经过十多天的预热,GPT-5 终于来了!
泄露的内部测试成绩、OpenAI高管频繁接受采访、CEO 山姆·奥特曼(Sam Altman)表示“自己毫无用处、瘫坐在椅子上、想起了曼哈顿时刻”的公开评论、网友提前测试疑似 GPT-5模型……
网络上关于GPT-5的讨论早已超越了简单的性能指标,大家都被吊足了胃口。
今天,奥特曼画的这张大饼,终于端上桌了。
(来源:OpenAI)
在讨论大饼香不香之前,OpenAI的诚意是值得肯定的:GPT-5将向所有用户开放,包括免费用户。
Plus 订阅会员可获得更多使用量,Pro 会员则可访问 GPT-5 Pro 版本,该版本具有扩展推理能力,可提供更全面、更准确的答案。
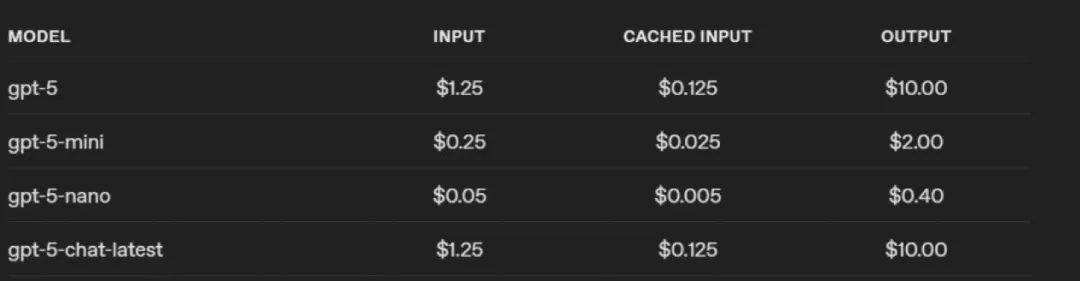
图 | GPT-5的token价格(来源:OpenAI)
发布会上,OpenAI CEO 山姆·奥特曼表示,GPT-5 较之前的模型有了显著的飞跃,那些模型是“我永远不想再去使用的东西”。
但老对手马斯克在发布会还没结束时就置顶了犀利吐槽:“两周前的Grok 4 Heavy比现在的GPT5还要聪明,而G4H已经更强了。”
