器的训练数据质量很高。如果标签质量较低,比如通过在线标注平台生成的标签(其质量向来不佳),那么定制训练的分类器很可能始终不如GPT。这些比较结果未来也可能会发生变化。
总体而言,生成式人工智能在一些简单主题上表现最为出色,这些主题很可能在其预训练过程中被大量涉及。与训练数据(主要是现代网络文本)的领域差异越大,其性能下降得越厉害。对于星座运势、讣告以及关于小儿麻痹症疫苗的文章——这些都是极其简单的主题——GPT的表现近乎完美(分类器也是如此)。然而,也有一些主题GPT表现不佳,比如政治主题,该主题具有挑战性,因为它范围广泛且内容多样,涵盖19世纪末和20世纪初的内容,包括地方和国家政治。一战相关内容在两个GPT模型中的F1分数都在70分出头,远低于越战相关内容,这可能是因为越战在训练语料库中的占比更高。此外,自一战以来语言变化较大,导致领域差异更为明显。然而,通过少量标签,RoBERTa分类器能够适应这种领域差异。
目前,对于大多数社会科学研究人员而言,使用GPT处理大型语料库的成本可能远超预算,不过我在此不列举具体数字,因为价格会波动,且可能会因竞争和技术进步而发生显著变化。相比之下,用此处所示数量的标签训练一个RoBERTa分类器成本非常低(在撰写本文时,使用每月9.99美元的谷歌Colab计划或一块中端英伟达GPU显卡,几分钟内即可完成)。我也有学生凭借耐心在笔记本电脑上训练类似模型,不过通过云计算或专用硬件获取一块性能不错的GPU会更好。部署这些分类器,即使是对数百万篇文章进行处理,成本也很低,使用云CPU或一块中端GPU显卡,几小时内就能完成。
可以通过在GPT预测的标签上训练分类器,来规避使用生成式人工智能的高昂成本。表2显示,当GPT生成的标签质量非常高时,这种方法可行。然而,在GPT表现欠佳的情况下,在有噪声的数据上进行训练会放大错误。
图4取自Silcock et al. (2024)的研究,该图采用适用于不同时期的二元分类器,并将其应用于1878年至1977年间发布的270万篇独特新闻专线文章数据集。各种趋势显而易见,比如20世纪20年代与禁酒令相关的犯罪报道激增,或者20世纪60年代民权运动和抗议活动报道的大幅增加。
值得一提的是,与基于关键词(复杂程度各异)的稀疏方法相比,神经网络方法在文本分类方面表现如何。例如,一种常见的稀疏方法是TF - IDF:词频(TF)是文档d中词t的原始计数。逆文档频率(IDF)衡量一个词在整个语料库中的重要性。如果一个词在许多文档中都出现,那么它就不是特定文档的良好标识符。对于语料库D,词t的IDF由公式 给出。一个词的TF - IDF分数就是其TF分数和IDF分数的乘积。TF - IDF分数越高,相对于整个语料库的上下文,该词对特定文档就越重要。
给出。一个词的TF - IDF分数就是其TF分数和IDF分数的乘积。TF - IDF分数越高,相对于整个语料库的上下文,该词对特定文档就越重要。
为了使用TF - IDF根据文档与查询的相似度对语料库中的文档进行排序,每个文档和查询都表示为一个稀疏的高维向量,每个维度对应语料库中的一个唯一词。向量中每个词的权重是其TF - IDF分数。任意两个向量之间的夹角反映了文本之间的相似性。可以将此方法视为类似于一种关键词搜索,对在整个语料库中频繁出现的词进行权重下调。我们将像TF - IDF这样的方法称为稀疏方法,因为语料库中的每个词在向量空间中形成一个维度。词汇表中的大多数词不会出现在单个文档中,导致词向量中的大多数条目为零。
当精确的词项重叠能提供大量信息时,稀疏方法颇为有用。然而,由于语言的复杂性,单纯依赖词项重叠往往存在重大缺陷。表达同一事物的方式多种多样,而且同一个词项可能具有不同含义。此外,噪声(如拼写错误、光学字符识别错误、缩写等)无处不在。语义会随着时间和空间的变化而改变,许多遗漏变量也是如此。这可能导致在使用关键词预测的因果估计方程中,预测误差与误差项之间产生相关性。而且,虽然词项可以通过挖掘获得,但更多时候只是人为选定,这就产生了研究者自由度的问题。 神经网络方法通过使用大语言模型将文本映射为密集向量表示来解决这些不足,例如,一个由非零项组成的768维向量。该向量的维度取决于基础语言模型。预训练语言模型具备语言理解能力,因此密集方法能够考虑上下文和语义的相似性。这使得它们能够对同义词和语义相似的短语进行泛化处理,并且对其他噪声更具鲁棒性。Dell et al. (2023) 将上述用于政治主题的神经分类器与挖掘出的关键词以及ChatGPT建议的关键词进行比较。结果表明,神经网络方法能带来显著更准确的预测。
6.4 令牌分类
研究人员可能需要提取文本中单个词项的信息,而非对文本整体进行处理。这个问题与序列分类类似,不同之处在于,分类器头被添加到Transformer最后一层中每个词元的表征上,而不仅仅是添加到表征上(图3,c面板)。
本节以词元分类中的命名实体识别(named entity recognition,NER)为例,该任务旨在检测文本中的命名实体。只要研究人员能给出清晰、一致的定义,并拥有足够的训练标签,就可以按照自己的需求定义这些实体。例如,研究人员可能想识别社交媒体帖子中提到的地点。或者,从讣告数据中提取家庭关系的研究人员,可能希望标记个人与逝者的关系(子女、父母、兄弟姐妹、主祭人等)。又或者,想要将传记文本转换为结构化数据集的研究人员,可能会标记出生地、母亲、父亲、大学、配偶和雇主等信息。
命名实体识别是一项经典任务,相关文献众多,Hugging Face上有许多开源的预训练模型和数据集。在这些文献中,实体类别通常包括人物、地点和组织。CoNLL是一个著名的基准数据集(Sang and De Meulder, 2003),用于在Hugging Face上预训练各种模型。WNUT是另一个基准数据集(Nguyen et al., 2020),主要关注嘈杂的用户生成文本(推文)。如果研究人员关注的实体类型与这些基准数据集所强调的不同,就需要自行创建标签。
命名实体识别通常使用BIO标记法——实体的第一个词元标记为B(表示开始),后续词元标记为I(表示内部),不感兴趣的词元标记为O。如果感兴趣的实体类型是人物(P)和地点(L),那么标签就会是B - P、B - L、I - P、I - L和O。

图5展示了将命名实体识别应用于历史新闻专线文章的结果,绘制了超过2700万个实体在四类中的占比:人物、地点、组织和其他。结果符合预期,例如,在二战期间,地点和其他命名实体(如飞机名称)的占比出现峰值。研究人员也可以让生成式人工智能识别文本中的实体,并将输出转换为表格。与序列分类一样,研究人员可以通过构建具有代表性的验证集和测试集,来检验模型性能是否满足自身需求。
6.5 文本之间的关系
在多种情况下,我们希望衡量两篇文本是否以某种预先设定的方式相关联。例如,我们可以将主题分类表述为这样一项任务:判断一个陈述是否由一篇文章推导得出,比如 “这篇文章是关于货币政策的” 这一陈述是否能从文章文本中推导出来?又或者,两篇文本是否是彼此带有噪声干扰的重复内容?它们在某个政治问题上的立场是否一致?一篇是否承接另一篇?

