作者:沈光宇,爱可生南区 DBA 团队成员,主要负责 MySQL 故障处理和性能优化。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1200 字,预计阅读需要 3 分钟。
背景介绍
MySQL 主从复制 是确保数据库高可用性和扩展性的常用架构。当主从复制存在延迟时,可能导致主从查询数据不一致,影响用户体验和数据库高可用切换。
主从延迟的一个常见原因是 执行大事务,尤其是在涉及多表写入的复杂操作时。
本文基于一个 真实生产案例,分析了业务端因分表操作引发的主从延迟问题,并分享了排查过程及优化建议,为数据库管理员和开发人员提供实用的参考。
问题描述
业务开发团队在程序中实现了一个分表操作:从 1 张大表读取数据,经过计算后写入 100 个分表。
这一过程产生了涉及多表写入的大事务,导致主从复制延迟显著增加。初步观察发现,从库的 relay log 大小为 1.6GB(超过默认值 1.1GB),且从库的 INFORMATION_SCHEMA.INNODB_TRX
表显示存在插入行数较多的大事务,插入行数量动态变化,表明从库正面临较大的复制压力。
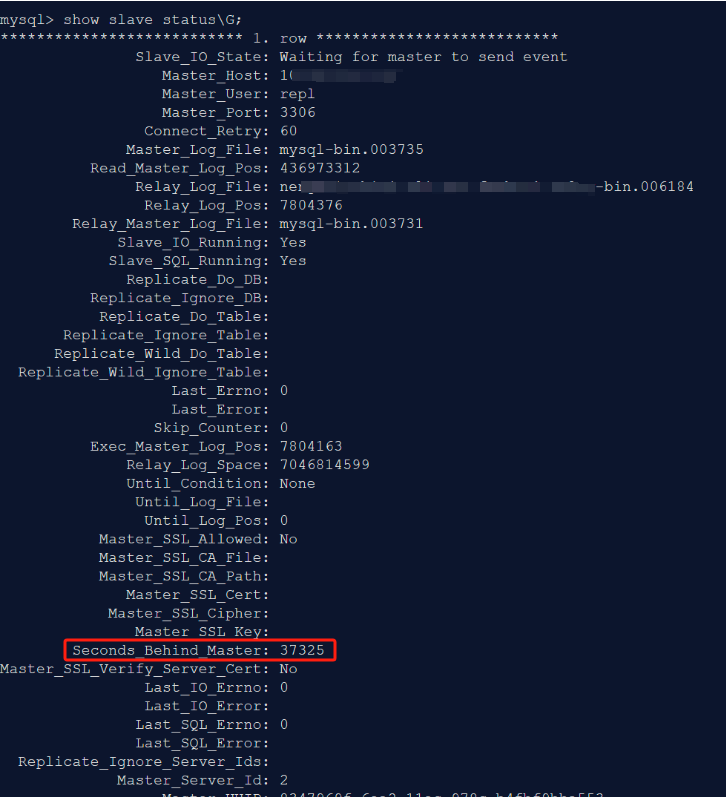
主从延迟状态
从库落后于主库 37325 秒,主从相差 4 个 binlog。
排查过程
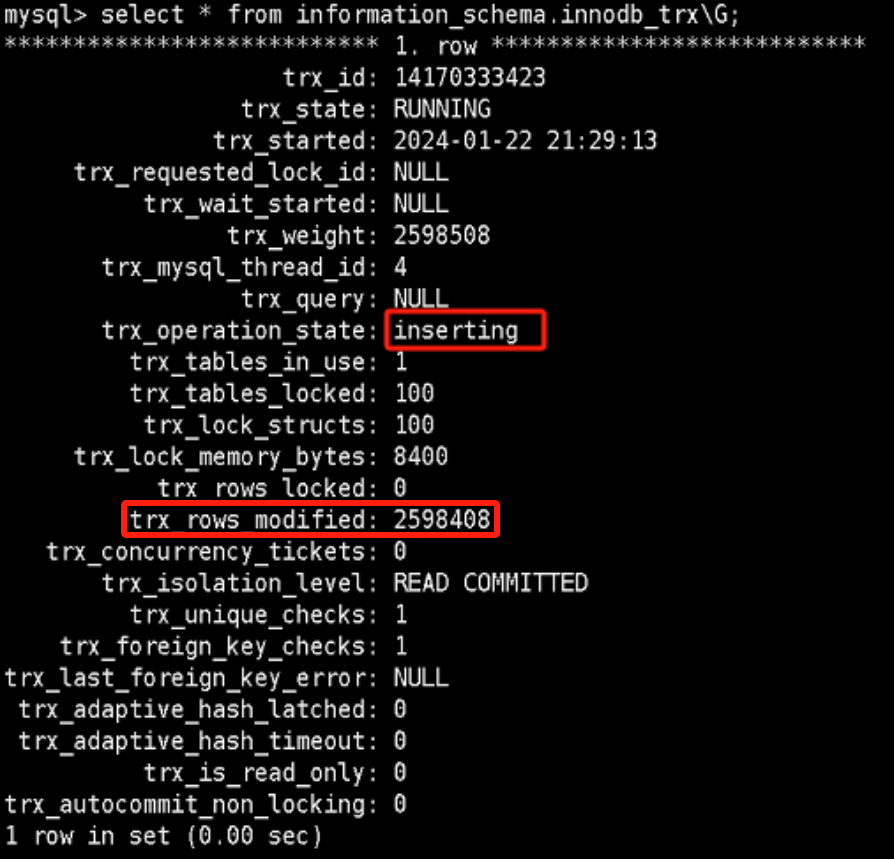
步骤 1:检查从库事务
首先查询了从库的 INFORMATION_SCHEMA.INNODB_TRX 表,以查看当前活跃事务的状态。结果显示存在插入行数较多的大事务,且事务数量不断变化,初步确认大事务是导致延迟的潜在原因。
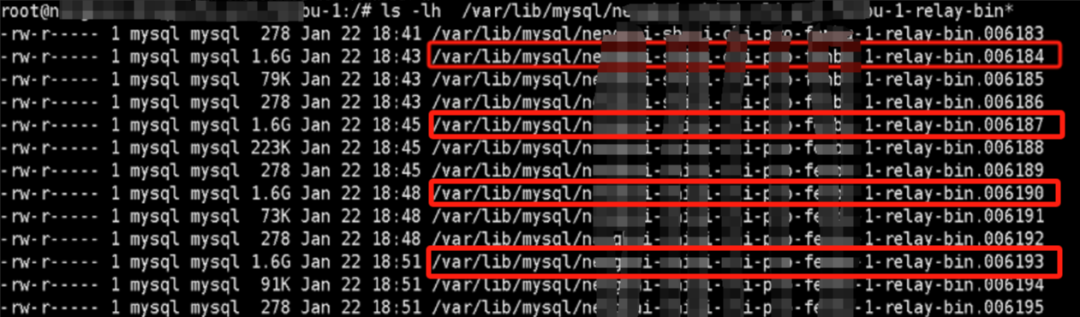
步骤 2:检查从库 Relay Log 大小
检查从库的 relay log,发现其大小为 1.6GB,大于默认的 1.1GB。
步骤 3:解析 Binlog 以查看数据更改行数
shell> mysqlbinlog --base64-output=decode-rows -vv mysql-bin.003731 | awk \
'BEGIN {s_type=""; s_count=0;count=0;insert_count=0;update_count=0;delete_count=0;flag=0;} \
{if(match($0, /^#.*Table_map:.*mapped to number/)) {printf "Timestamp : " $1 " " $2 " Table : " $(NF-4); flag=1} \
else if (match($0, /(### INSERT INTO .*..*)/)) {count=count+1;insert_count=insert_count+1;s_type="INSERT"; s_count=s_count+1;} \
else if (match($0, /(### UPDATE .*..*)/)) {count=count+1;update_count=update_count+1;s_type="UPDATE"; s_count=s_count+1;} \
else if (match($0, /(### DELETE FROM .*..*)/)) {count=count+1;delete_count=delete_count+1;s_type="DELETE"; s_count=s_count+1;} \
else if (match($0, /^(# at) /) && flag==1 && s_count>0) {print " Query Type : "s_type " " s_count " row(s) affected" ;s_type=""; s_count=0; } \
