本文主要探讨了如何利用先进的自然语言处理(NLP)技术和可解释的机器学习(ML)模型,从全球新闻情绪中提取宏观经济Alpha,并将其应用于外汇(FX)和债券市场的交易策略中。
第一章:引言
在信息快速传播的时代,金融市场对新闻和投资者情绪的变化反应迅速。这种现象在宏观资产类别中尤为明显,例如外汇和固定收益产品,来自新闻稿、央行公告和地缘政治报告的非结构化文本可以显著影响资本流动。尽管这些丰富的数据源提供了新的交易见解,但其庞大的数量和语言复杂性带来了巨大挑战。早期基于情绪的交易策略通常依赖于粗糙的词典,经常错误分类特定领域的术语。金融训练的语言模型的出现改变了这一局面,例如FinBERT(一种基于BERT的模型,在金融特定语言上进行了预训练),它在从金融文本中提取细致情绪方面达到了最先进的准确性。
与此同时,量化交易已经采用了机器学习模型,特别是梯度提升树和深度网络,这些模型在捕捉特征之间的非线性交互方面表现出色。然而,这种预测能力往往以透明为代价,这在需要模型可解释性以支持风险管理和合规性的受监管环境中是一个关键的缺点。Shapley Additive Explanations(SHAP)提供了一种原则性的解决方案,通过为每个输入特征分配一个一致且理论上合理的贡献来解释个体预测,从而揭开了“黑箱”算法的神秘面纱。
本论文整合了这些进步——特定领域的NLP、跨资产宏观数据和可解释的ML——以调查全球新闻情绪是否可以通过现代工具进行处理并透明解释,从而在宏观交易中产生系统性的Alpha。研究的目标市场包括欧元/美元(EUR/USD)和美元/日元(USD/JPY)即期外汇汇率,以及10年期美国国债期货(ZN)。研究方法包括从全球事件、语言和语调数据库(GDELT)项目中每日获取新闻,应用FinBERT对每篇文章的情绪进行评分,并将这些评分汇总成一系列特征(包括平均语调、分散度、新闻量和Goldstein评分,以及它们的滞后和滚动统计)。然后训练两个分类器——逻辑回归(作为透明的基线)和XGBoost模型(以利用非线性)——来预测次日回报方向。
本研究的贡献有四个方面:
- 跨资产新闻情绪交易策略:展示了一个统一的新闻驱动策略可以在外汇和债券市场中产生显著的风险调整回报,扩展了通常侧重于股票市场的文献。
- 高级NLP集成:通过利用FinBERT,旨在提高情绪信号质量,捕捉经济新闻中依赖语境的细微差别。
- 模型可解释性:采用SHAP来剖析XGBoost模型的决策,确认了情绪分散度和文章影响等特征推动了与经济直觉一致的预测。
-
稳健的样本外(OOS)证据:回测框架使用2015年1月至2025年4月的数据,采用扩展窗口方法进行OOS评估。考虑到现实的交易成本,该策略产生了令人印象深刻的OOS夏普比率:EUR/USD为5.87,USD/JPY为4.65,10年期国债期货为4.65,结果在子时期和成本假设下保持一致。
本论文的研究表明,基于公开数据和开源模型的透明且可复现的宏观交易策略是可行的。
第二章:文献回顾与创新性
为了明确本研究的贡献,本章回顾了新闻情绪交易和NLP在宏观金融中的应用的关键研究,从而突出了本研究的创新性。
- 外汇新闻情绪策略:Filippou等人(2020)研究了与外汇相关的新闻文章,构建了基于情绪的货币策略。他们发现了一种逆势效应,即媒体情绪低的货币表现优于情绪高的货币。本研究也针对外汇,但采用了先进的情绪模型(FinBERT),并结合了时间序列预测建模和可解释的ML,将分析扩展到债券市场。
