人工智能(机器学习、深度学习)做为现在的研究热点,很多跨学科的同学或主动或被动的需要学习了解这个领域,为了帮大家从零开始、循序渐进地了解机器学习与深度学习的发展脉络,小墨学长精心整理了从1958年的感知机到 2019 年 的GPT‑3共 13 篇里程碑式论文。
这13篇论文的pdf已经和我自己整理的人工智能零基础学习路线一起打包好了
大家可以直接添加小助手获取!
1958:Rosenblatt, F. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.”
提出了“感知机”模型,以生物神经元为灵感,用简单的加权和与阈值函数实现二分类,是首个可在线学习的神经网络,为后续神经网络研究奠定了理论和算法基础。

1986:Rumelhart, D. E., Hinton, G. E., & Williams, R. J. “Learning representations by back‑propagating errors.” Nature
系统化描述了反向传播算法,通过链式法则将误差逐层传递并更新权重,使多层神经网络的参数能够有效训练,解决了之前“深层网络难以训练”的瓶颈,开启深度学习的浪潮。

1995:Cortes, C. & Vapnik, V. “Support‑vector networks.” Machine Learning
提出支持向量机(SVM),通过最大化类别间隔构造最优超平面,并引入核方法可处理非线性可分数据,极大提升了分类器在小样本和高维空间下的泛化性能。

2001:Breiman, L. “Random Forests.” Machine Learning
提出了随机森林算法,通过在不同子样本和特征子集上训练多棵决策树并集成其预测结果,显著降低过拟合风险,同时在回归和分类任务中都展示出优异的稳定性和准确度。

2006:Hinton, G. E., Osindero, S., & Teh, Y.‑W. “A Fast Learning Algorithm for Deep Belief Nets.” Neural Computation
引入深度置信网络(DBN),将多层受限玻尔兹曼机堆叠并采用无监督贪心逐层预训练,再进行有监督微调,用层级化特征学习显著改善了当时深层模型的初始化与收敛。

2012:Krizhevsky, A., Sutskever, I., & Hinton, G. E. “ImageNet Classification with Deep Convolutional Neural Networks.” NIPS
AlexNet 首次在 ImageNet 大规模图像分类比赛中以远超第二名的错误率获胜,验证了深度卷积神经网络(CNN)在图像特征自动提取与模式识别方面的强大能力,并推动 GPU 加速培训。

2014:Goodfellow, I. et al. “Generative Adversarial Nets.” NIPS
提出生成对抗网络(GAN)框架,让生成器与判别器相互博弈式训练,可在无监督条件下生成高度逼真的样本,开启了生成模型研究新纪元,对图像、音频等领域产生深远影响。

2015:Mnih, V. et al. “Human‑level control through deep reinforcement learning.” Nature DQN:
将深度 Q‑网络(DQN)应用于 Atari 游戏,通过卷积网络学习原始像素输入并结合 Q‑learning,实现无需手工特征的端到端强化学习,首次在多款游戏中达到甚至超越人类水平。

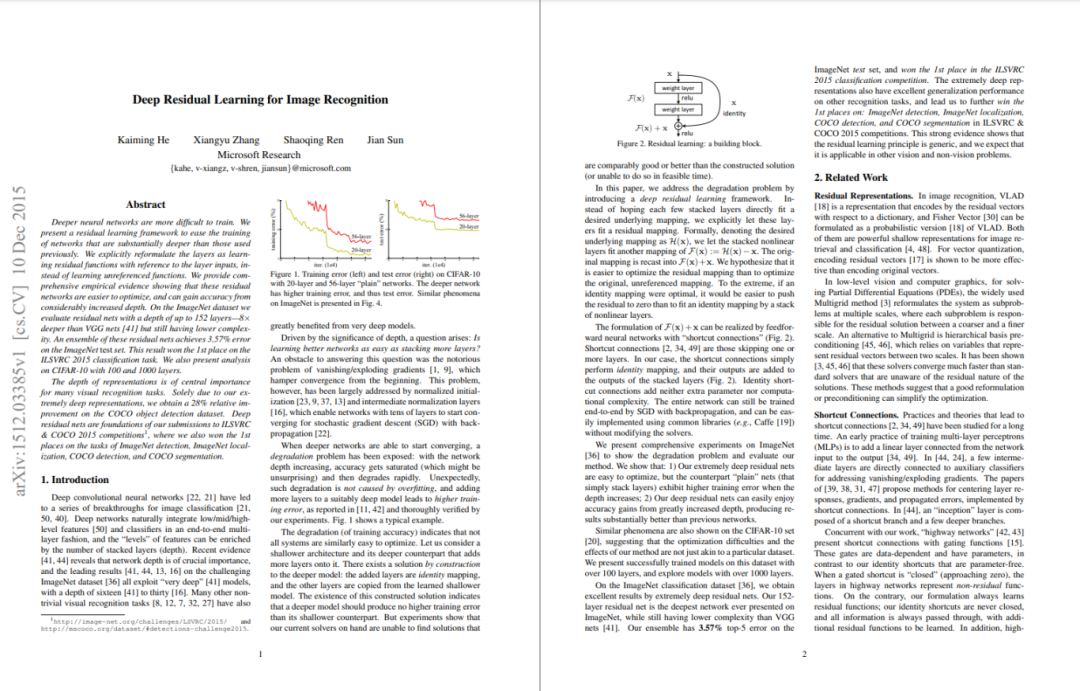
2015:He, K., Zhang, X., Ren, S., & Sun, J. “Deep Residual Learning for Image Recognition.” CVPR
引入残差块(Residual Block),通过“恒等映射+跳跃连接”解决了深层神经网络梯度消失与训练困难问题,使网络可扩展到数百层,提升了图像分类与检测任务的性能。
2016:Chen, T., & Guestrin, C. “XGBoost: A Scalable Tree Boosting System.” KDD
开发高效的梯度提升框架 XGBoost,采用二阶梯度优化、正则化控制和列抽样等技术,在大规模结构化数据竞赛和工业应用中极为普及,成为机器学习竞赛和生产环境的事实标准。

2017:Vaswani, A. et al. “Attention Is All You Need.” NIPS
提出Transformer架构,完全基于自注意力机制替代 RNN/CNN,实现并行化训练和长距离依赖建模,奠定了后续大规模预训练模型的设计基础。

2018:Devlin, J. et al. “BERT: Pre‑training of Deep Bidirectional Transformers for Language Understanding.” NAACL‑HLT
设计双向 Transformer 预训练策略(Masked Language Model + Next Sentence Prediction),在多项下游 NLP 任务上刷新性能,并开启了“预训练+微调”范式的广泛应用。

2019:Brown, T. B. et al. “Language Models are Few‑Shot Learners.” NeurIPS
GPT‑3 采用 1750 亿参数自回归 Transformer,展示了无需或仅需少量示例即可完成多种任务的惊人能力,证明了大模型规模对泛化与少样本学习的重要性。