图6展示了两种比较文本的方法。上图展示的是交叉编码器:两篇文本连接在一起,中间用标记隔开。这些文本一同被输入到Transformer中,然后通过一个分类器头对它们的关系进行分类。这种方法允许两篇文本中所有词元之间进行充分的交叉注意力计算。下图展示的是双编码器方法:文本分别进行嵌入,然后我们使用诸如余弦相似度等距离度量来计算它们之间的相似度。双编码器非常有用,我们将在第七部分详细阐述。
交叉编码器允许词元之间进行充分的交叉注意力计算。由于它们是联合嵌入的,在创建表征时,被比较文本中的词元可以灵活地相互关注。相比之下,双编码器为每篇文本分别计算单一表征,然后再比较这些表征。因此,交叉编码器往往具有更高的准确性。然而,它们也存在显著缺点。最关键的是,如果我们需要将M篇文本与另外N篇文本进行比较,这就需要对M×N篇文本进行嵌入。这种二次方的计算成本很快就变得不可行,因为每篇文本都要通过一个含有数亿参数的神经网络。相比之下,对于双编码器而言,要将M篇文本与另外N篇文本进行比较,只需要M + N次嵌入,这使得这种方法具有高度的可扩展性。为了兼顾两者的优势,相关文献中常常先使用双编码器找出与查询文本最相似的n篇文本(n取值较小),然后再用交叉编码器对这些匹配结果进行重新排序。
七、嵌入模型
为了估计分类器,必须事先指定类别,因为类别数量决定了神经网络中的参数数量,而且类别必须在训练过程中出现过。使用生成式人工智能进行分类任务时,也需要明确指定感兴趣的类别。然而,在很多情况下,类别事先并不明确,或者研究人员希望在后续添加新类别时无需重新训练模型。此外,如果类别数量众多,则损失函数在计算所有类别上的softmax时其运算可能变得难以处理。
对于这些常见场景,可以直接使用来自Transformer或CNN最后一层的嵌入向量,而不是估计一个将嵌入向量映射到类别分数的额外神经网络层(分类器),这样就能解决问题。这避免了对类别的预先设定。此外,向量相似度计算经过了高度优化,能够处理类别数量达数百万甚至数十亿规模的问题。
本节介绍了一系列可以用嵌入模型解决的应用。记录链接(例如,跨数据集的个人、公司、地点或产品的链接)是一项常见任务,可以构建为一个具有众多类别的分类问题(例如,每个个人、公司等都作为一个类别)。它特别适合采用嵌入方法(第七部分第2节)。这些方法能够处理诸如多语言链接或具有多个嘈杂文本描述的链接等场景,而这些场景用传统的字符串匹配方法很难处理。类似的方法可用于将非结构化文本(如社交媒体或印刷媒体、公司文件、传记、政府文件)中对个人、公司等的提及与维基百科等外部知识库建立链接(第七部分第3节)。追踪文本或图像在媒体中的传播是另一个可能令人感兴趣的应用,在这种情况下,类别通常事先并不明确(第七部分第4节)。在某些情况下,目的可能是探索性的,即揭示大规模新文本或图像数据集中的典型事实,而嵌入方法非常适合此类描述性分析。最后,光学字符识别(OCR)可以构建为图像分类任务,研究人员可能希望在后续添加字符或单词而无需重新训练模型,这也表明适合采用嵌入方法(第七部分第5节)。
直接使用嵌入向量要求向量表示之间的距离具有实际意义。预训练的Transformer语言模型的几何属性并不太适合这项任务。例如,低频词的表示在超球面上被向外推。低频词的稀疏性违反了凸性,并且嵌入向量之间的距离与词汇相似性相关。这导致语义相似文本的嵌入向量之间对齐不佳,并且当将单个词项表示汇总以创建文本序列的平均表示时,性能会很差 (Ethayarajh, 2019; Reimers and Gurevych, 2019)。从数学角度来看,问题在于预训练的Transformer模型创建的嵌入空间不是各向同性的,这意味着表示不是均匀分布的。当嵌入向量是各向同性时,没有特定方向会受到偏爱。这种均匀分布确保向量之间的距离能够准确反映它们之间的关系,使得该空间对于依赖这些距离的任务更加有效。对比学习是一种广泛使用的方法,它可以改善各向同性,在介绍嵌入模型应用之前将对其进行讨论。
7.1 对比学习
对比学习旨在为语义相似的输入学习相似的表征,为语义不同的输入学习不同的表征,其中相似性的定义由经验训练示例给出。对比损失函数促使模型缩小正例(例如,相似的文本或图像)在嵌入空间中的距离,并增大负例(例如,不相似的文本或图像)之间的距离。对比训练可减少各向异性,显著改善文本序列的池化表征,并提升语义相似文本的表征之间的对齐度。
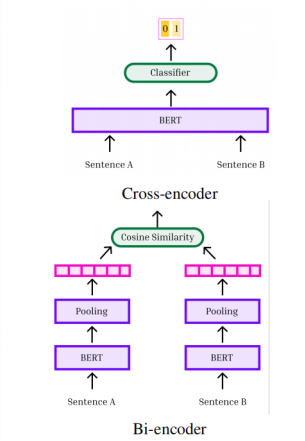
对比学习采用图6所示的双编码器设置。双编码器通过将每个实例输入Transformer并对词元级嵌入进行池化(平均),为每个实例形成单一表征。之所以采用池化方式处理表征,而非使用标记,是因为研究表明池化方式性能更佳 (Reimers and Gurevych, 2019)。
表征之间可以通过计算向量相似度进行比较。在实践中,由于表征位于单位超球面上,常使用余弦相似度。根据训练数据的不同,损失函数有不同的选择。对比损失(Chopra, Hadsell and LeCun, 2005)使用正例和负例对,促使正例具有相同的表征,负例之间的距离大于某个阈值。余弦损失使用实例间差异的连续度量。对于三元组损失(Hermans, Beyer and Leibe, 2017),训练数据由三元组组成:一个锚点、该锚点的一个正例和一个负例。它促使正例的嵌入与锚点的相似度高于负例。使用InfoNCE损失(Oord, Li and Vinyals, 2018)时,将多个负例与单个正例进行比较。监督对比损失(Khosla et al., 2020) 对InfoNCE进行了推广,允许存在多个正例和负例。EconDL知识库中“对比学习”一文提供了更多细节,包括数学公式。