- 宏观经济新闻与利率:Audrino和Offner(2024)证明了从宏观经济新闻(特别是关于利率、通货膨胀和劳动力市场的文章)中提取的情绪对短期国债收益率走势具有显著的解释力。本研究的目标与他们的发现一致,但侧重于通过GDELT的每日全球新闻流和交易策略视角,并辅以SHAP以增强可解释性。
- RavenPack外汇情绪:RavenPack(2023)的白皮书表明,宏观新闻情绪指标可以预测G7货币走势。虽然这凸显了新闻情绪对外汇的价值,但本研究的独特之处在于使用开放数据源(GDELT)和透明方法(FinBERT + XGBoost),增加了严格的解释层并考虑了债券市场。
- 大型语言模型(LLM)与金融新闻:Kirtac和Germano(2024)研究了LLM对美国股票新闻的情绪交易,发现GPT-3在股票方面的表现优于FinBERT。他们的工作突出了不断发展的NLP领域。本研究使用FinBERT,该模型适合本研究的目标并且公开可用,但承认未来的研究可能会纳入更新或更大的LLM。本研究的重点仍然不同:宏观资产(外汇、利率)和全球新闻。
- GDELT在宏观预测中的应用:Tilly等人(2021)使用GDELT新闻数据,通过训练双向长短期记忆(BiLSTM)网络对全球新闻中的情绪进行分类,从而改进宏观经济预测。本研究建立在类似的理念上(全球数据、更丰富的情绪衡量),但转向交易信号和不同的工具集(FinBERT用于情绪,XGBoost用于预测),侧重于直接市场影响。
本研究的独特之处在于结合了以下元素:
- 高级特定领域NLP:采用FinBERT(Araci,2019),一种在金融领域预训练的变压器模型,与简单的词典或通用模型相比,能够提供更准确、上下文感知的情绪信号。
- 全球覆盖和针对性过滤:本研究的流程利用了GDELT全面的全球新闻源,专门针对宏观经济相关性进行过滤,从而能够捕捉更广泛的事件。
- 综合跨资产框架:将统一的方法论应用于多个资产类别(外汇和债券期货),展示了新闻情绪信号在不同宏观市场中的普遍性。
- 优先考虑可解释性:采用SHAP(Lundberg & Lee,2017)来解释模型预测,提供了对决策过程的宝贵见解——这是以表现为驱动的研究中经常被忽视的方面。
- 强调可复现性:本研究的方法建立在公开数据(GDELT)和开源模型(FinBERT、XGBoost)之上,使得研究透明,并便于其他研究人员进行复现。
据我们所知,之前没有出版物将FinBERT与GDELT结合起来,使用稳健的ML框架产生对FX和债券市场可解释的交易信号,并展示出这种水平的样本外表现。
第三章:数据与方法
本章节详细介绍了研究的数据来源、情绪提取方法、特征工程过程、预测建模和交易策略结果,以及基于SHAP的可解释性分析。
3.1 宏观新闻收集与标题提取
研究首先使用GDELT v2 API收集宏观相关的新闻标题。从2015年1月1日到2025年4月30日,检索所有事件记录。每个记录包括日期、参与者、事件代码、Goldstein量表(衡量事件影响)和来源URL等元数据。为了专注于经济和政策发展,研究筛选了GDELT事件代码前三位在100-199范围内的事件,这些事件通常涵盖咨询、声明和外交或经济接触。研究对列名进行了标准化(例如,日期、事件类型、Goldstein量表、URL),并将日期转换为日期时间格式。
