来源 | 苏三说技术 (ID:susanSayJava)
引言
在分布式架构中,MySQL与Elasticsearch(ES)的协同已成为解决高并发查询与复杂检索的标配组合。
然而,如何实现两者间的高效数据同步,是架构设计中绕不开的难题。
这篇文章跟大家一起聊聊MySQL同步ES的6种主流方案,结合代码示例与场景案例,帮助开发者避开常见陷阱,做出最优技术选型。
方案一:同步双写
场景:适用于对数据实时性要求极高,且业务逻辑简单的场景,如金融交易记录同步。
在业务代码中同时写入MySQL与ES。
代码如下:
@Transactional
public void createOrder(Order order) {
// 写入MySQL
orderMapper.insert(order);
// 同步写入ES
IndexRequest request = new IndexRequest("orders")
.id(order.getId())
.source(JSON.toJSONString(order), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
痛点:
-
硬编码侵入:所有涉及写操作的地方均需添加ES写入逻辑。
- 性能瓶颈:双写操作导致事务时间延长,TPS下降30%以上。
- 数据一致性风险:若ES写入失败,需引入补偿机制(如本地事务表+定时重试)。
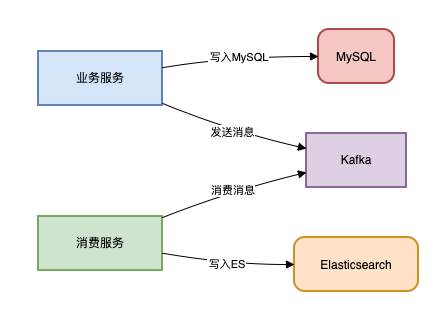
方案二:异步双写
场景:电商订单状态更新后需同步至ES供客服系统检索。
我们可以使用MQ进行解耦。
架构图如下:
代码示例如下:
// 生产者端
public void updateProduct(Product product) {
productMapper.update(product);
kafkaTemplate.send("product-update", product.getId());
}
// 消费者端
@KafkaListener(topics = "product-update")
public void syncToEs(String productId) {
Product product = productMapper.selectById(productId);
esClient.index(product);
}
优势:
缺陷:
- 消息堆积:突发流量可能导致消费延迟(需监控Lag值)。
方案三:Logstash定时拉取
场景:用户行为日志的T+1分析场景。
该方案低侵入但高延迟。
配置示例如下:
input {
jdbc{
jdbc_driver=>"com.mysql.jdbc.Driver"
jdbc_url=>"jdbc:mysql://localhost:3306/log_db"
schedule=>"*/5 * * * *"# 每5分钟执行
statement=>"SELECT * FROM user_log WHERE update_time > :sql_last_value"
}
}
output{
elasticsearch{
hosts=>["es-host:9200"]
index=>"user_logs"
}
}
适用性分析:
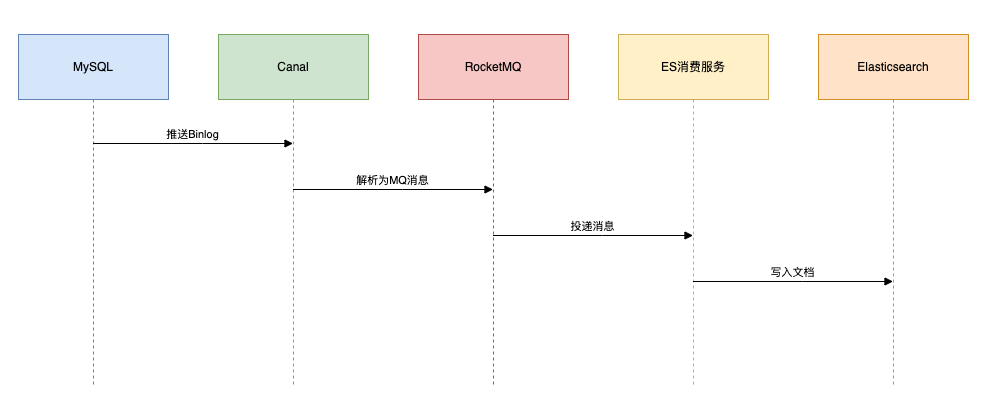
方案四:Canal监听Binlog
场景:社交平台动态实时搜索(如微博热搜更新)。
技术栈:Canal + RocketMQ + ES
该方案高实时,并且低侵入。
架构流程如下:
关键配置:
# canal.properties
canal.instance.master.address=127.0.0.1:3306
canal.mq.topic=canal.es.sync
避坑指南:
- 数据漂移:需处理DDL变更(通过Schema Registry管理映射)。
方案五:DataX批量同步
场景:将历史订单数据从分库分表MySQL迁移至ES。
该方案是大数据迁移的首选。
配置文件如下:
{
"job":{
"content":[{
"reader":{
"name":"mysqlreader",
"parameter":{"splitPk":"id","querySql":"SELECT * FROM orders"}
},
"writer":{
"name":"elasticsearchwriter",
"parameter":{"endpoint":"http://es-host:9200","index":"orders"}
}
}]
}
}
性能调优:
方案六:Flink流处理
场景:商品价格变更时,需关联用户画像计算实时推荐评分。
该方案适合于复杂的ETL场景。
代码片段如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new CanalSource())
.map(record -> parseToPriceEvent(record))
.keyBy(event -> event.getProductId())
.connect(userProfileBroadcastStream)
.process(new PriceRecommendationProcess())
.addSink(new ElasticsearchSink());
优势:
- 状态管理:精准处理乱序事件(Watermark机制)
- 维表关联:通过Broadcast State实现实时画像关联
总结:
对于文章上面给出的这6种技术方案,我们在实际工作中,该如何做选型呢?
下面用一张表格做对比:
苏三的建议:
- 若团队无运维中间件能力 → 选择Logstash或同步双写
- 需秒级延迟且允许改造 → MQ异步 + 本地事务表
- 追求极致实时且资源充足 → Canal + Flink双保险