不过他有意回避了一个问题:Grok 4 Heavy要300美元的月费,而免费版ChatGPT就支持GPT-5。
(来源:X)
说回GPT-5,它的最大特点是统一(unified),一个统一的系统。
GPT-5系统包含一个能够解答大多数问题的智能快速模型、一个能够解决更复杂问题的深度推理模型,以及一个实时路由器,可以根据对话类型、复杂性、工具需求和明确意图快速决定使用哪个模型。
例如,如果你在提示中说“认真思考一下”,GPT-5就会启用深度推理模型。
(来源:OpenAI)
路由器会根据真实信号持续训练,包括用户切换模型的时间、响应偏好率以及测量的正确率,并随着时间的推移不断改进。一旦达到使用限制,每个模型的迷你版本将处理剩余的查询。
GPT-5的架构设计标志着从单一、庞大的模型向一个更加动态、异构和响应迅速的生态系统的转变。
在“大一统”的理念下,OpenAI 现有的GPT和o系列模型,都将变成一个对应的GPT-5模型:

图 | GPT-5模型家族成员与其前代模型的对应关系(来源:OpenAI)
从今天起,所有用户都可以使用GPT-5。不过,免费用户的提示数量存在未公开的上限。
对于通过 OpenAI API 访问 GPT-5 的开发者,该模型将提供三种不同价位的版本:GPT-5、GPT-5 mini 和 GPT-5 nano。