对于每个日历日,研究按报道的文章数量(num_articles)对筛选后的事件进行排名,并保留前100个条目。这个启发式方法优先考虑广泛报道的故事,这些故事更有可能影响宏观资产价格。然后,研究通过向存储的URL发送并行HTTP请求并解析返回的HTML(通过我们GitHub仓库中提供的utils.headline_utils.fetch_headline函数)来提取每篇文章标题的文本。对于无法提取标题或返回空字符串的事件,则将其丢弃。这个过程最终得到了一个清理后的数据集,每天最多包含100个高可见度的标题,每个标题都附有其原始的Goldstein元数据。
3.2 使用FinBERT进行情绪评分
研究仅对提取的标题进行情绪分析,以最大化稳健性和计算效率。研究采用FinBERT(Araci,2019),这是一种在大型金融文本语料库(包括分析师报告和金融新闻)上预训练的BERT变体,使其擅长理解金融术语。标题经过最少的预处理:它们被转换为小写,去除非信息性符号,并截断为前512个WordPiece标记,以符合模型的最大输入长度。
研究从HuggingFace Transformers库中加载ProsusAI/finbert检查点和关联的tokenizer。如果有可用的GPU,则将模型移动到GPU以加速推理,并设置为评估模式(禁用dropout)。情绪评分以小批量(例如,效率大小为32)进行。对于每个标题批次,研究获得模型的输出logits,然后通过softmax层传递,以产生负面、中性和正面情绪的类别概率,表示为 。研究定义了一个连续的极性分数,用于标题在交易日:
这个分数捕捉了标题的净看涨情绪:接近+1的值表示强烈的正面情绪,接近-1的值表示强烈的负面情绪,而接近零的值则表明中性或混合信号。
3.3 每日情绪指数构建和特征工程
设为交易日的个有效标题的极性分数集合。研究将这些分数汇总成以下主要每日情绪特征:
其中表示第个标题的Goldstein量表值。文章影响特征使用对数转换后的新闻量来缓和异常高新闻数量日的影响。
为了捕捉对预测建模至关重要的时间动态,研究设计了从这些主要汇总中派生的附加特征。这些包括:
- 移动平均(MA):的5天和20天MA,以平滑短期噪音并识别趋势。
- 滚动标准偏差:每日平均情绪的5天和10天滚动标准偏差,作为情绪稳定性的衡量。
- 滚动总和:新闻量的5天和10天滚动总和,表明累积的新闻流。
这些特征共同构成了我们预测模型的替代数据输入,编码了新闻情绪的当前状态和近期演变。
3.4 市场数据和回报
研究从2015年1月1日到2025年4月30日获取了三个目标工具——欧元/美元、美元/日元和10年期美国国债期货(代码ZN)的每日市场数据。
- 数据来源:外汇即期汇率(欧元/美元、美元/日元)来自Yahoo Finance(代码EURUSD=X、USDJPY=X)。一个连续的10年期国债期货系列(ZN)也来自Yahoo Finance(代码ZN=F),并应用标准的连续合约滚动调整,以减轻合约到期造成的价差。
- 回报计算:我们定义次日的对数回报为,其中是交易日的收盘价。由于其加法特性和更有利的统计特性,对数回报通常更受金融时间序列的青睐。
- 目标变量:交易日的二元预测目标定义为1,如果次日的回报(向上移动),定义为0,如果(向下或持平移动)。
- 对齐和防止前瞻性偏差:所有新闻派生的情绪特征和市场技术特征都是使用截至交易日市场收盘时可用信息构建的。然后,这些特征用于预测从交易日收盘到交易日收盘的市场方向。这种结构严格确保了特征集中的前瞻性偏差。