神经网络创建的度量空间应根据用于训练网络的对比损失函数来解释。例如,使用对比损失时,同一类别的实例会被促使具有相似的表征,而不同的实例则被促使其距离大于某个阈值。因此,局部距离是有意义的,但全局距离并非如此,因为超过阈值后,差异再大也不会影响损失。在对成对数据进行对比训练时,用于嵌入每个实例的两个编码器的权重可以相同(对称编码器),也可以不同(非对称编码器,如Karpukhin et al. (2020)所述)。对称编码器提供了一个更简洁的模型,因此需要更少的数据和计算资源来进行训练。
在实践中,即使对两种不同类型的实例进行编码(例如,搜索查询和包含答案的文档),它们也能表现良好。 为对比学习选择有信息含量的负例很重要。如果负例太“容易”——例如,在用于初始化训练的预训练模型的嵌入空间中它们差异很大——则模型学到的东西很少。在某些情况下,研究人员可以利用先验知识为训练选择“难”负例。在其他情况下,可以通过使用预训练模型选择嵌入相似的负例来挖掘负例。如果研究人员事先知道哪些实例是负例,这种方法会很有效,例如在对合成生成的数据进行训练时就是这种情况。
也有现成可用的嵌入模型。句子-BERT(Sentence - BERT, (Reimers and Gurevych, 2019)是一款出色且获得广泛支持的开源模型。(在相关文献中,“句子”一词用于指代任何文本序列,可能是一个短语、句子或整篇文档)此外,OpenAI 出售价格相当亲民的句子嵌入服务。
虽然开发能够在任何任务上实现出色零样本学习的通用嵌入模型备受关注,但一般来说,较大的模型在零样本学习上平均表现优于较小的模型,但经过微调的轻量级嵌入模型相较于零样本嵌入模型具有重要优势。直观地讲,嵌入为每个文本(或图像)提供单一表征。现成的表征会捕捉关于文本或图像的大量不同信息。然而,研究人员通常只对其中某些狭义定义的方面感兴趣。微调将突出相关维度,在嵌入空间中使不同类别之间区分更明显。

来看下面这个实证例子。我采用了关于美国立法的比较议程数据集,该数据集为国会议案分配主题标签,然后使用三种不同模型计算立法描述嵌入之间的成对相似度:现成的轻量级S - BERT 嵌入(图7a)、OpenAI 的大型嵌入(图b),以及通过在这些数据的训练分割中,利用成对的正例和(随机)负例议案对 S - BERT 进行微调后生成的嵌入(图c)。蓝色分布表示同一主题内的余弦相似度,红色线表示不同主题间的余弦相似度。图 a 和图b中,蓝色和红色分布有相当大的重叠,表明在确定语言模型如何将文本映射到嵌入空间时,主题的重要性较低。分布中的大部分重叠来自边缘情况,即文章介于不同主题之间或涵盖多个主题。图d使用在美国议案上微调的模型来比较英国议会法案在主题内和跨主题的嵌入。虽然存在一定的领域偏移,但仍然有明显的区分,这表明微调后的模型能够推广到类似问题。
7.2 结构化数据的记录链接
记录链接在许多经济分析中至关重要。研究人员可能需要跨数据集链接个人、地点、公司、组织、产品描述或学术论文。传统上,记录链接使用诸如莱文斯坦编辑距离( Levenshtein edit distance,计算将一个字符串转换为另一个字符串所需的字符插入、删除和替换的数量)或杰卡德相似度(Jaccard similarity计算字符串子串 n-gram语法表示之间的相似性)等度量方法。最近,专注于电子商务数据集匹配的机器学习文献表明,基于Transformer的大语言模型在改进记录链接方面很有前景。然而,在撰写本文时,这些方法尚未在社会科学领域广泛应用,基于规则的方法仍然占据绝对主导地位(例如,参见Binette and Steorts (2022); Abramitzky et al. (2021); Bailey et al. (2020)的综述)。
为了让这些方法更易于使用,Arora and Dell (2024) 设计了LinkTransformer,这是一个面向社会科学家、使用Transformer模型进行记录链接的软件包。该研究表明,Transformer在各种任务和语言上的表现往往远超传统字符串匹配方法。其应用包括链接1940年的墨西哥关税表,使用多个含噪声字段链接1950年日本公司层面的记录,以及跨六种语言链接现代公司和产品。多语言模型无需翻译即可跨语言链接产品。
这项工作的灵感来源于深度学习时代之前我不得不放弃的多个项目,因为稀疏方法表现不佳,而手动链接又不可行。与任何预测任务一样,研究人员有责任使用测试集评估模型性能是否可接受。

LinkTransformer的模型架构如图8所示。需要匹配的文本使用Transformer语言模型进行编码。对于每个查询,LinkTransformer通过嵌入之间的余弦相似度,在语料库中找到最近邻。这一过程非常快速,因为它使用了高度优化的FAISS(Facebook人工智能相似性搜索)后端(Johnson, Douze and J´egou, 2019)。LinkTransformer返回一个排名以及余弦相似度分数,可用于一对一、一对多或多对多合并,包括不匹配的情况(当与最近记录的相似度低于某个阈值时)。
