▲第一作者:鲍闰杰
通讯作者:杨庆春
通讯单位:合肥工业大学
论文DOI:10.1021/acscatal.5c02227(点击文末「阅读原文」,直达链接)
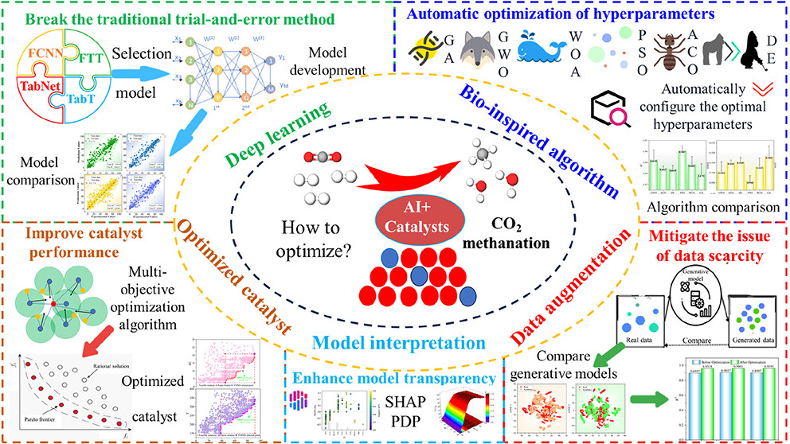
 全文速览
全文速览为解决CO2甲烷化催化剂设计中传统方法和深度学习的局限,本研究提出双驱动深度学习(BODAL)策略,该策略利用粒子群优化(PSO)算法自适应配置超参数,并采用表格变分自编码器(TVAE)进行数据增强,显著提升了FT-Transformer (FTT) 模型的预测精度(测试集R2达
0.9591)。通过可解释性分析揭示了关键变量的贡献。此外,优化后的FTT模型结合多目标粒子群优化算法(MOPSO)成功优化了Ni/Al2O3催化剂,并预测了六种新型高效镍基催化剂。
![]()
![]()
背景介绍随着全球能源消耗的指数级增长,化石燃料的持续大规模使用已将大气CO2浓度推高至突破450 ppm的警戒线。迫切需要找到一种高效且有效的策略,以实现从化石燃料向可再生能源的转型,从而降低CO2浓度。如图1(a)所示,甲烷作为一种关键的碳载体,支撑着从制氢到化工生产等重要的工业过程。将CO2和可再生H2转化为甲烷提供了一个双重解决方案:每年吸收36亿吨工业排放,并生产高能量密度燃料(55.5 MJ/kg)。随着全球CO
2排放的不断升级,这项甲烷化技术展现出巨大的市场潜力和经济价值,使其成为实现碳中和与能源可持续发展的战略途径。
然而,由于C=O键的解离能高(约750 kJ/mol),CO2的活化困难,转化率较低。因此,CO2甲烷化反应大规模工业应用的关键在于开发具有高活性和高选择性的新型催化剂。以往基于传统试错实验方法的研究发现,Ru、Pd、Rh等贵金属催化剂在CO2加氢制CH4方面表现出优异的催化性能,但其高昂的成本限制了其广泛应用。相比之下,一系列过渡金属(如Co和Ni)因其成本优势以及相对较高的转化率和产率,被认为是CO2甲烷化反应更理想的催化剂。然而,如图1(b)所示,这些基于传统实验方法的研究严重依赖研究人员的化学直觉或经验。这不仅消耗大量时间和精力,而且在广阔的化学优化空间中难以确定CO2甲烷化的最佳催化剂。为实现CO2甲烷化催化剂的高效开发,必须突破传统试错方法在这一复杂多变量系统中的局限性。深度学习(DL)能够高效分析高维数据和复杂的结构-
性能关系,从而促进对大量候选材料的快速筛选,并实现对催化活性和稳定性的精确预测。因此,它为超越经验限制和设计高性能催化剂提供了一种新范式。
图1. CO2转化为CH4的循环路径 (a) 及其现有研究不足 (b)
本文亮点
(1) 本研究创新性地提出了双驱动深度学习(BODAL)策略,旨在克服传统试错法和现有深度学习在CO2甲烷化催化剂设计中的局限。该策略核心在于利用仿生优化算法进行超参数的自适应配置,并经过系统比较,确定粒子群优化(PSO)算法为最有效的超参数优化工具。同时,FT-Transformer (FTT) 模型被识别为CO2转化率和CH
4产率预测的最佳深度学习模型,为高精度预测奠定基础。