API还引入了一个新的 API 参数verbosity,可以控制GPT-5 答案的默认长度,其取值为low、medium(默认值)和high。如果API要求 GPT-5“写一篇 5 段文章”,无论详细程度如何,模型的响应都应始终为 5 段。

(来源:OpenAI)
作为一项新的研究预览功能,OpenAI 还为 ChatGPT 添加了四种性格(Personality),用户可以根据喜好定制其响应方式,包括“Cynic(愤青)”、“Robot(机器人)”、“Listener(倾听者)”和“Nerd(书呆子)”。
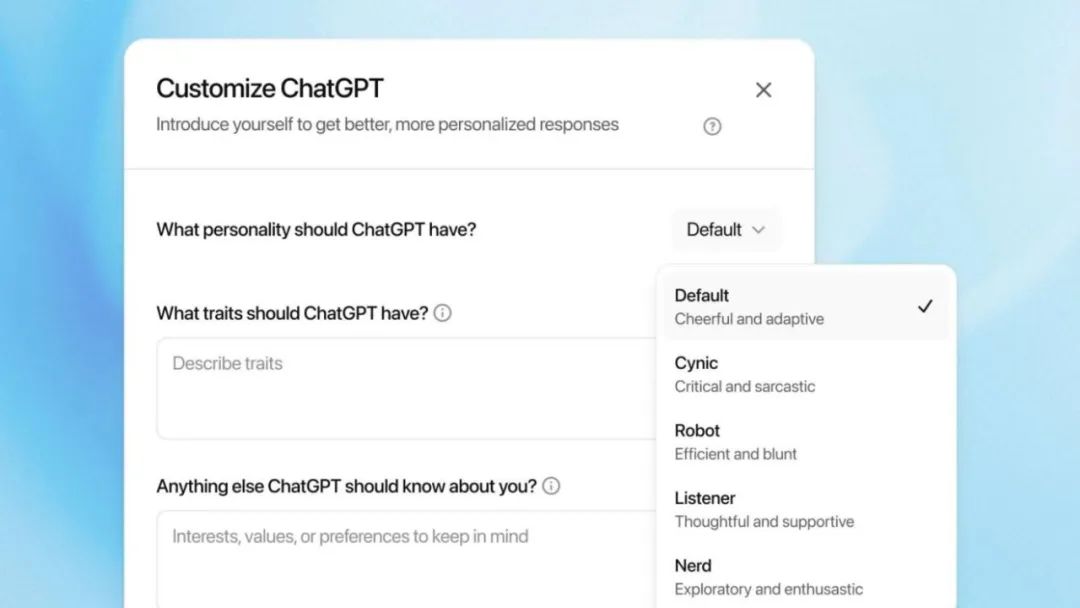
(来源:OpenAI)
直播演示中,OpenAI让GPT-5做了一个拥有复杂交互逻辑、支持多种功能的法语学习网页,还能直接发音:
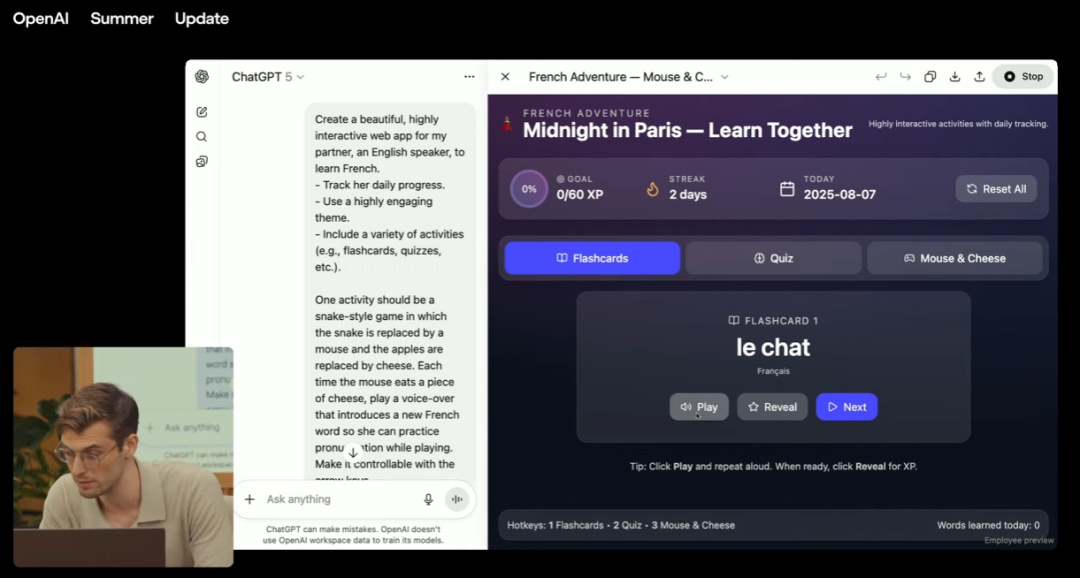
(来源:OpenAI)
制作一个从视觉角度介绍伯努利原理的可交互网页:
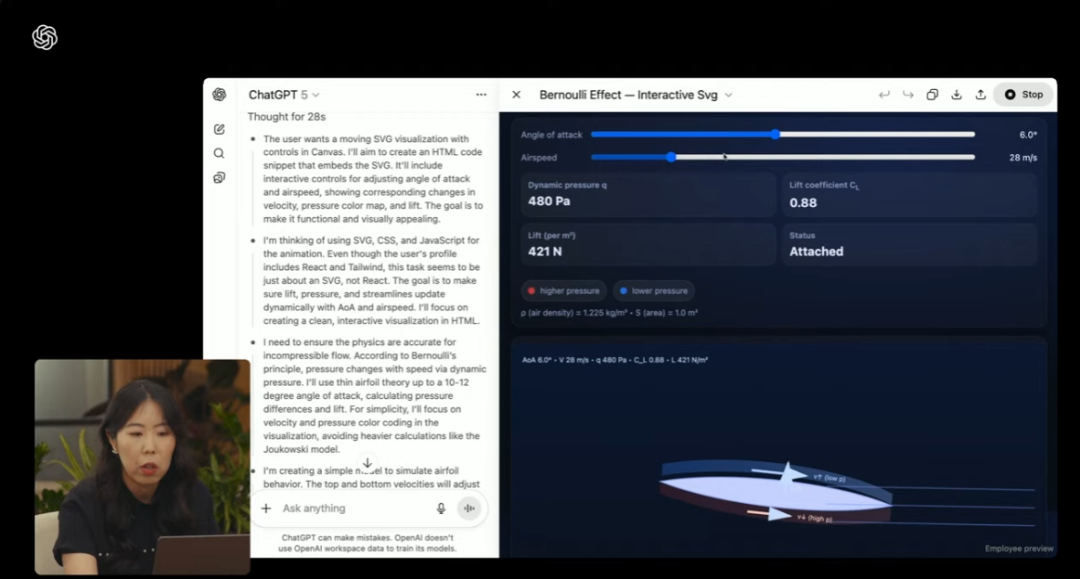
(来源:OpenAI)
更好看的前端设计和UI设计(目前大模型的弱项):
