太长不看版
LLM 自回归做理解,MaskGIT 方案做生成的生成理解统一模型。
VILA-U 是一个可以做图像文本理解,视频文本理解,图像生成和视频生成的 Unified Model。VILA-U 的主要贡献是提出了一种视觉架构 Unified Foundation Vision Tower,这是一种针对 image 的 tokenizer。它的训练过程除了用于图像重建的 Reconstruction Loss 之外,还有针对图像理解的图文 Contrastive Loss。相比于其他的视觉 tokenizer 而言,VILA-U 训练的 Unified Foundation Vision Tower 不但针对视觉生成,还针对视觉理解任务。此外,VILA-U 所有的 token 都采用了 Unified Model 常用的 Next-Token Prediction 的训练模式,使用统一的训练目标。
下面是对本文的详细介绍。
本文目录
1 VILA-U:生成理解统一模型视觉侧引入文本对齐
(来自清华大学,MIT,NVIDIA 韩松团队)
1 VILA-U 论文解读
1.1 VILA-U 模型
1.2 VILA-U 的视觉模型
1.3 生成式预训练
1.4 VILA-U 实验设置
1.5 VILA-U 实验结果
1VILA-U:生成理解统一模型视觉侧引入文本对齐
论文名称:VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation (ICLR 2025)
论文地址:
https://arxiv.org/pdf/2409.04429
项目主页:
https://github.com/mit-han-lab/vila-u
1.1 VILA-U 模型
结合视觉和语言模式的一个方向是多模态理解,另一个重要研究方向是
视觉生成。文本引导图像生成有 2 种流行的方法。一种方法是使用 Diffusion Model。另一种方法通过 Vector Quantization (VQ) 将视觉内容转换为 discrete tokens,然后利用自回归 Transformer 进行高质量和多样化的生成。
一个新兴趋势是将这些技术统一到一个多模态框架中。有 2 种实现这种统一的主要方法。许多 VLM[1]维护一个面向理解的框架,并将生成任务卸载到外部扩散模型中。这种不相交的方法增加了基础设施设计的复杂性。可用的大规模基础模型的 training pipeline 和 development system 已经针对 Next Token Prediction 的模型进行了高度优化。设计一个新的堆栈来支持扩散模型会产生重大的工程成本。为了规避这样的成本,现在的趋势是设计一个端到端的自回归框架。VLM 的趋势采用 VQ Encoder 将视觉输入转换为 discrete tokens,并以与语言数据相同的 Next Token Prediction 的方式处理视觉 token。但是,用 VQ token 替换连续 token 通常会导致下游视觉感知任务的严重性能下降。
如图 1 所示,VILA-U 是一个端到端的自回归框架,对于视觉和文本输入具有统一的 Next Token Prediction 训练目标。VILA-U 是一种生成理解统一架构,在视觉语言理解和生成任务上取得具有竞争力的性能,同时不需要借助扩散模型等外部组件。
VILA-U 确定关键的 2 点:
- 现有端到端 VLM 视觉理解性能不佳的原因是:discrete VQ tokens 只在 Reconstruction Loss 上训练,与文本输入不对齐。因此,在 VQ vision 模型预训练中引入文本对齐以增强感知能力至关重要。
- 如果在具有足够大小的高质量数据语料库上进行训练,自回归图像生成可以获得与扩散模型相似的质量。
基于这 2 点,VILA-U 的 vision 模型通过 vector quantization 将视觉输入转化为 discrete token,并且使用 Contrastive Learning 将这些 token 与文本输入对齐。
1.2 VILA-U 的视觉模型
VILA-U 的关键之一是视觉架构
