👇 连享会 · 推文导航 | www.lianxh.cn

🍓 课程推荐:连享会:2025社会网络分析·线上
嘉宾:杨张博,西安交通大学
时间:2025 年 7 月 30-31 日
咨询:王老师 18903405450(微信)

温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:
作者: 连玉君 (中山大学)
邮箱:arlionn@163.com
本文写作过程中借助了 AI 工具:ChatGPT,豆包
1. 背景:你看到的网址,不一定能直接下载
在数据分析中,我们经常需要从网页上获取文件,比如:
但你可能遇到这样令人抓狂的报错:
HTTP error 403File not foundCannot open URL
这些错误,往往不是你代码写错了,而是踩到了 网页跳转(redirect) 的坑:你访问的网址其实只是 “入口”,背后被 网页跳转(redirect) 指向了另一个真正的地址。
类比:你收藏了图书馆旧网址,结果它早搬家了
你打开旧链接,看到的是个跳转页面: “我们的网站已迁移,3 秒后自动跳转至新地址”, 浏览器很听话,自动替你跳过去。 但程序(尤其是爬虫和下载命令)若没有开启“自动跳转”,就会卡在旧页面。
这些看似简单的跳转行为,是造成程序抓取失败的常见原因之一。 接下来,我们将通过具体例子,解释网页跳转的工作原理,并提供在 Stata、R 和 Python 中应对这些跳转的实用方案。
2. 网页跳转:你看到的不是你拿到的
网页跳转是服务器告诉客户端“你应该去另一个地址”,浏览器会自动跳过去,但程序不一定跟跳。
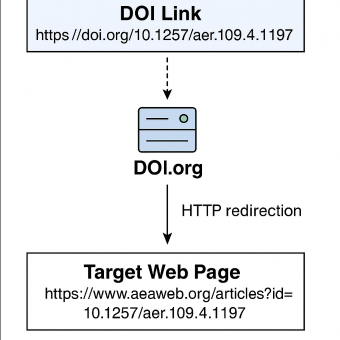
例 1:DOI 链接跳转
在论文引用中,我们常常看到形如 https://doi.org/{DOI} 的链接,例如:
URL1:https://doi.org/10.1257/aer.109.4.1197
但当你点击该链接时,浏览器中实际显示的网址往往是:
URL2:https://www.aeaweb.org/articles?id=10.1257/aer.109.4.1197
这是因为 DOI 系统一开始并不指向论文所在网站,而是将所有文献的入口统一托管在 doi.org。这个网站本身并不存储论文内容,而是作为一个 标准化的跳转服务,根据 DOI 查询注册信息,再将用户跳转到对应出版社的网页。
这种跳转一般通过 HTTP 301(永久跳转)或 HTTP 302(临时跳转)实现。 浏览器会自动跟随跳转,但程序或爬虫若未开启跳转功能,就无法获取真实的 PDF 或页面地址。
这一机制也被广泛应用于 SSRN、arXiv、Nature、Science 等期刊和论文平台,统一管理引用链接与实际访问路径。
下图展示了整个 DOI 跳转的过程:
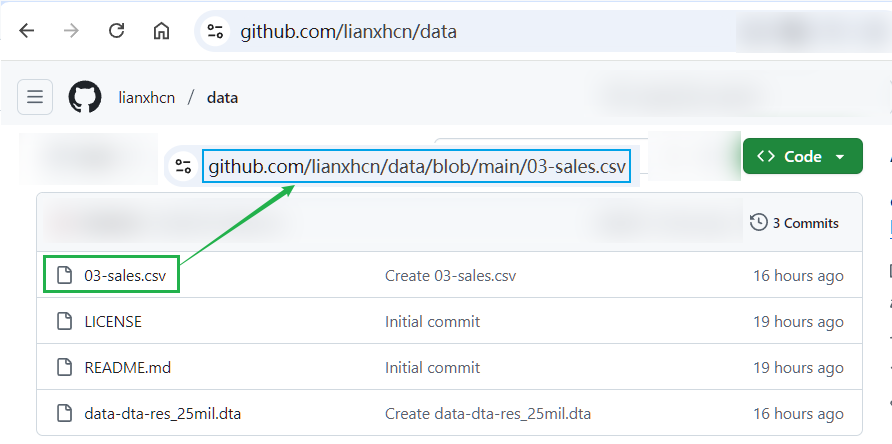
例 2:GitHub 网页跳转
以 github 仓库 lianxhcn/data 中的 03-sales.csv 文件为例,你看到的文件链接是:
# Link00
https://github.com/lianxhcn/data/blob/main/03-sales.csv
这个地址其实是网页地址 (用于展示文件概况),不是文件下载地址。
进入 03-sales.csv 的浏览页后,有些人会 右击 该页面的 Raw 按钮 → **复制链接地址 (E)**,得到如下网址:
# Link01
https://github.com/lianxhcn/data/raw/refs/heads/main/03-sales.csv
或者根据 github 的说明文档,使用如下网址:
# Link02
https://github.com/lianxhcn/data/blob/main/03-sales.csv?raw=true
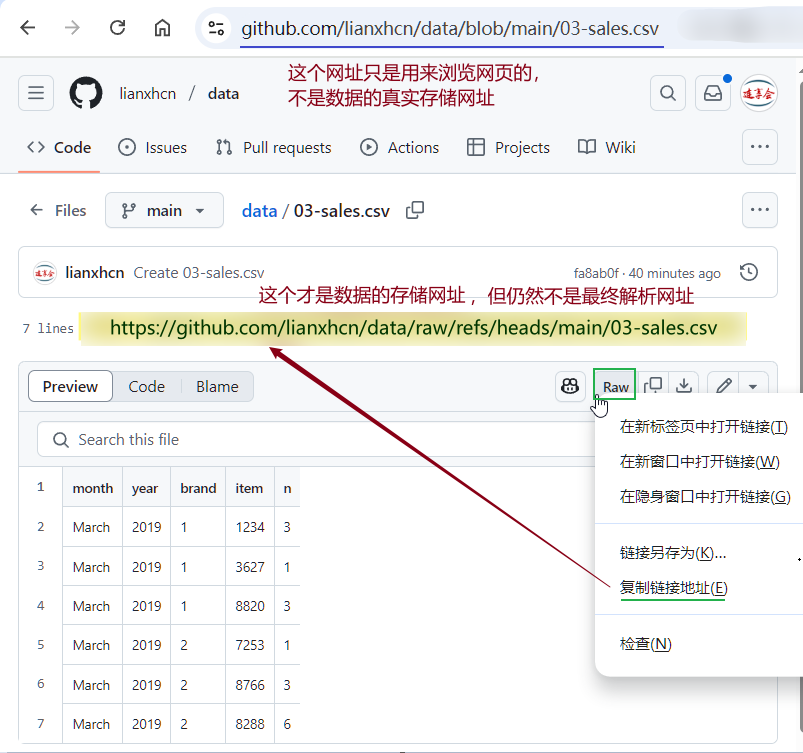
上述 Link01 和 Link02 虽然在多数情况下都可以用于下载数据,但也都是 二次跳转地址,它们最终都会跳转到文件下载地址 (唯一地址,可以单击 Raw 按钮后,在地址栏中看到):
# Link_final
https://raw.githubusercontent.com/lianxhcn/data/main/03-sales.csv
