深度学习“三巨头”——Geoffrey Hinton、Yann LeCun 和 Yoshua Bengio,为推动学术界更广泛地接纳深度学习,将 20 世纪 40 至 50 年代就已问世的神经网络重新包装,提出“深度学习”(Deep Learning)这一概念,本质上即深度的神经网络。
 感知机于1957年提出的仅含输入层与输出层、通过加权求和加偏置后经激活函数输出二分类结果的早期神经网络模型。(1)没有隐藏层:只有输入层和输出层,2层网络结构。(2)线性运算:接收输入层的信号,通过加权求和并加上偏置值。(3)激活函数:通过一个激活函数(如阶跃函数)将结果转化为输出信号。二、前馈神经网络(Feedforward Neural Network)或者多层感知机(Multilayer Perceptron, MLP)前馈神经网络(FFNN)又名多层感知器 (MLP),是神经网络模型中最常见的一种。FFNN的
基本结构包括输入层、输出层和至少一层或多层的隐藏层。其各层神经元分层排列,每个神经元只与前一层的神经元相连,接收前一层的输出并传递给下一层,各层之前没有反馈。(2)隐藏层:位于输入层和输出层之间,用于提取特征与整合。
感知机于1957年提出的仅含输入层与输出层、通过加权求和加偏置后经激活函数输出二分类结果的早期神经网络模型。(1)没有隐藏层:只有输入层和输出层,2层网络结构。(2)线性运算:接收输入层的信号,通过加权求和并加上偏置值。(3)激活函数:通过一个激活函数(如阶跃函数)将结果转化为输出信号。二、前馈神经网络(Feedforward Neural Network)或者多层感知机(Multilayer Perceptron, MLP)前馈神经网络(FFNN)又名多层感知器 (MLP),是神经网络模型中最常见的一种。FFNN的
基本结构包括输入层、输出层和至少一层或多层的隐藏层。其各层神经元分层排列,每个神经元只与前一层的神经元相连,接收前一层的输出并传递给下一层,各层之前没有反馈。(2)隐藏层:位于输入层和输出层之间,用于提取特征与整合。FFNN模型表达式:FFNN(x) = max(0, xW1 + b1)W2 + b2 (2)
在前馈神经网络中,权重(W)和偏置(b)是两个非常重要的参数,它们决定了神经元之间的连接强度和神经元的输出。(
权重(W)和偏置(b)刚开始随机初始化,后续通过模型训练从数据中不断学习更新)