就像编辑距离等传统稀疏方法返回记录之间的距离一样,LinkTransformer计算的距离度量借助了预训练语言模型中蕴含的所有语义知识,以及通过对比训练获得的任何额外知识。例如,“ABC Corporation”、“ABC Co.” 和 “ABCC” 在语义上非常相似,因此在嵌入空间中距离较近,因为 “Co.” 和 “C” 都代表 “Corporation”,但这些字符串的莱文斯坦编辑距离却很大。考虑到缩写的普遍性、描述同一产品或公司名称的不同方式、OCR错误和拼写错误,这样的例子在记录链接任务中很常见。嵌入相似度的使用方式与研究人员使用字符串距离度量的方式类似。
LinkTransformer无缝支持多字段链接,通过使用软件包自动选择的标记连接字段,以使其与基础语言模型的分词器兼容,从而对字段进行序列化。该研究给出了一个例子,使用公司名称、地点、产品、股东和银行等信息,跨不同的大规模、含噪声数据库链接20世纪50年代的日本公司。这种链接问题使用字符串匹配方法会非常复杂,因为字段存在噪声(例如,不同数据集对产品的描述方式不同,列出的经理和股东子集也不同等)。而大语言模型可以轻松应对这些挑战,因为它能够捕捉语义相似性。
LinkTransformer允许用户使用Sentence Transformer 模型、OpenAI嵌入、针对目标任务微调的模型,或者Hugging Face上可用的任何Transformer语言模型。从20个不同的链接任务中得出的总体情况是,在适量标签上进行定制训练的模型往往表现最佳,其次是OpenAI的现成嵌入,然后是现成的Sentence Transformer 模型(尽管不同任务之间存在一些差异)。这些结果与上文关于现成嵌入模型与定制嵌入模型的讨论是一致的。
LinkTransformer还提供了应用程序编程接口(APIs),以便将Transformer大语言模型用于其他数据处理任务,例如分类、聚合和去重,如EconDL上链接的教程笔记本中所述。用户还可以找到“训练自己的LinkTransformer模型”教程,以备需要定制时使用。
对比训练需要正例对和负例对(在这种情况下,即已链接的记录和不同的记录)。用户可以只提供正例,此时LinkTransformer会随机选择负例;如果有难负例可用,用户也可以同时提供正例和负例。为了提高可复用性、可重复性和可扩展性,只需一行代码即可将模型分享到Hugging Face中心。 当任务是链接扫描文档时(经济史研究中常遇到这种情况),计算机视觉也可能会有所帮助。在Arora et al. (2023)开发的仅基于视觉的记录链接模型中,记录链接无需光学字符识别(OCR),仅使用要链接的公司名称的图像裁剪部分即可。具体而言其在一个具有挑战性的场景中对其进行了探索,即链接日本历史出版物中的公司,其中一个出版物是横向书写,另一个是纵向书写。一般来说,仅基于视觉的链接能达到相当高的准确率。但是,Vision Model无法解决某些匹配项,因为公司可能以不同方式书写其名称。
嵌入模型可以结合视觉和语言Transformer,利用对语义和视觉相似性的理解。Arora et al. (2023)表明,多模态模型能够极其准确地链接经过OCR处理的日本公司层面关于客户和供应商的记录,而不太准确的字符串距离度量会产生不同的供应链网络,这可能会导致有偏差的下游经济分析。
当嵌入空间对齐时,结合文本和图像嵌入最为直接。换句话说,同一事物的图像和文本表示需要具有相似的嵌入,例如,当图像和文本编码器分别将鳄梨的图片和“鳄梨”这个文本映射到向量空间时,它们具有相似的嵌入。Arora et al. (2023)从日语版的CLIP(对比语言 - 图像预训练,Contrastive Language - Image Pre - training的缩写)开始,CLIP是OpenAI的一个模型,它使用从网络上抓取的4亿个图像 - 字幕对进行对比训练,以对齐文本和图像编码器(Radford et al., 2021)。Arora et al. (2023)对带有合成噪声的文档裁剪及其相应的OCR处理后的文本对进行了进一步预训练。然后,使用聚合的文本 - 图像表示来链接公司。
当存在OCR错误时,还有其他方法可以将视觉相似性纳入链接过程中。近似字符串匹配方法计算将一个字符串转换为另一个字符串所需的编辑次数(插入、删除和替换)(Levenshtein et al., 1966)。在实践中,并非所有的字符串替换都具有相同的可能性,构建不同成本列表的努力至少可以追溯到1918年,当时Russell and Odell 为Soundex申请了专利(Russell, 1918; Archives and Administration, 2023),这是一个语音标准化工具包,考虑到人口普查员经常根据发音拼错名字这一事实。此类方法在其适用的场景中可以显著提高编辑距离链接的准确性,但由于使用手工制作的特征,将其扩展到新场景需要大量人力。这使得依赖链接数据的研究(许多经济问题的研究都需要链接数据)偏向于资源更丰富的场景,而这些场景并不能代表人类社会的多样性。
Yang et al. (2023) 开发了一种可扩展的自监督方法,用于确定在由OCR创建的数据库中字符替换的相对成本。OCR经常会混淆具有相似视觉外观的同形字符(例如,“0”和“O”)。Yang et al. (2023) 对数字字体进行增强,以对比学习一个度量空间,在这个空间中,一个字符的不同增强形式(例如,用不同字体渲染的相同字符)具有相似的向量表示。得到的空间可以与参考字体一起使用,来衡量不同字符之间的视觉相似性。图9展示了字符及其在同形字符空间中最近邻的示例。