- 附加市场特征
:为了向ML模型提供超出情绪的市场背景,我们包括:
- 滞后回报:(从交易日收盘到交易日收盘的回报),以捕捉短期动量或逆转效应。
- 历史波动率:20天年化标准差每日对数回报,,以反映当前的市场波动制度。
- 特征缩放:对于逻辑回归模型,所有连续输入特征都进行了标准化(通过减去均值并除以标准差,使用的统计数据仅来自当前训练集)以确保系数大小的可比性并提高数值稳定性。XGBoost,作为基于树的模型,对单个特征的单一变换基本上是不变的,因此严格来说不需要缩放,尽管在对原始新闻量进行缩放之前应用了对数变换,以构建其他基于量的特征。
3.5 预测建模和训练协议
我们将交易信号生成任务构建为一个次日二元分类问题)。对于每个资产,我们独立训练和评估两个不同的分类模型:
逻辑回归(LOGISTIC):一种线性模型,因其简单性、可解释性和作为稳健基线的效用而选择。它采用L2(Ridge)正则化以防止过拟合并提高泛化能力。预测概率(其中是Sigmoid函数)被解释为向上市场移动的可能性。正则化强度(超参数)使用时间序列交叉验证在每个训练集上选择。
极端梯度提升(XGBoost,XGB):一种梯度提升决策树的集成,因其高预测性能和自动捕捉复杂非线性关系和特征交互的能力而闻名。该模型配置为最小化二元逻辑损失。超参数(例如,树深度、学习率、树的数量,以及权重上的L1/L2正则化惩罚)通过网格搜索方法结合训练数据的5折时间序列交叉验证(CV)进行调优。在训练过程中的验证折叠上基于性能的提前停止被用来确定最优的提升轮数,并进一步防止过拟合并提高泛化能力。
训练和回测协议:本研究的数据总周期从2015年1月1日到2025年4月30日。
扩展窗口交叉验证(CV):为了确保对样本外(OOS)性能的稳健评估,并模拟模型定期用新数据重新训练的现实交易条件,我们采用5折扩展窗口结构。这是使用scikit-learn的TimeSeriesSplit(n_splits=5)实现的。数据集是按时间顺序排列的。对于每个折叠,训练集包括从样本开始到第个测试块开始的所有数据。第个测试块是紧随其对应训练集之后的一个连续数据段。最初的一个时期(例如,2015年1月-2016年12月,大约两年)被用来形成第一个训练集,确保有足够的观察数据用于初始模型估计。因此,OOS测试实际上从2017年初到2025年4月,横跨五个后续测试折叠。
-
特征热身期:在每个训练分割开始时,相当于特征工程中使用的最大滞后或滚动窗口长度(例如,20个交易日)的时期仅用于构建完整的特征集。这些初始观察数据,由于缺乏构建所有滞后或滚动特征所需的完整历史数据,不直接用于模型拟合。
折叠内模型拟合和评估:对于5个交叉验证折叠中的每一个:
(a) 当前训练分割的输入特征被适当地缩放(特别是,逻辑回归的标准化)。然后,选定的分类器(逻辑或XGBoost)在这个训练分割上进行训练。每个模型的超参数通过专门应用于这个特定训练数据的内部交叉验证程序进行调优,以防止未来测试集的信息泄漏。
(b) 在步骤(a)中训练的模型随后应用于折叠的相应(未见过的)测试段,以生成每日预测概率。基于0.5的简单阈值生成交易信号:如果,则在日启动多头头寸(+1单位),如果,则在日启动空头头寸(-1单位)。
(c) 基于这些头寸和日的实际实现市场回报计算每日策略回报。从这些回报中扣除交易成本:每轮外汇对交易价值的0.02%,ZN国债期货为0.05%,反映了合理的经纪成本。