前馈神经网络(FFNN)通过随机初始化参数,利用反向传播算法计算梯度,并采用优化算法如随机梯度下降来迭代更新参数,以最小化损失函数并提升模型性能。模型学习的本质就是模型训练,通过不断训练、验证和调优,让模型达到最优的一个过程。(下面的流程对于初学者有点懵逼,可以借助Claude生成一个模型训练代码,找一个云算力平台实践下模型训练,打印下模型训练过程中损失曲线的变化,直观的感受下模型是如何从数据中学习)(1)参数初始化:神经网络的参数(包括权重和偏置)在训练开始前会被随机初始化。
(2)前向传播:在训练过程中,输入数据通过神经网络进行前向传播,计算出模型的输出。这个过程涉及将输入数据与每一层的权重和偏置进行线性组合,然后应用激活函数来引入非线性。
(3)反向传播:利用反向传播算法来计算损失函数相对于模型参数的梯度。这个过程涉及从输出层开始,逐层计算损失对参数的偏导数,并将这些梯度信息从输出层传播回输入层。
(4)参数更新:得到梯度后,使用优化算法(如随机梯度下降SGD、Adam、RMSprop等)来更新模型的参数。优化算法根据计算出的梯度来调整模型参数,以最小化损失函数。
(5)迭代训练:上述步骤(从前向传播到参数更新)会反复进行,直到模型在验证集上的性能达到满意的水平,或者达到预设的训练轮数(epochs)。
前馈神经网络(FFNN)从数据中学习的训练流程会贯穿整个深度学习,里面涉及的专业术语(前向传播、反向传播、激活函数、梯度下降、Adam和AdaGrad等其它优化器)都会在后面进行详细讲解。感知机(Perceptron)可以解决线性二分类问题,而现实世界中的复杂问题都是非线性多分类问题。
前馈神经网络(FFNN)通过隐藏层将神经元组合在一起,能够形成复杂的决策边界,进而处理现实世界中复杂的非线性问题。
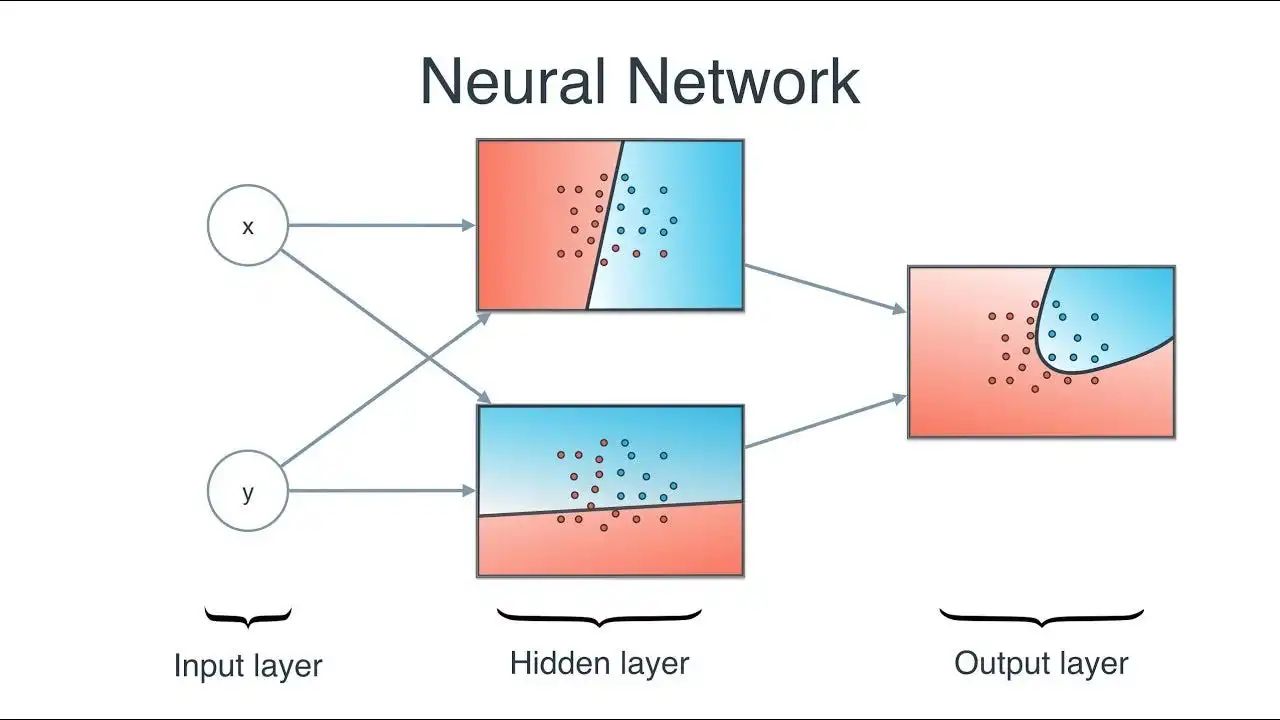
前馈神经网络(多层感知机MLP)在Transformer中通过非线性变换与特征整合,辅助Attention模块处理信息。(FFNN在Transformer中的应用会在后面进行详细讲解)
(1)非线性变换:MLP通过引入激活函数(如ReLU)提供非线性变换,这有助于模型捕获输入数据中的复杂模式。
(2)特征提取与整合:MLP进一步处理和转换注意力机制提取的特征,提取和整合更多有用的信息,使其能够学习更加复杂的函数关系。