在莱文斯坦编辑距离框架(Levenshtein et al., 1966)中,将同形字符空间中字符间的余弦距离作为替换成本,能显著提升公司和地名的链接效果。该研究聚焦于中日韩(CJK)文字,因为此类文字字符数量极多,手工计算同形字符完全不可行,但研究表明,通过为古代汉字及所有统一码(Unicode)字符计算同形字符,此方法具有可扩展性。更广泛的启示是,即便倾向于使用传统方法(如字符串距离法),深度学习也可能提供一种低成本方式,将这些方法扩展应用于新场景。
7.3 链接非结构化数据
在自然语言处理领域,也有大量文献关注如何将非结构化文本(如新闻、社交媒体等)中提及的实体进行关联,这一任务被称为实体消歧。将原始文本中提及的实体(通过命名实体识别(NER)标记,见第六部分第4节)与维基百科或其他知识库相关联很有意义,因为这些知识库包含诸如结构化传记数据等信息。个人是否在外部知识库中本身可能也值得研究。研究人员可能还希望在一个语料库的不同文档中对提及的实体进行共指消解(例如,找出历史新闻中对约翰·F·肯尼迪总统的每一处提及)。这被称为共指消解。
尽管数字化程度不断提高,但历史文档通常缺乏文本中提及个人的跨文档标识符,也缺乏来自维基百科等外部知识库的标识符,而拥有这些标识符会让经济学家从这些资料中提取结构化数据变得容易得多。
Arora et al. (2024) 开发了一种双编码器嵌入模型,用于文本内实体的共指消解并将其与维基百科进行消歧。该模型在来自维基百科的超过1.9亿个实体对上进行对比训练。正例对来自维基百科中包含指向同一页面超链接的上下文(段落)(用于共指消解),或者来自一个上下文及其所链接的相关实体的第一段(用于消歧)。难负例则从维基百科的消歧页面大规模挖掘而来,这些页面列出了名称或别名容易混淆的实体。例如,消歧义页面 “John Kennedy” 包括总统John F. Kennedy、John Kennedy(路易斯安那州政治家)、John F. Kennedy Jr和其他各种John Kenned。难负例采样提及John F. Kennedy的上下文(例如,带有指向John F. Kennedy页面的超链接),并将它们与提及“John Kennedy”消歧页面中其他实体的上下文配对。通过从维基数据挖掘家庭成员,来自家庭的难负例(例如,小亨利·福特和老亨利·福特)被过度采样。还需要纳入随机负例,否则模型会丧失最初区分简单情况的能力,这一现象在深度学习文献中被称为灾难性遗忘。
这说明了如何挖掘现有知识,为对比训练创建有信息价值的负例。更广泛地说,维基百科是训练数据的有用来源(例如,用于训练LinkTransformer模型的公司别名也取自维基数据)。 通过使用消歧模型嵌入提及实体的上下文,并在嵌入空间中检索其在维基百科中最近的邻居,从而对提及的实体进行消歧。如果它们与最近的维基百科嵌入的余弦相似度低于某个阈值,就会被标记为不在知识库中。

图10显示,1878年至1977年这100年的新闻专线报道中提及的实体,与维基百科的Qrank(根据维基宇宙中的总页面浏览量对维基数据实体进行排名)密切相关。Silcock et al. (2024)发现,在这100年中提及次数最多的实体是德怀特·艾森豪威尔,略多于阿道夫·希特勒、理查德·尼克松和哈里·杜鲁门,并且新闻专线文章中经消歧的实体中只有4.7% 是女性。
7.4 类别未知时的分类
研究人员想要从非结构化数据中估算的类别,可能事先并不明确。当目的是描述一个全新的非结构化语料库中的典型事实时,这种情况尤为常见,但在更广泛的情形中也可能出现。本节列举几个来自媒体经济学的例子:检测重复出现的文章文本和图像、对历史上重大新闻事件进行分类,以及检索与现代新闻语义相似的历史新闻。
内容复用是媒体的一个基本特征,无论是传统媒体,还是在社交媒体分享时代都是如此。媒体历史学家Julia Guarneri写道:“到20世纪10年代和20年代,美国人在当地报纸上读到的大多数文章,要么是在全国新闻市场上购买的,要么是出售的…… 这构建了一种被广泛理解的美国‘生活方式’,并在整个20世纪成为美国国内政治和国际关系的试金石。”假设我们希望能够识别通过新闻专线发布的每一篇独特文章和图像,衡量其被转载的广泛程度,并观察哪些报纸进行了转载。这个问题比看起来更具挑战性。文本常常被大幅删减,还可能包含大量光学字符识别(OCR)错误。图像经常被裁剪,质量可能极低。Silcock et al. (2023) 表明,对于检测存在噪声干扰的重复文本,深度神经方法显著优于非神经方法,该方法可应用于历史新闻专线、现代新闻以及专利数据库。
训练和评估数据是通过将数千份数字化地方报纸上的文章,按来自同一新闻专线来源进行分组,人工精心整理而成。来自同一新闻专线来源的文章为正例。具有n-gram语法重叠但来自不同来源的文章(通常是来自不同新闻专线服务的相似文章或文章更新版本)构成难负例。训练中也会使用随机负例。
对双编码器嵌入模型进行对比训练,使得来自同一新闻专线文章来源的文章(无论是否存在噪声和删减)具有相似的向量表示,而来自不同来源的文章(即使是关于同一基本事件)具有不同的表示。然后,这些表示可以通过高效的单链聚类进行分组,以量化哪些文章来自相同的基础新闻专线或联合供稿文章来源,哪些来自不同来源。社区检测用于打破单链聚类可能存在的虚假链接。与记录链接一样,Sentence-BERT库是一个重要资源。该模型使用SBERT MPNet双编码器进行初始化,这是一个轻量级、高性能的语义相似性模型。神经方法比传统的n-gram语法和hash方法(依赖词项重叠来检测噪声重复的稀疏方法)有显著优势。如第六部分第5节所述,添加重新排序步骤会带来一定提升,该步骤将交叉编码器应用于双编码器距离在阈值内的文章。