Unified Foundation Vision Tower,它将视觉输入转换为与文本对齐的 discrete token。也就是说,Unified Foundation Vision Tower 在训练的时候,考虑了图像与文本的对齐。VILA-U 的另一个关键之一是统一的多模态生成式训练方案。VILA-U 的方案如图 1 所示。视觉输入被 tokenized 成 discrete tokens,与 text token 拼接在一起,形成多模态的输入序列。所有的 token 都按照 next-token prediction 训练。推理的时候,文本 token 使用 text detokenizer 输出,视觉 token 使用 vision tower decoder,形成多模态输出。
 图1:VILA-U 的训练和推理。视觉输入被 tokenized 成 discrete tokens,与 text token 拼接在一起,形成多模态的输入序列。所有的 token 都参与 next-token prediction 过程,使用统一训练目标。推理的时候,文本 token 使用 text detokenizer 输出,视觉 token 使用 vision tower decoder
图1:VILA-U 的训练和推理。视觉输入被 tokenized 成 discrete tokens,与 text token 拼接在一起,形成多模态的输入序列。所有的 token 都参与 next-token prediction 过程,使用统一训练目标。推理的时候,文本 token 使用 text detokenizer 输出,视觉 token 使用 vision tower decoder为了支持视觉理解和生成任务,VILA-U 首先构建了一个 Unified Foundation Vision Tower 来获取视觉特征。
在训练中,VILA-U 使用了 1) 文本-图像之间的 Contrastive Loss,2) 基于 Vector Quantization 的图像 Reconstruction Loss。使得 Unified Foundation Vision Tower 同时具有文本对齐和 discrete tokenization 的能力。
如下图 2 所示,从图像中提取的特征主要是通过 Residual Quantization 离散化的。一方面,离散的视觉特征输入解码器来重建图像并计算重建损失;另一方面,离散视觉特征与文本编码器提供的文本特征之间计算图像-文本对比损失。
 图2:Unified Foundation Vision Tower 设计。vision encoder 提取的图片特征首先使用 residual quantization 被离散化,然后离散的视觉特征放到 vision decoder 中 1) 重建图像,2) 进行图文对齐。在此过程中,Reconstruction Loss 和 Contrastive Loss 更新其参数。最后它可以得到图文对齐的离散特征
图2:Unified Foundation Vision Tower 设计。vision encoder 提取的图片特征首先使用 residual quantization 被离散化,然后离散的视觉特征放到 vision decoder 中 1) 重建图像,2) 进行图文对齐。在此过程中,Reconstruction Loss 和 Contrastive Loss 更新其参数。最后它可以得到图文对齐的离散特征但是,在实践中作者发现直接这样训练有问题 (对比损失和重建损失的直接组合不能收敛)。因为
图文对齐和重建任务分别需要高级语义特征和低级外观性特征。使用 2 个目标从头开始训练可能会导致相互冲突的目标。从头开始训练 Unified Foundation Vision Tower 导致ImageNet 上 Zero-Shot 图像分类的 Top-1 精度仅为 5%。
