随着深度卷积网络现在成为大规模图像识别的首选架构,理解在CNN内部是如何区别捕捉图形信息变得尤为重要。
现有一个图像分类任务,给定一个训练好的卷积网络、一个图像I和一个感兴趣的类别c,我们希望从这个类别出发,探索它最感兴趣的特征。显著图是如何做的呢?
设 是卷积网络的分类层为图像I计算的对于类别c的分数。在训练完网络之后,我们先初始化I为零图像,接着,以
是卷积网络的分类层为图像I计算的对于类别c的分数。在训练完网络之后,我们先初始化I为零图像,接着,以 为目标函数,不断迭代I,直至收敛到最大值点。在这里加入L2正则项的原因是为了防止图像I的像素值一味增大忽略任务的要求。在训练完成之后,会得到每个类别的显著图,如下:
为目标函数,不断迭代I,直至收敛到最大值点。在这里加入L2正则项的原因是为了防止图像I的像素值一味增大忽略任务的要求。在训练完成之后,会得到每个类别的显著图,如下:


单单得到每个类目的显著图是不够的,我们还想要知道,对于每一个样本,模型将其判断为某一个类别或不判断为另一个类别的原因。给定图像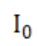 、类别c和针对类别c的分数函数
、类别c和针对类别c的分数函数 的卷积神经网络,我们希望根据像素对
的卷积神经网络,我们希望根据像素对 分数的影响对的像素进行排序。
分数的影响对的像素进行排序。
从例子开始,考虑类别c的线性分数模型: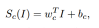 ,其中图像I以向形式表示,
,其中图像I以向形式表示,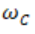 和
和 分别是模型的权重向量和偏差。在这种情况下,很容易看出元素
分别是模型的权重向量和偏差。在这种情况下,很容易看出元素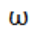 的大小定义了I中相应像素对类别c的重要性。
的大小定义了I中相应像素对类别c的重要性。
然而,在卷积神经网络中,类别分数是I的高度非线性函数,因此上一段的推理不能立即应用,我们需要先利用泰勒展开对他进行一阶展开,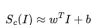 ,其中,
,其中, 。
。
1. 基于原型层的事后解释方法
对于一个黑箱,他的这些参数是怎么来的呢?不难发现,都是通过训练集数据加之以反向求导更新迭代而来的。一个自然而然的问题就是,我们能否在训练数据这个层面去解释这个黑箱呢?问题就自然而然地变为了, 哪些训练点对这个预测是影响最大的?我们想知道,去掉哪个点,对的改变最大?如果我们把某个数据乘以权重,结果会如何变化?
把这个问题量化,设原先的 是由目标函数
是由目标函数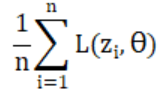 ,现在,我们把某一个数据点z的损失函数前面的权重拉大
,现在,我们把某一个数据点z的损失函数前面的权重拉大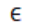 ,那么,现在的损失函数为
,那么,现在的损失函数为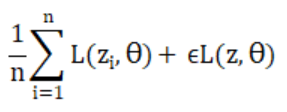 ,我们想知道的是,在拉大这个权重之和,模型在测试集上面的改变会有多少?即
,我们想知道的是,在拉大这个权重之和,模型在测试集上面的改变会有多少?即 。为了解决上面那个问题(哪些训练点对这个预测是影响最大的),我们必须要去固定为
。为了解决上面那个问题(哪些训练点对这个预测是影响最大的),我们必须要去固定为 ,去遍历训练集上面的所有的点,训练一个新的网络,那么,一共需要训练n次网络,这是一个很麻烦的过程,我们应该去尽量避免,对此,Pang Wei Koh提出了用影响函数去解决这个问题。
,去遍历训练集上面的所有的点,训练一个新的网络,那么,一共需要训练n次网络,这是一个很麻烦的过程,我们应该去尽量避免,对此,Pang Wei Koh提出了用影响函数去解决这个问题。
1.1. 增加训练点权重对损失的影响函数
我们想知道的是,当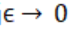 时,
时, 如何变化?Cook & Weisberg先前提出,增加z的权重对模型参数的影响由下式给出:
如何变化?Cook & Weisberg先前提出,增加z的权重对模型参数的影响由下式给出:
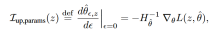
其中,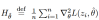 是海瑟矩阵(并假定它正定),接着,考虑增加z的权重对测试点
是海瑟矩阵(并假定它正定),接着,考虑增加z的权重对测试点 的损失的影响,有:
的损失的影响,有:
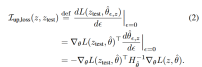
1.2. 训练输入扰动对损失的影响函数
假设我们不是增加训练点的权重,而是通过一个小量扰动 训练输入x,即我们考虑
训练输入x,即我们考虑 。我们将从z移动到
。我们将从z移动到 ,新的参数估计值为:
,新的参数估计值为:
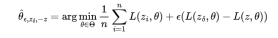
增加的权重(同时减少z的权重)对参数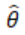 的影响由下式给出:
的影响由下式给出:
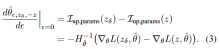
如果x是连续的并且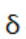 很小,我们可以进一步近似为:
很小,我们可以进一步近似为:
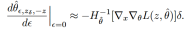
接下来,我们考虑这种扰动对测试点 的损失的影响。通过链式法则,我们有:
的损失的影响。通过链式法则,我们有:
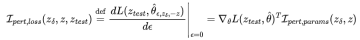
代入的表达式,我们得到:
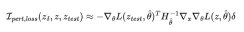
如果我们令指向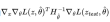 的方向,那么
的方向,那么 将达到最大值。
将达到最大值。
在计算影响函数时,我们通常会碰到三个问题:Computational efficiency、Smoothness、Finding the ERM.
我们想要计算影响函数则必须要计算黑塞矩阵的逆,然而对于大规模数据集和复杂模型,这通常非常耗时的操作。为了解决这个问题,我们不直接计算矩阵的逆,取而代之的是,先利用Pearlmutter trick计算海瑟矩阵与v(loss的梯度)的点乘,这个过程基本是在线性时间内完成的。然后再用共轭梯度法或泰勒展开去近似计算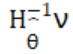 。这个过程避免了显式地计算海森矩阵,大大降低了计算复杂度和内存需求。
。这个过程避免了显式地计算海森矩阵,大大降低了计算复杂度和内存需求。