嵌入方法的一个优势在于其可扩展性。对密集向量表示进行聚类需要高度优化的相似性搜索,因为传统聚类库的扩展性不佳。Facebook AI相似性搜索(FAISS,Johnson,Douze and J'egou,2019)是一个用于计算向量相似性的开源库,它能够在大约3小时内,在单个GPU卡上对1000万个文章表示进行1014次精确相似性比较(这是聚类所需的操作)。
通过使用近似向量搜索(适当调整超参数),可以在对准确性影响较小的情况下显著加快速度。Silcock et al. (2024)发布了1878年至1977年(截止日期因版权法变更而定)的270万篇独特新闻专线文章。其中包括主题标签、命名实体标签、人物与维基百科的消歧信息,以及文章刊登所在的县。 检测图像的噪声重复与检测重复文本类似。无需训练语言模型,而是可以对视觉模型进行对比训练,将同一图像的重复版本映射到相似的向量表示,将不同图像映射到不同的表示。在实践中,轻量级卷积神经网络(CNN)效果良好,使用大得多的视觉Transformer(ViT)提升并不明显。训练数据主要由合成增强图像组成,这些图像模拟了实际图像中存在的噪声。当能够模拟逼真的合成数据时,可以节省大量标注成本,尽管从目标数据中添加少量标记示例仍可能提升性能。
嵌入模型非常适合大规模评估非结构化数据中的典型事实。深度学习使得在经济研究中使用各种新颖的非结构化数据集成为可能。虽然我们通常专注于使用因果估计来检验精确定义的假设,但理解典型事实是提出这些假设的重要第一步。
以Dell et al. (2023)的一项应用为例,他们构建了一个历史报纸数据集,其中包含超过4.3亿篇美国历史报纸文章。这项研究的目的是在事先不知道每年重大新闻事件具体内容的情况下,确定每年的重大新闻事件。该研究在AllSides的数据上进行对比训练,AllSides是一个现代新闻网站,它将来自不同来源的新闻文章归为不同事件(通常对同一事件有不同视角)。归为同一事件的文章构成训练的正例对,模型通过这些经验示例学习 “同一事件” 的构成要素。训练好的模型用于嵌入文章,然后通过聚类形成新闻事件。

表3报告了每年最大的聚类。从中出现了一些有趣的典型事实,特别是对劳工运动的广泛报道。如果研究人员想要创建一个衡量劳工运动的指标,用于因果估计方程,他们可能会使用精心制作的标签训练一个分类器,以预测哪些文章是关于劳工运动的。相比之下,这项研究首先解释了为什么劳工运动值得研究。
Franklin et al.(2024)使用该模型进行更多的数据探索,首先屏蔽所有命名实体(人物、组织、地点和其他各类专有名词),然后在嵌入空间中查询与现代新闻文章查询最相似的历史新闻文章。由此产生的News D´ej`a Vu开源软件包和网站为探索人们对过去和现在认知的相似之处提供了一种新颖的工具。
7.5 光学字符识别
光学字符识别(OCR)对经济学家,尤其是经济史学家来说是一项重要任务。文档在字符集、语言、字体或手写形式、印刷技术以及扫描和老化产生的痕迹等方面差异极大。现成的OCR技术主要是为英语等资源丰富的语言中的小规模商业应用开发的,正如第九部分所详述,其采用的架构并不适合将OCR扩展到资源较少的语言和场景。一旦脱离英语及其他几种资源丰富的语言,OCR的识别质量可能会迅速下降。例如,对于20世纪50年代的日本印刷文档,现有的性能最佳的OCR识别错误率超过一半。糟糕的识别表现十分普遍,这催生了大量关于OCR后错误纠正的文献。
即使在资源最为丰富的场景中,现成的解决方案仍可能失效,尤其是在对准确性要求极高的情况下。在转录定量数据时更是如此。散文中的OCR错误在后期处理中通常很容易纠正,或者无关紧要。然而对于数字,类似的错误(例如,在数字开头误识别出一个“1”)可能会严重影响下游的统计分析。此外,需要数字化的文档集规模可能极为庞大。例如,美国国家档案馆保存着约132.8亿页文本记录。要将大数据应用于经济史研究,就需要一种既准确又易于低成本部署的OCR技术。
如果经济学家、历史学家及其他人员完全依赖现成的商业技术,最终我们只会关注那些与高资源商业应用极为相似的经济应用场景(例如,英文收据)。在与学生合作的多年中,我确实看到了这种情况:他们更有可能放弃针对资源较少语言的项目,因为任何现有现成解决方案的OCR识别质量都很差。这使得经济知识偏向于那些更像高资源商业应用的场景,而这些场景并不能代表人类社会的多样性。 为应对这些挑战,(Carlson, Bryan and Dell, 2024; Hegghammer, 2021)开发了一种新颖的开源OCR架构EffOCR(高效OCR)。EffOCR专为寻求样本高效、可定制且可扩展的多样化文档OCR解决方案的研究人员和档案馆而设计。
基于深度学习的目标检测方法(第八部分)被用于定位文档图像中的单个字符或单词。字符或单词的识别模型通过对比训练——主要在增强的数字字体上进行——将相同字符或单词的图像裁剪部分映射到相似的向量表征,无论字体和其他变化如何。即使视觉外观非常相似的不同字符或单词,也会被映射到相距更远的位置。通过嵌入单词或字符裁剪部分,并在嵌入数字字体渲染的裁剪部分的索引中检索其最近邻,从而对文档进行转录。训练后可以向索引中添加新的字符或单词(这与分类器不同),这对经济史学家来说是一个有用的功能,因为历史文档集中经常出现特殊符号。
即使使用专为手机设计的轻量级模型(其训练和部署成本较低),EffOCR也能实现高精度识别。例如,对于当前所有解决方案均告失败的日本历史文档,它能够提供一种样本高效且高精度的OCR架构。其准确性与高效运行的特性相结合,也使其在对资源丰富型语言的大规模文档集进行数字化处理时颇具吸引力。Dell et al. (2023)利用EffOCR,以较低成本对美国国会图书馆 “美国纪事”馆藏中超过4.3亿篇历史报纸文章进行了数字化处理。TrOCR是一种精度相近的开源解决方案,但其部署成本几乎是EffOCR的50倍,而商业解决方案的成本更是高得令人却步。