(d) 计算折叠级性能指标,包括ROC曲线下面积(AUC)、准确性、年化夏普比率和复合年增长率(CAGR),以评估该段的表现。
聚合OOS结果:最终报告的性能指标,如表1所示,是根据所有五个测试折叠的每日OOS预测和策略回报的时间序列得出的。这个累积系列代表了策略在整个有效OOS测试期间(大约2017年初-2025年4月)对真正未见过的数据的整体表现。
性能统计显著性:为了评估关键性能指标如夏普比率和CAGR的统计稳健性,我们采用块自举程序(例如,1,000次重采样,块大小为20个交易日,近似一个月的交易数据以保持自相关)对聚合的每日OOS策略回报进行评估。这产生了95%的置信区间,虽然出于简洁性的原因未在表1中详细说明,但它为我们讨论策略的稳健性提供了信息,并帮助确定性能是否与偶然性有显著区别。
第四章:结果与分析
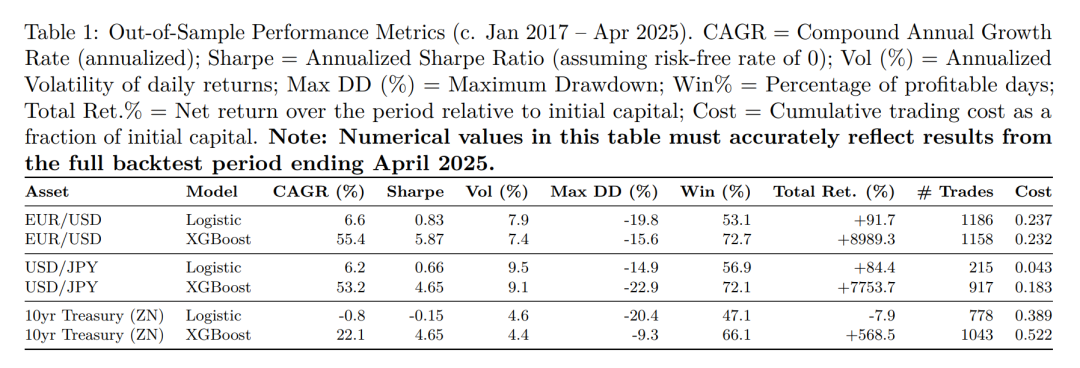
表1报告了每个资产-模型组合在整个样本外测试期间(从2017年初到2025年4月)的关键性能指标。所有策略均以1.0的初始名义资本开始,每天将利润再投资,并产生如方法论中指定的交易成本。
XGBoost模型在所有目标资产上表现出异常强大且一致的性能,显著优于逻辑回归基线。夏普比率超过4.6,表明产生了高效的Alpha生成,这一结果在考虑到现实交易成本和严格的OOS评估方法后尤为显著。CAGR数字XGBoost模型也相当可观,表明了显著的资本增值潜力。相比之下,逻辑回归模型在生成一致Alpha方面挣扎,尤其是对于国债,这凸显了捕捉XGBoost擅长的非线性关系和复杂特征交互的重要性。
4.1 使用SHAP的特征重要性与模型可解释性
本研究的另一个主要目标是确保我们的预测模型不仅准确,而且可解释。虽然逻辑回归模型的系数提供了对线性特征贡献的直接见解,但要理解更复杂的XGBoost模型的决策过程需要专门的技巧。为此,我们采用SHAP(Lundberg & Lee,2017)值。SHAP提供了一个统一的模型解释框架,根据合作博弈理论的原则,为每个特征分配一个“重要性值”用于每个个体预测。这些值代表了每个特征对预测的边际贡献,与基线(训练数据的平均预测)相比。
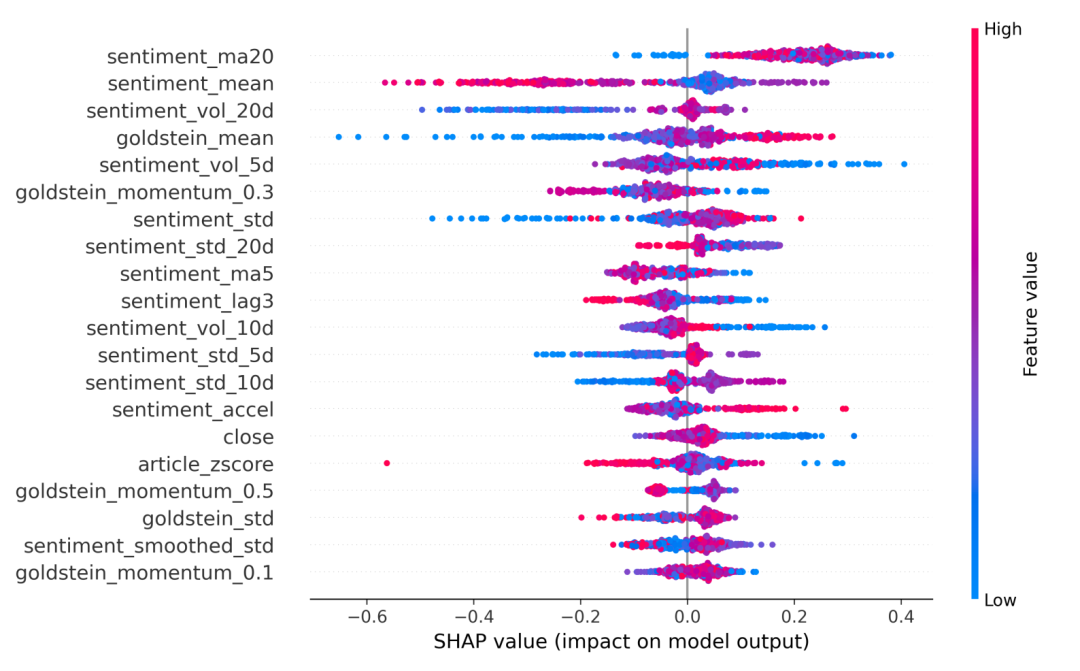
图1展示了EUR/USD XGBoost模型的SHAP汇总图;类似的模式,观察到USD/JPY和ZN的特定资产细节。从这个图表中可以得出的关键观察包括:
- 情绪分散度(sentiment_std):这个特征,代表某一天情绪评分标准差,经常作为一个顶级预测因子。高值(表示更多样化或冲突的新闻语调,显示为红色)往往与负的SHAP值聚集,表明新闻分歧增加预测了EUR/USD的向下移动。相反,低分散度(新闻语调清晰一致,显示为蓝色)通常推动预测向上。
- 文章影响(article_impact)
:这个特征,结合了平均情绪和(对数)新闻量,也是高度影响力的。高正的文章影响(反映许多正面文章或适度量上的强烈正面情绪)产生了大的正SHAP贡献(看涨)。相反,高负影响(许多负面文章)强烈推动预测向下。
- 平均情绪(sentiment_mean):平均每日情绪本身排名很高。与直觉一致,较高的平均情绪(红色点)通常将预测转向向上移动,而较低的平均情绪(蓝色点)则转向向下。