如果损失函数在某处不可微呢?我们MNIST 任务上训练了一个SVM模型。SVM 的损失函数涉及到 hinge 损失Hinge(s)=max(0,1-s),这是一个分段线性函数,会导致不可微性。我们将 hinge 处的导数设置为 0 并计算 。结果不准确,二阶导数无法提供关于支持向量z与 hinge 的接近程度的信息,因此的二次近似是线性的,这导致高估了z的影响。
。结果不准确,二阶导数无法提供关于支持向量z与 hinge 的接近程度的信息,因此的二次近似是线性的,这导致高估了z的影响。

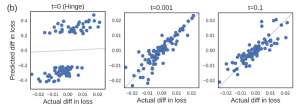
那如何去解决这个问题呢?一个常见的的思想是找到一个平滑的函数去代替原先的hinge函数,我们用 函数来近似,并分别设置t=0.1和0.001来比较预测值与真实值的差异,结果如下图,在用SmoothHinge替代Hinge之后,预测结果好了很多。
函数来近似,并分别设置t=0.1和0.001来比较预测值与真实值的差异,结果如下图,在用SmoothHinge替代Hinge之后,预测结果好了很多。
我们的分析都是基于找到了一个全局最优解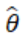 ,然而,在大多数情况下, 函数是非凸的,导致它不一定会收敛到全局最小值上。假如影响函数收敛到了局部最小值上面,应该如何处理呢?这里的核心思想是:从找到的局部最小值开始重新训练模型,分析影响函数与真实值之间的大小关系。
,然而,在大多数情况下, 函数是非凸的,导致它不一定会收敛到全局最小值上。假如影响函数收敛到了局部最小值上面,应该如何处理呢?这里的核心思想是:从找到的局部最小值开始重新训练模型,分析影响函数与真实值之间的大小关系。

结果发现,尽管模型处于非收敛且非凸的困难设置下,但令人惊讶的是,预测的损失变化和实际的损失变化仍然高度相关。这说明影响函数在实际复杂的训练场景中(如非凸优化和非收敛情况)具有一定的鲁棒性。
2. 反事实解释
在现实情境中,借贷公司常作出如下表述:“鉴于您的年收入仅为 30000 元,本公司将不予提供贷款;若您的年收入达 45000 元,本公司则会考虑放款。”此论述具有反事实属性,即探讨被观测个体应如何进行改变,以促使期望结果的达成。
反事实情形通常具有多元性特征。就该实例而言,欲使借贷公司的决策由拒绝转变为接受,并非仅能通过提升年收入这一途径实现,学历、住房面积、年龄等因素的变动亦可能产生相同效果。
我们也可以通过考虑反事实中主体属性的变化对决策的影响来评估算法是否公平。同样在这个例子中,假如我们发现一个反事实情况:如果一个少数族裔申请人的种族属性被改变为多数族裔(其他条件不变),其贷款申请就会被批准。那么,这个算法存在潜在的不公平性,因为它对种族这一变量存在明显的依赖。
在这个情形下,若年收入提升至 50000 元,无疑亦会致使决策发生改变。然而,在一般情形下,人们往往倾向于探寻达成模型决策改变所需的最小变动,即通过最易于实现的目标改变来影响目标值。
Sandra Wachter首次提出了反事实解释,在他的理论中,我们需要在保证目标决策会改变的情况下最小化距离度量,则将该问题转化成了一个带约束的最小化问题,如下:

对于带约束的优化问题,常见的思路是将其转化成无约束优化问题来求解,因此,原式被转化为:
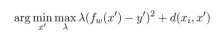
这个公式的目标是找到一个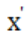 ,使得在最大化
,使得在最大化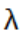 的情况下,表达式
的情况下,表达式 的值最小。表达式中的
的值最小。表达式中的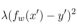 部分通常用于衡量预测值
部分通常用于衡量预测值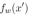 与目标值
与目标值 之间的差异,并且通过来调节这个差异的权重。
之间的差异,并且通过来调节这个差异的权重。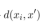 部分则用于衡量
与另一个数据点
部分则用于衡量
与另一个数据点 之间的距离。
之间的距离。
其中,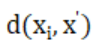 的计算公式如下:
的计算公式如下:
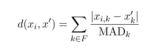
其中,分子为曼哈顿距离,分母为:
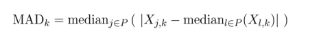
L1 范数加权逆中位数绝对偏差具有捕捉数据空间内在波动性、对异常值更稳健和诱导稀疏解等优点,使反事实解释更易于理解和传达。具体来说,如果一个特征在数据集中变化很大(即较大),那么在计算距离时,该特征的权重相对较小;反之,如果一个特征变化较小(较小),其权重相对较大。
在机器学习文献中,生成反事实解释的技术与 “对抗性扰动” 密切相关。对抗性扰动是指通过计算使现有分类器产生不同分类结果的合成数据点。反事实解释在尝试寻找一种改变,使得决策结果发生改变,这和对抗性扰动的思路是相似的。在当前对抗性扰动的相关研究中,针对距离函数的选取存在一定缺陷。具体而言,现有的对抗性扰动往往倾向于多变量出现小幅度变化的情况,而并非聚焦于生成那些稀疏的、便于人类理解的解决方案。然而,对于反事实解释来说,距离函数的选择起着至关重要的作用,因为不同的距离函数会引导出不一样的反事实解释结果。
回到上文提及的反事实情况:如果一个少数族裔申请人的种族属性被改变为多数族裔(其他条件不变),其贷款申请就会被批准。但是,人的种族是很难更改的,尽管两向量之间的距离相比于修改其他因素的值要小。同时,为了得到更可行的解释,我们在做扰动的时候,应该只在可行域内进行。
在BERK USTUN的研究中,用损失函数cost替代距离d,并且将扰动之后的向量约束在可行域范围内。即:
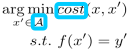
这个公式的目的是在因果可行的反事实集合A中,找到一个x’,使得它与x的成本(cost(x,x’))最小,同时满足f(x’)=y’,即经过函数f作用后得到目标值y’。
这里A是根据给定的结构因果模型(SCM)所允许的因果可行反事实的集合。
但是,如果我们无法获取结构因果模型会怎样?这意味着在实际操作中,如果没有结构因果模型A来确定反事实的可行性集合,那么上述的优化问题就无法直接求解。因为A是依赖于结构因果模型的,没有它就无法确定哪些反事实是因果可行的。
为解决这个问题,Sahil Verma提出构建变分自编码器来将输入实例映射到潜在空间,在潜在空间中搜索反事实之后,使用解码器将其映射回输入空间。数据在高维空间中往往集中在一个低维流形上,反事实也应该在这个数据所在的流形上才有意义。与此同时,在潜在空间中进行搜索可能更容易,因为潜在空间通常具有更低的维度,且数据在潜在空间中的分布可能更规则。在找到潜在空间中的反事实后,需要通过解码器将其转换回原始的数据输入空间,这样就能得到在原始数据空间中有意义的反事实。
不妨看下面这张图:
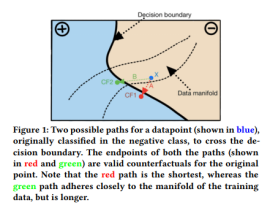
对蓝色的点X进行反事实操作,即使红色的点CF1与X更近,然而由于它不处于数据流型之中,模型会更倾向于用绿色的点CF2来进行解释。
在CNN内部,基于原型层的事后解释和反事实解释是两种基本的解释方法,在后续文章中将进一步详细解读机器学习模型的可解释性。