EconDL提供了一个demo链接,可利用最少的云计算资源,为多音调(古代)希腊语训练定制的OCR模型。 Carlson, Bryan and Dell (2024) 指出,该模型在目标数据上的表现优于谷歌云视觉。该笔记本使用了EffOCR软件包(Bryan et al., 2023),用户可通过它调整自己的OCR模型,也能直接使用现成的模型。EffOCR并不专注于手写体识别;不过,其方法可类似应用于手写体识别。例如,Bhunia et al. (2021)开发的合成手写体生成器,可像使用数字字体一样,为预训练提供大量数据。
八、回归
回归与分类类似,不同之处在于添加到神经网络的回归层预测的是一个或多个连续数值,而非一组类别分数。因此,我们在此仅作简要论述,重点聚焦于一个应用:目标检测。
顾名思义,目标检测问题旨在定位图像中的物体((Ren et al., 2017; He et al., 2017; Kirillov et al., 2019; Cai and Vasconcelos, 2019; Redmon et al., 2016; Ultralytics, 2020; Carion et al., 2020; Liu et al., 2021))。例如,一位将公司财务记录数字化的经济学家,需要检测不同文档对象的坐标,如表头、行列标题、表格单元格、脚注等。又如,一位希望从街景数据中衡量非正规经济的经济学家,需要在图像中定位街头小贩。对于每个物体,神经网络输出四个连续数值(包含物体的边界框的左上角x坐标、左上角y坐标、高度和宽度)—这是一个回归问题,同时还输出该物体的类别(如表头、列标题等)—这是一个分类问题。

图11展示了目标检测方法如何用于在历史报纸扫描件中定位和分类文档布局对象(如文章、标题等),从而促进创建可使用现代NLP方法进行分析的结构化数字文本。

相比之下,图12给出了一个示例,展示商业光学字符识别(OCR,如Google Cloud Vision)如何像读取单列书籍一样读取报纸扫描件。对于这些杂乱的文本,人们只能像经济文献中使用历史报纸时常见的那样搜索关键词(可参考Hanlon and Beach (2022) 的综述)。

如图13中日本公司历史记录所示,在将表格数据数字化时,同样需要布局检测来提取结构。目前,文档布局检测通常需要定制。如果目标任务与模型微调的任务非常接近,现成的模型可能会表现良好。然而,在计算机视觉领域,主要的预训练数据集是ImageNet,它由自然图像组成,例如不同品种的狗。模型并未在文档上进行大规模预训练,因此在应用于不同类型的文档时,往往会面临显著的领域偏移问题。对于历史文档来说尤其如此,因为它们具有多样性。
虽然有用于目标定位的基础模型,即Meta AI的“分割一切”(Segment Anything,Kirillov et al., 2023),但在撰写本文时,我发现它对文档任务并不是特别有用。它可以定位图像中的物体,但不会将它们分类到不同类别。此外,目前对文档图像的定位也不是特别准确。
开源软件包Layout Parser(Shen et al., 2021)降低了使用深度学习检测文档布局的门槛。该库包含可供现成使用的模型库,并便于调整定制模型,通过简单的Python应用程序编程接口(API)实现。更多信息可在EconDL资源页面找到。EconDL知识库介绍了用于目标检测的主动学习(Shen et al., 2022),它通过选择模型最不确定的实例进行标注,以节省标注成本。 由于篇幅限制,此处无法深入探讨目标检测模型的架构,但EconDL知识库中关于目标检测的文章提供了详细论述。卫星图像相关资源包括Aleissaee et al. (2022); Wang et al. (2022); Bandara and Patel (2022); Fuller, Millard and Green (2022)等,可从EconDL中处理卫星图像的页面获取链接。
九、替代方法
本综述重点关注了一系列方法,尽管这些方法在深度学习中占据重要地位,但远非全面。如果读者深入研究深度学习文献,会发现针对上述问题的其他方法,并可能疑惑为何未涵盖这些方法。我聚焦于分类器和嵌入模型,是因为它们通常在样本和计算上高效,这意味着它们能从有限的数据中良好地学习,并且可以在受限硬件上低成本部署。它们易于训练,在各种任务上能够达到前沿性能。
本节简要介绍处理光学字符识别(OCR)和实体消歧这两个应用的其他方法,突出问题可以如何以不同方式概念化,并强调嵌入模型在学术应用中的一些优势。
9.1 光学字符识别
第七部分第5节将OCR构建为一个图像检索问题,使用对比训练的视觉模型。这与大多将OCR建模为序列到序列(seq2seq)问题的文献有所不同。Seq2seq模型将一个数据序列转换为另一个序列,常用于输入和输出数据为长度可能不同的序列的情况,如机器翻译。

图14突出显示了EffOCR和seq2seq架构在OCR方面的差异。首先,seq2seq OCR通常需要行级输入,并且不定位单个字符或单词。相反,它将文本行图像或其表示划分为固定大小的补丁。相比之下,EffOCR使用现代目标检测方法(Cai and Vasconcelos, 2018; Jocher, 2020)在输入图像中定位字符或单词。