- 滞后情绪和移动平均(例如,sentiment_lag1, sentiment_ma5):包含这些特征表明,最近的情绪趋势和动量是有信息的。SHAP图表可以揭示非线性效应,例如,前一天的情绪极端高可能会略微增加向下修正的概率。
- Goldstein评分(goldstein_mean):平均Goldstein量表值,反映了事件的可能影响或强度,也做出了贡献。较高的Goldstein评分(通常与更合作或重要的国际事件相关)往往预测风险资产的向上移动。
- 市场波动(volatility_20d):资产的过去价格波动作为中级特征出现。通常,高的现有波动制度(红色点)有助于向下预测,可能反映了市场的风险规避倾向。
这些模式证实了XGBoost模型的决策主要由新闻情绪中派生的经济直觉信号驱动。SHAP分析阐明了模型如何综合新闻的各种维度——其整体语调、共识程度、覆盖量以及报道事件的影响——以及它们的时间动态,以得出每日的交易预测。这种可解释性水平对于建立对模型的信任,理解其在不同市场条件下的行为,并将其输出转化为可操作见解至关重要,有效地定位模型为一个“增强分析师”。
第五章:讨论
研究结果表明,系统处理的新闻情绪,当被适当的ML模型利用时,可以成为宏观资产回报的强大预测因子。本章节深入探讨了跨资产行为差异、我们方法的稳健性以及可解释性的关键作用。
5.1 跨资产差异:外汇与债券
一个显著的观察是,外汇对和国债期货之间的表现特征差异。尽管XGBoost模型在所有资产上都提供了高夏普比率,但外汇策略的CAGR明显高于ZN国债策略。造成这种差异的因素可能有几个:
-
内在波动性和机会集:外汇市场,特别是像欧元/美元和美元/日元这样的主要对,往往表现出比10年期国债期货价格更高的百分比波动(特别是在利率稳定时期)。一个预测信号在更波动的市场中可以转化为更大的绝对回报,因为要捕捉的价格变动幅度更大。
- 市场机制和情绪联系:外汇汇率受到相对经济表现、国际资本流动和广泛风险情绪的复杂相互作用的影响。全球新闻情绪——特别是普遍的经济乐观或悲观情绪——通常直接转化为风险偏好/风险规避行为,这在FX市场中表现得尤为强烈(例如,普遍积极的市场情绪可能会看到像美元和日元这样的避险货币对更敏感于增长的货币走弱)。我们的模型似乎有效地捕捉了这些动态。相比之下,新闻情绪与债券价格之间的关系通常是相反的。积极的宏观经济新闻可能对国债价格有害,原因有几个:它可能预示着一个“风险偏好”的环境,促使资金流出避险债券,或者它可能导致中央银行预期货币紧缩政策(更高的利率),导致收益率上升和债券价格下跌。XGBoost模型的灵活性使其能够学习这些不同的、有时是反直觉的(对于简单的积极/消极情绪映射)关系对于不同的资产类别。例如,XGBoost可能会正确学习到高积极情绪预测ZN期货的价格向下移动。像逻辑回归这样的线性模型在捕捉这种符号翻转或依赖语境的关系时可能会遇到困难。
研究结果表明,尽管新闻情绪在各类资产中都包含了有价值的信息,但其转化为价格变动的方式是特定于市场的。灵活的非线性模型对于揭示这些细微的响应函数至关重要。
5.2 稳健性与验证
本研究的几个方面有助于所报告结果的稳健性:
- 严格的样本外测试:扩展窗口交叉验证协议确保模型性能在整个多年期间始终在真正未见过的数据上进行评估,模拟了模型部署的真实场景,其中模型会定期重新训练。
- 包含交易成本:在考虑到现实的交易摩擦后,策略仍然非常有利可图,这表明了其实践适用性。