因此,在编写程序进行大规模数据下载时:
-
- 使用
Link01 / Link02 则缺乏稳定性,因为有些程序 (如 Stata 中的 copy,use 等命令) 不具备跳转功能;同时,二次定向规则发生变化时,这些中间网址也会失效。 - 使用
Link_final 是最安全可靠的方式,因为它是 唯一的文件下载地址,不会发生跳转。
3. 如何判断一个网址是否会跳转?
方法 1:浏览器观察法
方法 2:开发者工具法
- 打开网页 → F12 → Network → 刷新页面;
- 查找是否出现 3xx 状态码和
Location: 字段。
方法 3:使用命令行工具 curl 或
wget
curl -I https://github.com/lianxhcn/data/blob/main/03-sales.csv
输出:
HTTP/1.1 302 Found
Location: https://raw.githubusercontent.com/...
说明该链接发生了跳转。
加上 -L 参数即可跟踪跳转:
curl -L -o sales.csv https://github.com/lianxhcn/data/blob/main/03-sales.csv
4. Stata / R / Python 中如何处理跳转?
不同的编程工具在处理网页跳转时表现不同。有些工具(如 Python 的 requests、R 的 httr 包)默认支持自动跟踪跳转,能够顺利获取最终资源。而另一些工具(如 Stata 的
import delimited、copy 命令)则不支持自动跳转,直接访问含跳转的网址时可能失败。此时,推荐结合外部工具(如 curl),先下载文件到本地,再用目标程序进行数据导入。这样可以有效应对跳转带来的下载障碍,提高数据获取的稳定性和成功率。
| | | |
|---|
| requests | | |
| httr::GET() |
| res$url |
| curl | | curl -I |
| import delimited | | |
Python 示例
import requests
url = "https://github.com/lianxhcn/data/blob/main/03-sales.csv?raw=true"
res = requests.get(url, allow_redirects=True)
print(res.url) # 会跳转到 raw.githubusercontent.com 的真实地址
注意,填写
url 时,务必添加 ?raw=true 参数,否则跳转机制无法生效。
因此,采用如下写法会更好一些:
url_html = "https://github.com/lianxhcn/data/blob/main/03-sales.csv"
url = url_html + "?raw=true"
res = requests.get(url, allow_redirects=True)
有关 Python 中如何处理跳转的更多细节,可以参考 requests 文档。
R 示例
library(httr)
url_html "https://github.com/lianxhcn/data/blob/main/03-sales.csv"
url "?raw=true")
res
res$url # 跳转后的真实地址
有关 R 中如何处理跳转的更多细节,可以参考 httr 文档 和 GET 文档。
Stata 示例
* 使用 curl 下载后再导入
local url_html "https://github.com/lianxhcn/data/blob/main/03-sales.csv"
local url "`url_html'?raw=true"
shell curl -L -o sales.csv "`url'"
import delimited using "sales.csv", clear // 导入 Stata
此处,我们使用了 Stata 的
[D] shell 命令调用 DOS 命令 curl 来处理跳转。详情参见如下推文:
- 严子凯, 2022, Stata-DOS:事半功倍的DOS命令汇总, 连享会 No.1047.