其次,seq2seq使用学习到的语言模型将由学习到的视觉模型创建的图像表示顺序解码为文本。相反,EffOCR采用对比训练 (Khosla et al., 2020) 来学习OCR的有意义的度量空间。其视觉模型将相同字符或单词的裁剪部分投影到相近位置,而不管其样式如何,同时将不同字符或单词的裁剪部分投影到不同的嵌入中。对于EffOCR,仅视觉嵌入就足以通过从嵌入数字字体创建的索引中检索其最近邻来推断文本。相比之下,对于seq2seq,视觉表示需要用语言模型解码为文本,这需要联合估计数百万个额外参数。
Seq2seq架构的一个缺点是难以扩展和定制到新的设置(Hedderich et al., 2021),因为训练联合视觉-语言模型需要大量标记的图像-文本对和大量计算资源,特别是在使用前沿架构时。由微软研究人员创建的TrOCR——一个transformer seq2seq模型,使用6.84亿个英语合成文本行和32个32GB的V100 GPU进行训练,这是一个成本极高的设置,任何学术研究人员都无法复制。
这个缺点可以用样本效率来量化,样本效率是指模型在接触有限数量的训练示例后的表现能力。一些架构比其他架构学习效率更高。双编码器往往学习效率较高,这对经济学家很重要,因为按照深度学习标准,我们的计算和标注预算非常有限。

图15取自Carlson, Bryan and Dell (2024),通过在相同的小训练集上训练各种开源OCR架构来检验样本效率。x轴绘制了训练中使用的EffOCR训练数据集的百分比,y轴绘制了字符错误率。在仅99个标记的日本表格单元格、美国报纸《Chronicling America collection》中的21个标记行以及数字字体(5%的训练分割)上,EffOCR的字符错误率约为4%,显示出可行的少样本性能。在相同数据上训练的其他架构仍然无法使用。EffOCR使用20%的训练数据的性能几乎与使用70%的训练数据时一样好,并且在这两种情况下都继续优于所有其他替代方案。TrOCR从我们能够提供的少量数据中几乎学不到什么(这就是为什么微软在6.84亿个文本行上对其进行训练)。相比之下,EffOCR可以使用云服务的学生账户甚至在笔记本电脑上进行训练。CRNN是一种更轻量级的旧seq2seq架构,在有限数据下学习效果更好,但使用的是长短期记忆网络(LSTM)而不是transformer,在完全训练时会导致准确性下降。
嵌入模型相较于序列到序列(seq2seq)模型还具有计算优势。EffOCR支持跨字符的推理并行化,从而加快推理速度,而seq2seq需要自回归解码,速度较慢。EffOCR的运行速度大约比TrOCR快50倍,TrOCR是唯一在完全训练后精度可与之媲美的开源模型。我们使用EffOCR,以6万美元的预算创建了包含超过4.3亿篇历史新闻文章的开源数据集“美国故事”(American Stories),实际上无法再获得大量额外资金,更不用说50倍的资金了。样本和计算高效的架构使得在各种场景和大规模文档集合上实现高质量转录成为可能,为经济史的多样化应用带来了大数据。
理论上,从完整的表征序列中获取上下文理解可能会带来更好的OCR效果。但在实践中,最先进的transformer seq2seq模型训练和部署成本高昂,且不适用于资源较少的语言,其进展主要集中在少数几种语言上。摒弃seq2seq模型,能够显著提高样本和计算效率。在学术环境中,这些优势尤为重要,因为我们的应用高度多样化,而预算通常极为有限。
9.2 实体消歧
实体消歧,即将非结构化文本中的实体提及与维基百科等外部知识库相关联,推动了各种架构的发展。其中包括掩码语言模型和神经翻译模型—它使用序列到序列架构将提及内容转换为维基百科标识符,以及将实体消歧视为最近邻检索问题的双编码器嵌入架构。本文的应用(第七部分第3节)采用了后一种架构。
掩码语言模型方法会屏蔽实体,并使用分类器头预测其维基百科标识符。虽然它在某些基准测试中表现领先,但在实际应用中存在重大局限性。语言模型通过分类来预测被屏蔽的词元。由于计算softmax时存在计算限制,LUKE仅限于前5万个维基百科条目。这5万个条目中很多并非人物,而许多出现在历史新闻或政府文件中的人物并不在这前5万之列。此外,它无法处理知识库之外的实体,并且需要稀疏的实体先验来初始化模型。在许多应用中,并非所有个体都在知识库中,模型需要能够对此进行预测。
神经翻译模型的序列到序列架构在推理时速度较慢,运行时间大约是双编码器嵌入模型的60倍。Arora et al. (2024) 还表明,嵌入模型在对历史文本进行消歧时能达到更高的准确率。简而言之,序列到序列架构大规模运行成本高昂,且不一定具有性能优势。
十、总结
深度学习为处理非结构化数据提供了强大的工具。在从文本分类到记录链接、实体消歧以及追踪转载内容传播等一系列社会科学任务中,深度学习相比传统的稀疏方法往往能取得显著优势(F1值/准确率通常能领先20个百分点甚至更多)。深度学习通过提供从大规模非结构化数据中估算结构化信息的工具,能够助力开展创新性分析。在使用轻量级、样本高效的预训练模型时,即使面对包含数百万甚至数十亿观测值的数据集,模型的训练与部署成本也相当可控。对于某些应用场景,深度学习还有望处理来自资源有限环境的数据,这有可能使经济研究更全面地反映人类社会的多样性。然而,熟悉深度学习方法需要付出相当的前期成本。本文以及配套的开源软件包、教程和知识库,旨在为希望在研究中运用深度学习的经济学家大幅降低入门门槛
。
编译 | 白景
终审 | 蒋文臣
©国关计算理论志