(2) 针对小样本数据限制,本研究引入并验证了表格变分自编码器(TVAE)作为最优的数据增强策略。与多种GAN基策略相比,TVAE在特征分布和相似性方面表现出显著优势,有效缓解了数据不足的瓶颈。通过TVAE增强数据,优化后的FTT模型在测试集上的R2显著提升至0.9591,展现出卓越的预测性能。
(3) 本文不仅关注预测精度,更强调模型的可解释性。通过SHAP进行特征重要性分析,明确揭示了反应温度、载体和助剂类型是影响CO2甲烷化反应性能的关键因素。结合部分依赖图,进一步阐明了不同特征间的复杂相互作用,特别是温度对转化率和产率的显著调控机制,为催化剂设计提供了深刻的理论指导。
(4) 将优化后的FTT模型与多目标粒子群优化(MOPSO)算法无缝集成,实现了CO2甲烷化催化剂的智能设计与优化。该集成框架成功优化了广泛使用的Ni/Al2O3
催化剂的活性组分含量和反应温度。更重要的是,它指导了全局范围的新催化剂筛选,成功预测并获得了六种具有前景的新型镍基催化剂。
图文解析图2. BODAL框架:用于CO2甲烷化反应催化剂的高效准确优化和筛选
要点:该框架将仿生优化算法与深度学习相结合,构建了自适应超参数配置和数据增强的双驱动策略。其主要包括以下六个步骤: 1、数据集构建与预处理:系统地从已发表文献中整理了一个多维CO2甲烷化催化剂数据集,其中包含催化剂性质、制备条件和反应参数。利用皮尔逊相关系数、互信息度量和可视化技术进行特征分析,以量化线性特征关系并揭示非线性依赖。此外,还进行了特征编码和数据标准化等数据预处理步骤,以促进后续模型训练;2、初始深度学习模型开发:构建了四种不同的深度学习架构,并使用均方根误差(RMSE)和决定系数(R2)指标进行严格评估,以识别性能最佳的模型;3、最优仿生算法识别:实施并比较评估了六种仿生优化算法,以自动化识别CO2甲烷化反应深度学习模型的最佳超参数;4、生成式数据增强策略确定:评估并比较了四种基于生成模型策略的数据生成能力,以优化它们在生成CO2
甲烷化反应相关数据方面的性能。通过迭代增强策略,本研究实施了定量基准指标来选择最优的生成架构,从而通过连续的增强循环逐步提高核心预测模型的准确性;5、可解释性分析:采用SHAP(SHapley Additive exPlanations)和PDP(Partial Dependence Plots)分析,从全局和局部角度深入研究CO2甲烷化反应的优选深度学习模型,从而探索关键输入特征对反应输出的影响;6、多目标优化:将最优深度学习模型与多目标优化算法相结合,以进一步优化已报道的CO2甲烷化反应催化剂。此外,该方法还能在整个化学优化空间内识别具有优异催化性能的潜在催化剂候选物。
图3. 用于优化CO2甲烷化反应深度学习模型超参数的六种仿生算法
要点:仿生算法模仿生物进化或群体智能行为,通过迭代种群更新(如选择、交叉和变异)或自适应调整粒子位置,实现全局探索和局部开发之间的动态平衡。与传统方法相比,仿生算法能够以更少的试验次数逼近最优解,并且特别擅长处理高维、非线性、多峰值的复杂优化问题。它们显著提高了有限计算资源下的参数调优效率,为深度学习模型的有效部署提供了可靠支持。
图4.