else if (match($0, /^(COMMIT)/)) {print count=0;insert_count=0;update_count=0; delete_count=0;s_type=""; s_count=0; flag=0} } ' > 003731.txt
分析输出文件 003731.txt,发现事务大多数都是插入、更新或删除行均为 1 行、2 行、3 行、4 行。
这并非是一次性插入、更新或删除几十上百万行的大事务,统计修改行数的结果如下:
shell> awk '{print $12}' 003731.txt |sort |uniq -c |sort -nr |head -n 5
4853185 1
1214600 2
202508 3
25647 4
3902
步骤 4:解析 Binlog 以评估事务大小
shell> mysqlbinlog mysql-bin.003731 | grep "^BEGIN" -A 2 |grep -E '^# at' |awk '{print $3}' |awk 'NR==1 {at=$1} NR > 1 {print ($1-at);at=$1}' |sort -n -r |head -n 20 > 003731_top_20.txt
可以看到 binlog 中有 2 个大事务,每个大事务 700 多 MB,与先前的 relay log 大小 1.6G 相吻合
shell> head -n 5 003731_top_20.txt
822733047
822623266
2789
2783
2779
# 解析事务起止位置
shell> mysqlbinlog mysql-bin.003731 | grep "^BEGIN" -A 2 |grep -E '^# at' |awk '{print $3}' > 003731_trx_start_stop_pos.txt
shell> less 003731_trx_start_stop_pos.txt
3142940
3144046
825767312 #事务大小825767312-3144046=822623266 产行binlog大小约766MB
825768589
......
827706566
827708383
1650441430 #事务大小1650441430-827708383=822733047 产生binlog大小约784MB
1650443535
1650444709
步骤 5:使用 my2sql 分析大事务
为了更直观地分析大事务的细节,我们使用了 my2sql[1] 工具对 binlog 进行解析。
shell> ./my2sql -user repuser -password repuserpassword -host 10.235.98.18 -port 3306 -work-type stats -start-file mysql-bin.003731 -stop-file mysql-bin.003735 -big-trx-row-limit 5000 -output-dir /tmp/log/my2sql_output
从输出文件 biglong_trx.txt 中,我们发现 8 个典型的大事务从 2024-01-22 11:00 持续到 2024-01-22 18:48,最长的大事务执行了约 7 小时 48 分钟,每个大事务涉及 400 万行数据,分别写入 100 个分表。事务详情显示了对多个 db.t_sharding_XX 表的插入操作,如下图:

解决方案 123
- 拆分大事务:将多表写入的大事务拆分为多个小事务,分批执行,减少单次事务操作行数和执行时间。
-
优化分表逻辑:在程序中优化数据处理流程,减少不必要的多表操作。
- 监控和报警:建立针对大事务和主从延迟的监控机制,及时发现和处理异常。
[1] my2sql: https://github.com/liuhr/my2sql
MySQL探秘之旅:绕不开的数据库事务