- 一致的子时期表现:虽然未详细说明,但对个别交叉验证折叠结果的分析表明,XGBoost策略通常在整体OOS测试窗口内的不同子时期内保持了强劲的表现,而不是依赖于特定的市场制度。
- 可解释性作为健全性检查:SHAP分析证实,模型依赖于经济上有意义的、基于新闻的特征作为主要驱动因素,而不是利用虚假的关联或过度拟合噪声。
本研究的一个主要局限性是其依赖于每日频率的数据。重大新闻事件可以在日内时间尺度(分钟或小时)内被市场吸收,这意味着每日模型可能会捕捉到残余的漂移或错过最直接的影响。我们选择每日频率与典型的日终再平衡实践和GDELT数据的自然聚合周期保持一致,但日内扩展仍然是一个有价值的研究方向。
5.3 可解释性作为采用和信任的关键
强调像SHAP这样的可解释ML技术不仅仅是一个学术练习;它是将复杂模型转化为实用交易工具的关键。在机构投资环境中,基金经理更有可能采用并分配资金给那些他们能够理解和合理化的决策过程的策略。SHAP提供了一个叙述(例如,“模型建议做多欧元/美元,因为新闻情绪非常积极,并且在许多高影响力文章中广泛一致”),这与自由裁量推理是一致的。这比一个不透明的“黑箱”信号要令人安心和可操作得多。此外,可解释性作为强大的调试和验证工具。如果SHAP分析揭示模型的预测是由不相关或虚假的特征驱动的,它将严重质疑策略的底层逻辑。相反,它证实了基于新闻的情绪特征的重要性,增强了人们对方法的信心。在持续的风险管理中,如果策略表现下降,SHAP输出可以提供宝贵的诊断——可能是通过揭示模型被前所未有的新闻制度所迷惑,或者特征关系已经改变。这种透明度使得干预和模型更新更加明智。
第六章:结论与未来研究
本论文提出了一个端到端的框架,用于将原始全球新闻事件转化为可操作的宏观经济交易信号,使用先进的NLP(FinBERT)和可解释的ML(带有SHAP的XGBoost)。研究结果表明,利用这些技术的策略可以在主要外汇对和美国国债期货的样本外基础上实现极高的风险调整回报,即使在考虑到交易成本后也是如此。基于SHAP的可解释性提供了对模型决策过程的宝贵见解,证实了它依赖于从新闻情绪中派生的经济合理的驱动因素。
本研究表明,将复杂但可解释的AI方法与替代数据源整合在一起,可以在复杂的宏观市场中发现Alpha。它提供了一个透明且可复现的蓝图,弥合了定性新闻叙述与定量交易之间的差距。以下是本研究提出的几个有前景的未来研究方向:
- 日内分析与实时交易:将框架适应于更高频率的新闻源和日内交易执行,可能会捕捉到新闻对市场的更即时反应。
- 扩展到其他宏观资产:将方法论应用于其他重要的宏观资产,如股票指数、大宗商品(石油、黄金)以及更广泛的国债或新兴市场工具。
- 增强NLP与多语言情绪和主题聚焦:使用多语言变压器模型纳入除英语以外的其他语言新闻,并开发更细粒度的情绪衡量,专注于特定的宏观经济主题(例如,通货膨胀情绪与增长情绪)。
- 自适应和在线学习框架:开发能够动态适应不断变化的市场制度、新闻格局的变化或情绪与资产价格关系转变的模型。
- 与其他替代数据源的整合:将新闻情绪特征与其他形式的替代数据(例如,社交媒体情绪、卫星图像指标、地缘政治风险指数)结合起来,建立更全面的预测模型。
-
探索更深层次的经济因果关系:超越预测准确性,调查新闻情绪影响市场行为、订单流和风险溢价的因果机制。
本研究提供了强有力的证据,表明将可解释的机器学习应用于全球新闻情绪,可以成为现代量化宏观交易策略的宝贵组成部分。