- Will Matsuoka, 2016, Stata and cURL, Link
5. 进阶阅读
对于希望深入了解网页跳转及其在数据抓取中的应用,以下是一些有价值的参考资料。
首先,理解 HTTP 状态码 是基础,常见的跳转状态码如 301(永久跳转)和 302(临时跳转)对网站行为影响深远。你可以在 MDN Web Docs 中找到详细的解释。
对于爬虫开发者,requests 和
curl 是最常用的工具,相关文档提供了如何使用它们来处理跳转。requests 的使用方法请参考 requests 文档,而 curl 的详细手册可以在 curl: Manual 找到。
此外,DOI 跳转机制在学术文献访问中非常重要,你可以通过 DOI.org 和 CrossRef 了解更多相关信息。
如果你遇到复杂的跳转链,如何跟踪每次跳转并获取最终 URL,Stack Overflow 上的 Redirect Loops 讨论提供了解决方案。
最后,学习如何解决验证码和动态内容等挑战,Scrapy 的 Documentation 是一个很好的资源,适合更复杂的爬虫任务。
6. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh lianxh dos 爬, md nocat
安装最新版 lianxh 命令:
ssc install lianxh, replace
- 严子凯, 2022, Stata-DOS:事半功倍的DOS命令汇总, 连享会 No.1047.
- 修博文, 2024, 爬取政府工作报告文本-Python, 连享会 No.1354.
- 初虹, 2022, Python爬虫1:小白系列之requests和json, 连享会 No.887.
- 初虹, 2022, Python爬虫2:小白系列之requests和lxml, 连享会 No.888.
- 吴浩然, 2024, 数据爬取:美国证监会EDGAR系统数据获取及Python实现, 连享会 No.1329.
- 周豪波, 2020, Python 调用 API 爬取百度 POI 数据小贴士——坐标转换、数据清洗与 ArcGIS 可视化, 连享会 No.20.
- 孙斯嘉, 2020, Python 调用 API 爬取百度 POI 数据, 连享会 No.60.
- 左从江, 2020, Python: 批量爬取下载中国知网(CNKI) PDF论文, 连享会 No.54.
- 李岸瑶, 2021, Stata爬虫:爬取地区宏观数据, 连享会 No.684.
- 李岸瑶, 2021, Stata爬虫:爬取A股公司基本信息, 连享会 No.685.
- 李青塬, 2022, Stata+Python:同花顺里爬取创历史新高的股票, 连享会 No.957.
- 李青塬, 2022, Stata+Python:爬取创历史新高股票列表, 连享会 No.894.
- 梁海, 2020, Python:爬取东方财富股吧评论进行情感分析, 连享会 No.440.
- 游万海, 2020, Stata爬虫-正则表达式:爬取必胜客, 连享会 No.287.
- 王文韬, 2020, Python爬虫: 《经济研究》研究热点和主题分析, 连享会 No.88.
- 王颖, 2022, Python爬取静态网站:以历史天气为例, 连享会 No.921.
- 王颖, 2022, Python:多进程、多线程及其爬虫应用, 连享会 No.935.
- 王颖, 2022, Python:爬取动态网站, 连享会 No.932.
- 秦利宾, 2020, Python:爬取上市公司公告-Wind-CSMAR, 连享会 No.131.
- 秦利宾, 2021, Python:爬取巨潮网公告, 连享会 No.646.
- 秦利宾, 许梦洁, 2021, Python+Stata:如何获取中国气象历史数据, 连享会 No.793.
- 范思妤, 2023, Python:基于selenium爬取科创板审核问询, 连享会 No.1172.
- 许梦洁, 2020, Python: 6 小时爬完上交所和深交所的年报问询函, 连享会 No.104.
- 许梦洁, 2021, Python爬虫:从SEC-EDGAR爬取股东治理数据-Shareholder-Activism, 连享会 No.744.
- 许梦洁, 2021, Python爬虫:爬取华尔街日报的全部历史文章并翻译, 连享会 No.743.
- 连享会, 2022, 连享会:助教入选通知-2022文本分析与爬虫, 连享会 No.908.
- 陈卓然, 2023, Python:爬虫雅虎财经数据-selenium, 连享会 No.1306.
- 陈波, 郑静怡, 江鑫, 2021, 在Stata里点首歌吧:imusic, 连享会 No.666.
🍓 课程推荐:连享会:2025暑期班·网络直播
嘉宾:连玉君 (初级+高级) || 张宏亮 (论文班)
时间:2025 年 8 月 4-14 日
咨询:王老师 18903405450(微信)
连享会微信小店上线啦!
Note:扫一扫进入“连享会微信小店”,你想学的课程在这里······
New! Stata 搜索神器:lianxh 和
songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
👉 安装:
. ssc install lianxh
. ssc install songbl
👉 使用:
. lianxh DID 倍分法
. songbl all
🍏 关于我们
- 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。