为此,作者尝试了不同的 training recipe。本文使用的 training recipe 不是同时学习 2 个目标,而是首先为模型配备文本图像对齐能力,然后在保持对齐能力的同时学习重建。作者使用 CLIP 预训练权重初始化 vision encoder 和 text encoder,以确保良好的文本图像对齐。接下来,冻结文本编码器,并保持所有视觉模型使用 Contrastive 和 Reconstruction Loss 训练。这种训练方法收敛很快并产生强大的性能。预训练的 CLIP 权重包含高级先验,对于从头开始学习来说既困难又计算成本高。使用这些权重进行初始化可以使视觉编码器更快、更轻松地结合低级和高级特征。通过这种训练配方,可以有效地训练出具有良好文本对齐和图像重建的视觉模型。具体而言,使用加权和来组合图文对比损失和 VQ 图像重建损失:
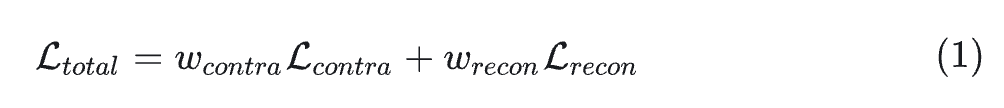
\text { 其中,} w_{\text {contra }}=1, w_{\text {recon }}=1 \text { 。 }
Residual Vector Quantization
VILA-U 的视觉特征是离散化,因此其表征能力在很大程度上取决于 Quantizer Codebook 的大小。由于希望它们同时包含高级特征和低级特征,因此向量特征空间中需要更多的容量,需要 Codebook 比较大。
VILA-U 按照 RQ-VAE[2]的做法使用 Residual Vector Quantization,把一个向量 \mathbf{Z} 离散化成 D 个 discrete tokens:
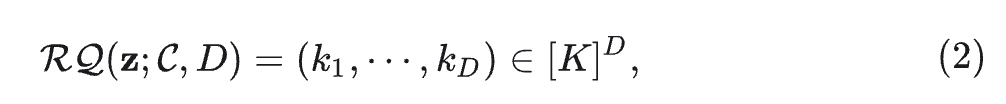
其中, 是 codebook, 和 是向量 在深度 时的 code 值。从 开始,对每一维度深度 递归地执行向量量化:

其中, e 为 codebook embedding table, 是标准向量量化。
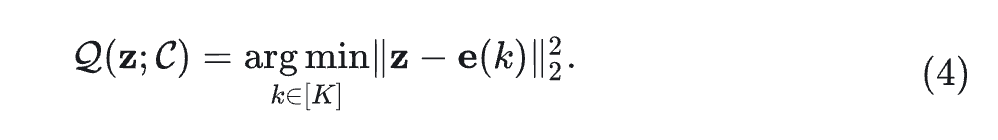
其中, 的 Quantized Vector 是所有深度的求和:
。
1.3 生成式预训练
图 1 为 VILA-U 多模态预训练过程。视觉编码器按顺序处理视觉输入,生成一个一维 token 序列。然后将这个序列与文本 token 连接起来形成一个多模态序列。为了区分模态并实现视觉内容生成,在图像 token 的开始和结束处插入特殊标记: 和 ,在视频 token 的开始和结束位置插入 和 。视频 token 是多帧图像标记的直接连接。
预训练数据格式
[image, text], [text, image], 和 [text, video],只把 supervision loss 加到后面的模态数据。
还使用交错 text 和 image 连接形式来增强理解,supervision loss 仅应用于 text。
出于效率原因,在预训练期间排除了 [video, text] 形式,因为发现在 supervised fine-tuning 期间结合它可以有效地产生出色的视频理解能力。
训练目标
对于 text tokens,使用:
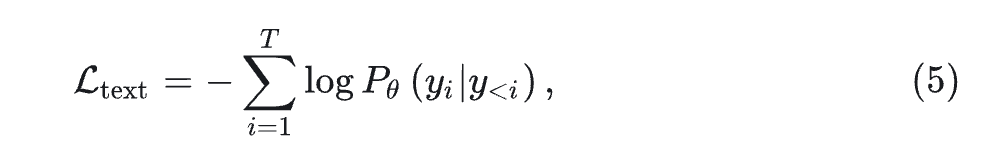
\text { 其中,} T \text { 是多模态序列的总长度,} i \text { 只计算 text token 存在的位置。 }
对于 visual tokens,使用:
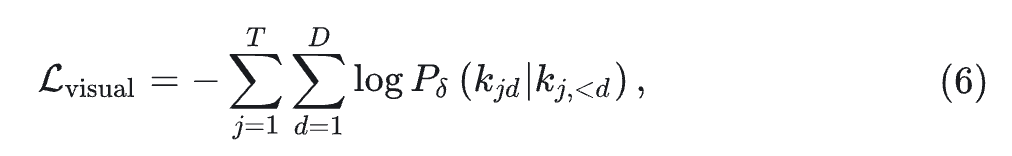
其中, 是多模态序列的总长度, 只计算 visual token 存在的位置。按照 RQ-VAE[2] 的做法使用一个 depth transformer 自回归地预测 个 residual tokens。
1.4 VILA-U 实验设置
语言模型:LLaMA-2-7B
视觉模型:SigLIP-Large-patch16-256 / SigLIP-SO400M-patch14-384
Residual Quantizer, depth transformer:按照 RQ-VAE 做法
Codebook 尺寸:16384
Image 尺寸:256×256 / 384×384