开发数据增强策略以提升深度学习模型性能: (a)VAEs 和(b) GANs基本架构;(c)数据增强策略及其(d)评估指标;(e)基于生成式深度模型的数据增强流程
要点:生成对抗网络(GANs)和变分自编码器(VAEs)作为两种主流的深度生成模型,通过不同的机制实现数据生成目标,同时保持原始数据的统计特性和结构特征。这两种生成式数据增强方法的基本原理如图4(a)和(b)所示。考虑到CO2甲烷化数据集的特点,为识别最适合CO2甲烷化反应的数据生成模型,本研究从多维度视角对TGAN、CTGAN、CopulaGAN和TVAE模型的数据生成能力进行了比较分析。如图4(d)所示,采用Jensen-Shannon散度(JSD)和平均绝对相关误差(MACE
)评估指标来量化生成数据与真实数据之间的分布相似性和相关性差异;另一方面,利用皮尔逊相关系数热图和t-SNE可视化工具对生成数据的质量进行视觉分析。通过整合这些指标和可视化技术,实现了对四种生成模型性能的全面评估。
图5. 已构建的CO2甲烷化数据集中主要参数的可视化:(a) 催化剂性质的分类变量;(b) 催化剂性质的数值变量
图6. CO2甲烷化反应制备条件数值特征的分布图
要点:本研究对收集到的CO2制CH4镍基催化剂数据集进行了深入的统计分析,包括可视化分析、皮尔逊相关系数和互信息的计算。这些步骤能够更全面地了解CO2加氢制
CH4过程中各种参数的详细信息。
图7. CO2甲烷化反应输入特征相关性度量比较:(a)皮尔逊相关系数结果和(b)互信息结果
要点:利用皮尔逊相关系数评估数值特征的线性关联,并采用互信息方法分析特征与目标变量的非线性依赖关系(图7(a)和(b))。结果显示,多数特征线性相关性较弱(绝对值<0.4)。但比表面积与孔体积呈强正相关,活性组分含量与载体含量则呈强负相关。互信息分析表明,温度是影响CO2甲烷化反应输出的最重要特征,其非线性关联显著强于其他特征。所有输入特征均与CO2转化率和CH4产率存在不可忽略的潜在关联。
图
8. 不同仿生优化算法优化后的2层FCNN模型验证集性能比较:(a) R2;(b) RMSE;(c) MAE;(d)运行时间
要点:为了对六种仿生优化算法进行全面分析和比较,每种算法都设置了相同的种群大小(= 20)和迭代次数(= 100),并执行了五次。为了确保公平比较并消除模型复杂性的影响,使用具有两个隐藏层和十个隐藏层的FCNN模型作为基准。此外,将随机搜索(RS)作为基准算法进行比较。结果表明,PSO算法的四个评估指标的标准差都相对较小,且其效率最佳,这表明该算法的全局搜索能力有助于在不同初始条件下找到每个超参数的最优解,并减少结果的波动。
图9. 各种深度学习模型在测试集上的性能比较:(a)迭代曲线;(b) R2;(c)RMSE
;(d)MAE
图10. CO2甲烷化反应中不同深度学习模型对CO2转化率 (a, c, e, g) 和CH4产率 (b, d, f, h) 的散点拟合图:(a)-(b) TabNet;(c)-(d) FCNN;(e)-(f) TabT;(g)-(h) FTT
要点:如图9(a)所示,采用最优算法的粒子群优化(PSO)算法系统地优化每个模型的超参数,各模型的迭代收敛曲线显示,它们在大约40代后逐渐达到稳定状态,目标函数值趋于稳定。这表明优化过程基本收敛到最优解附近。这进一步验证了PSO算法具有良好的收敛性能和优化效率。如图