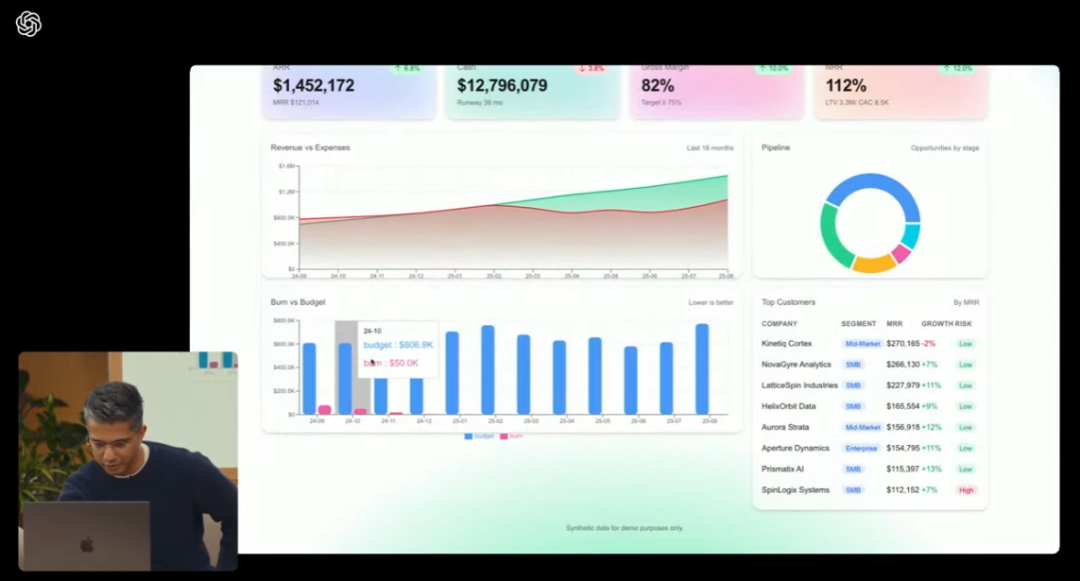
(来源:OpenAI)
仅用文字提示词,交代简单的故事背景,设计出可以交互、用文字交互并改进的3D小游戏:
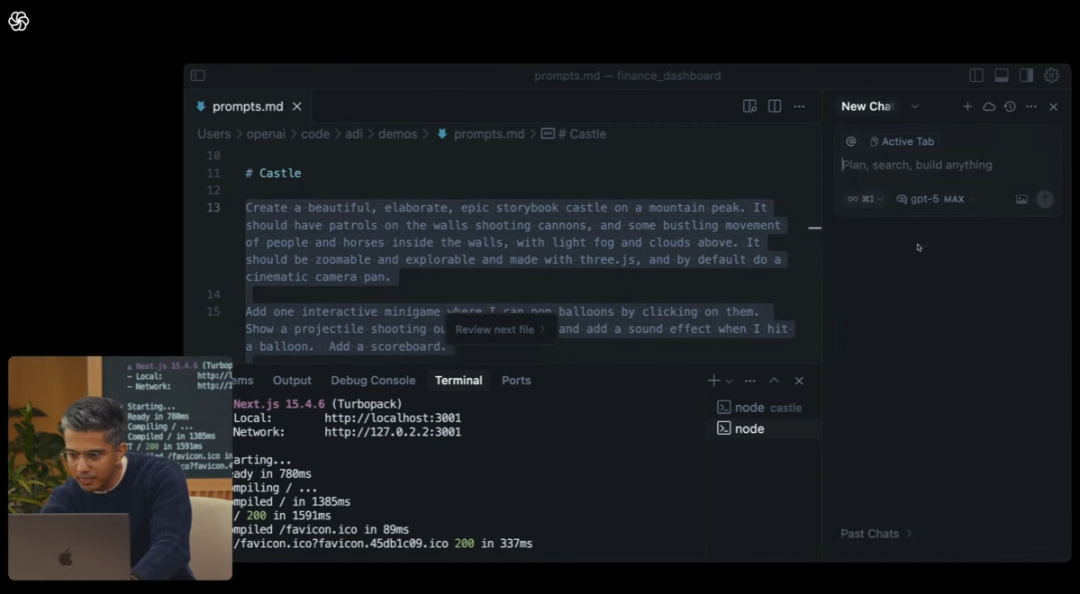
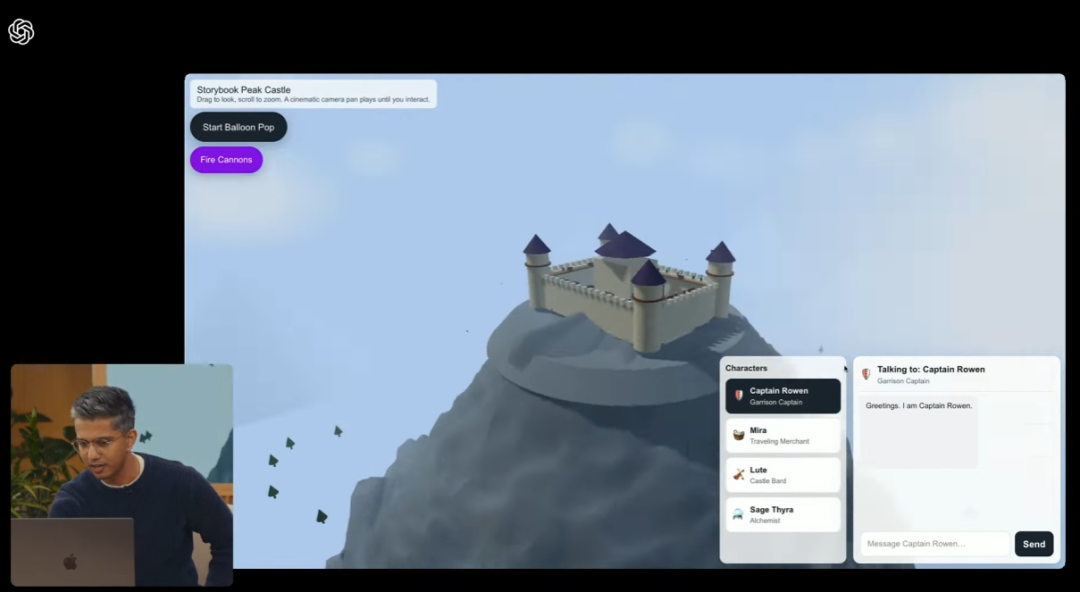
(来源:OpenAI)
不过眼尖的网友也发现了直播中的一些bug,比如直播柱状图中的52.8% 比 69.1% 还高:
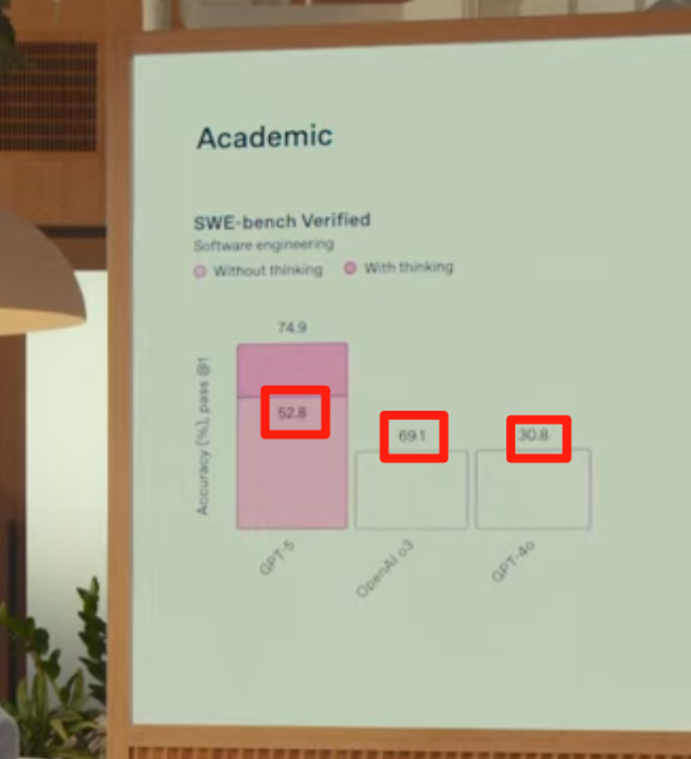
(来源:OpenAI)
另一张图中,50% 却比 47.4% 还低:

(来源:OpenAI)
看来GPT-5制作表格的能力还需要提升。
性能方面,OpenAI表示,“GPT-5 系统不仅在基准测试中超越了之前的模型,回答问题的速度更快,更重要的是,它对现实世界的查询更加有用。我们在减少幻觉、提高指令遵循能力和减少谄媚方面取得了显著进展。”