discrete 尺寸:16×16×4 / 27×27×16 (D = 4 / D = 16)
Unified Foundation Vision Tower 训练数据集:COYO-700M,评测数据集:ImageNet-1K Zero-Shot
训练数据:
多模态理解:ShareGPT4V 1M [image, text] 数据,MMC4 6M interleaved text image 数据,
视觉生成:内部 15M high-quality [text, image] 数据,OpenVid 1M [text, video] 数据
1.5 VILA-U 实验结果
Unified Foundation Vision Tower
图 3 展示了 ImageNet 上 Zero-Shot 图像分类 Top-1 精度以及重建 FID (rFID),以衡量模型的重建和文本对齐能力。模型实现了比 VQ-GAN 更好的重建结果。rFID 略逊于 RQ-VAE,这是意料之中的,因为在训练期间引入对比损失,目的是增强图像理解,但会导致重建质量下降。
 图3:ImageNet 上 Zero-Shot 图像分类的 Top-1精度和重建 FID (rFID)
图3:ImageNet 上 Zero-Shot 图像分类的 Top-1精度和重建 FID (rFID)多模态理解
图 4 和 5 分别总结了 VILA-U 在图像语言和视频语言基准上与其他 VLM 之间的比较。与 CLIP 等基础模型产生的 continuous 的视觉 token 的主流选择相比,基于 VQGAN 的 discrete 的视觉 token 与文本对齐较少,因此损害了 VLM 在视觉理解任务上的性能。通过本文的 unified foundation vision tower,即使使用 discrete 的视觉 token,VILA-U 也可以接近领先的 VLM 性能。
 图4:visual language benchmark 实验结果 (image)
图4:visual language benchmark 实验结果 (image)
 图5:visual language benchmark 实验结果 (video)
图5:visual language benchmark 实验结果 (video)视觉生成
如图 6 和 7 所示,VILA-U 可以实现比其他自回归方法更好的 FID,并且与一些基于扩散模型的方法相当的性能。图 7 展示了 GenAIBench 上和其他视觉生成方法的定量结果。尽管 VILA-U 不如在数十亿级图像-文本对上训练的基于扩散模型的方法,但 VILA-U 在高级提示上具有与 SD v2.1 和 SD-XL 相当的性能。这进一步表明,VILA-U 可以有效地有效地学习视觉和文本模态之间的相关性。
 图6:MJHQ-30K evaluation benchmark 实验结果
图6:MJHQ-30K evaluation benchmark 实验结果 图7:GenAI-Bench 实验结果
图7:GenAI-Bench 实验结果图 8 和 9 展示了 VILA-U 在一些视觉理解任务的示例。
 图8:VILA-U 可以正确字幕视频并涵盖所有细节
图8:VILA-U 可以正确字幕视频并涵盖所有细节
 图9:VILA-U具有良好的视觉问答能力
图9:VILA-U具有良好的视觉问答能力VILA-U 也继承了 VILA 的一些重要能力,包括多图像理解,如图 10 所示。
 图10:VILA-U 可以正确地对多个图像进行推理
图10:VILA-U 可以正确地对多个图像进行推理图 11 展示了 VILA-U 的视觉生成结果的示例。可以看到,VILA-U 可以用于图像生成和视频生成,即使使用相对较小的数据语料库进行训练。
 图11:VILA-U 可以在给定文本输入的情况下生成高质量的图像和视频
图11:VILA-U 可以在给定文本输入的情况下生成高质量的图像和视频参考
- Generative Pretraining in Multimodality
- Autoregressive Image Generation using Residual Quantization