9(b)-(d)所示,通过测试集R2、RMSE和MAE,评估和比较了四种自动优化后的深度学习模型的预测性能。结果表明,FTT在所有指标上均优于其他三个模型,在测试集上实现了0.8997的R2、0.0988的RMSE和0.0566的MAE。此外,如图10(a)-(h)所示,通过拟合散点图进一步深入直观地比较了各模型在CO2转化率和CH4产率上的拟合结果。FTT模型对CO2甲烷化反应的CO2转化率和CH4产率具有最佳的拟合能力。大多数数据点紧密分布并接近拟合曲线,测试集R2值分别为0.9037
和0.8957。
图11. 5折交叉验证下不同深度学习模型泛化能力的比较:(a) R2;(b) RMSE;(c) MAE
要点:如图11(a)-(c)所示,为了评估和比较模型的泛化能力,本研究对各模型5折交叉验证的R2、RMSE和MAE进行评估与比较。结果显示,FTT模型表现最佳,取得了最高的平均R2(0.9236)、最低的平均RMSE(0.0850)和
MAE(0.0539)。散点紧密聚集,表明FTT模型在不同数据划分下的性能相对一致,展现出良好的稳定性和一致性。因此,本研究选择FTT模型作为CO2甲烷化反应中CO2转化率和CH4产率预测的最佳模型。
图12. 真实数据与(a) TGAN、(b) CopulaGAN、(c) CTGAN和(d) TVAE生成数据之间皮尔逊相关系数的差异
图13. 基于生成数据增强策略的真实数据和生成数据的t-SNE
图:(a) TGAN;(b) CopulaGAN;(c) CTGAN;(d) TVAE
要点:图12通过皮尔逊相关系数评估了TGAN、CTGAN、CopulaGAN和TVAE模型生成数据与真实数据之间变量关系的保留能力,其中TVAE模型表现最佳,其相关系数差异最小。图13的t-SNE可视化进一步证实,TVAE模型生成的数据分布与真实数据最为相似,不仅具有最高的整体覆盖率,还能有效填充真实数据点之间的空白。相比之下,TGAN、CTGAN和CopulaGAN模型在保留复杂变量关系和数据分布相似性方面均表现出明显不足。因此,综合来看,TVAE在生成高质量合成数据方面展现出卓越的性能。
图14. 数据增强后CO2转化率模型(a)和CH4产率模型(b)的拟合图,以及数据增强前后FTT模型(c) R2、(d) RMSE和(e) MAE的比较
要点:图14清晰展示了TVAE模型数据增强对CO2甲烷化反应FTT模型预测性能的显著提升。经过数据增强,CO2转化率和CH4产率的预测散点更紧密地分布在y=x线附近,模型预测稳定性显著提高。同时,
R2大幅提升,而RMSE和MAE则显著降低,表明优化后的FTT模型在准确性和效率上都达到了更高的水平。
图15. 基于SHAP的特征重要性排名:(a) CO2转化率和(b) CH4产率
要点:图15通过SHAP分析揭示了CO2甲烷化反应中各输入特征对CO2转化率和CH4产率预测的重要性排名。结果显示,温度是影响这两种输出的最关键因素。整体而言,反应条件和催化剂性质对模型预测贡献最大,而制备条件影响最小。
图16. 基于SHAP的离散特征对CO2转化率(a、c和e)和CH4产率(b、d和f)的依赖图:(a)-(b) 载体类型;(c)-(d)助剂类型;(e)-(f)制备方法
图17. 最重要连续特征对CO
2甲烷化反应CO2转化率(a、c和e)和CH4产率(b、d和f)的部分依赖图:(a)-(b) AC和T;(c)-(d) AC和BET;(e)-(f) T和CT
要点:图16通过SHAP依赖图揭示了离散特征对CO2甲烷化模型性能的影响,表明CeO2/ZrO
2作为载体、碱性助剂的添加以及湿法浸渍制备方法能显著提升CO2转化率和CH4产率。图17的部分依赖图进一步分析了连续特征,发现活性组分含量在20 wt%以下时性能提升,而反应温度在约330-430℃存在最佳范围,过高温度会因热力学限制导致性能下降。此外,过高的焙烧温度会降低催化剂性能,且活性组分含量对性能的影响大于比表面积。这些分析共同为CO2甲烷化反应提供了关键参数的优化指导,有助于实现更好的催化性能。
图18. 已报道CO2甲烷化催化剂多目标优化过程的帕累托前沿曲线以及优化前后的比较结果:(a)和(c)是以最大化CH4产率同时最小化活性组分含量为目标;(b)和(d)是以最大化CH4产率同时最小化反应温度为目标
图19. 新型CO2甲烷化催化剂的多目标优化与预测:(a)-(b)最大化CH4产率同时最小化活性组分含量所获得的三种催化剂与实验数据的比较,以及(c)-(d)最大化CH4产率同时最小化反应温度所获得的三种催化剂与实验数据的比较
要点:图18展示了FTT模型与MOPSO算法结合优化现有Ni/Al2O3催化剂的成果,成功在降低活性组分含量或反应温度的同时提高了CH4产率。图19则进一步展示了该方法在逆向设计新催化剂方面的应用,预测了六种在低活性组分含量或低温下表现出卓越性能的新型CO2甲烷化催化剂。这些新催化剂的CH
4产率均优于现有实验值,为CO2甲烷化催化剂的探索提供了新方向。
图20. 最佳深度学习模型在六种不同催化剂下预测结果与实验数据的比较
要点:图20展示了优化后的FTT模型在六种不同催化剂体系下对CO2甲烷化反应CH4产率的预测结果,并与新的文献实验数据进行了对比验证。结果表明,模型预测趋势与实验数据高度一致,且所有催化剂系统的预测误差绝对值均低于8%。这充分验证了FTT模型的准确性、鲁棒性及在复杂催化剂系统中的强大泛化能力。
总结与展望本研究提出了一个通过整合仿生优化算法和生成式数据增强技术(BODAL)进行优化的深度学习框架。仿生优化算法与深度学习的结合建立了一种双驱动策略,用于自适应超参数配置和数据增强。这种方法有效克服了传统模型在CO2
甲烷化催化剂筛选和预测方面的局限性。然而,本研究的重点在于验证仿生算法在多目标和高维催化剂优化空间中的优势。需要注意的是,本研究存在一定的局限性:首先,研究范围主要集中在仿生算法,未能与其他优化范式进行全面的横向比较;其次,为研究选择的测试实例可能未能完全涵盖所有实际应用的复杂性。未来,可能值得研究跨范式混合优化器,例如那些将贝叶斯推理与仿生机制相结合的优化器,以弥补单一范式方法的局限性,并进一步提高优化效率和解的质量。

业务介绍
研理云,研之成理旗下专门针对科学计算领域的高性能计算解决方案提供者。我们提供服务器硬件销售与集群系统搭建与维护服务。 ● 配置多样(单台塔式、两台塔式、多台机架式),按需定制,质量可靠,性价比高。
● 目前已经为全国 100 多个课题组提供过服务器软硬件服务(可提供相同高校或临近高校往期案例咨询)。 ● 公司服务器应用工程师具有量子化学、第一性原理、分子动力学等相关学科研究背景。 ● 公司与多位化学、材料领域理论计算方向专家长期合作,一起探索最优服务器软硬件配置和部署。
● 定制化硬件配置:提供售前实例测试,为您提供最合适的硬件配置方案。 ● 一体化软件服务:根据需求,发货前,完成系统、环境、队列、计算软件等所有内容的安装与配置,让您实现开机即用。
● 完善的售后服务:为每位客户建立专属服务群,遇到问题及时解决。大大降低使用学生使用门槛和缓解老师压力。三年硬件质保 + 三年免费软件技术支持。 ● 已购买客户咨询:我们已有超过100位已购买客户,可以给您提供相同城市或者临近城市已购买客户的联系方式,以提供真实案例咨询。 ● 赠送课程学习机会:可选课程包括量子化学(Gaussian),第一性原理,(Vasp),分子动力学模拟(Lammps、Grommacs),钙钛矿计算模拟(Vasp)等。具体赠送方案以沟通结果为准。
更多科研作图、软件使用、表征分析、SCI 写作、名师介绍等干货知识请进入后台自主查询。