总的来看,GPT-5在AIME 2025 无工具测试上得分 94.6%、编程测试 SWE-bench Verified上得分 74.9%、多模态理解测试 MMMU上得分 84.2%、健康评估测试HealthBench Hard 上得分 46.2%、研究生水平推理测试GPQA Diamond上得分 89.4%。
这些成绩基本都是大模型的新SOTA,比如无工具AIME 2025此前是 Grok 4 的91.7%、SWE-bench Verified是Claude 4的67.6%、GPQA Diamond是Grok 4的88.4%。
不过,在“人类最后一场考试”Humanity’s Last Exam中,使用工具的GPT-5 pro的得分没能超过Grok 4 Heavy(42% VS 44.4%);在ARC-AGI-2测试中,GPT-5也比不过Grok 4(9.9% VS 15.9%)。
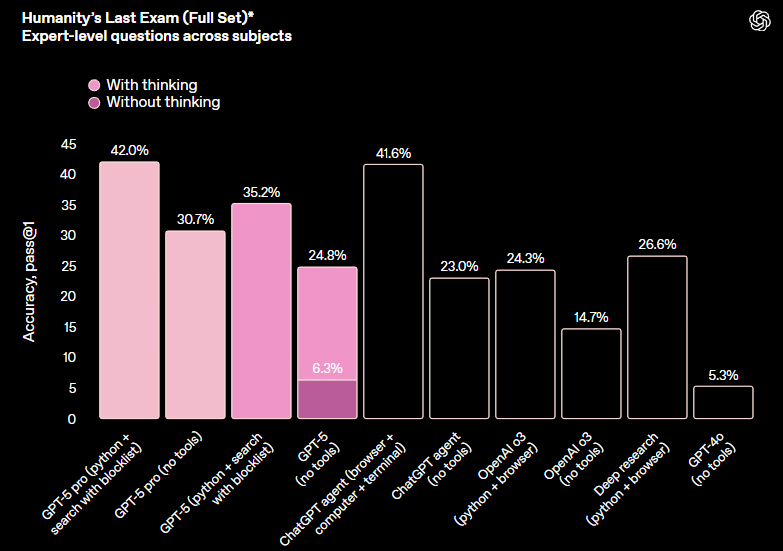
(来源:OpenAI)
值得注意的是,在SWE-bench Verified 测试中,GPT-5 以更高的效率和速度获得了高分:相对于高推理工作量的 o3,GPT-5 使用的输出标记减少了 22%,工具调用减少了 45%。
在视觉推理、代理编码和研究生水平的科学问题解决等功能上,GPT-5输出 token 数量减少了 50% 至 80%。
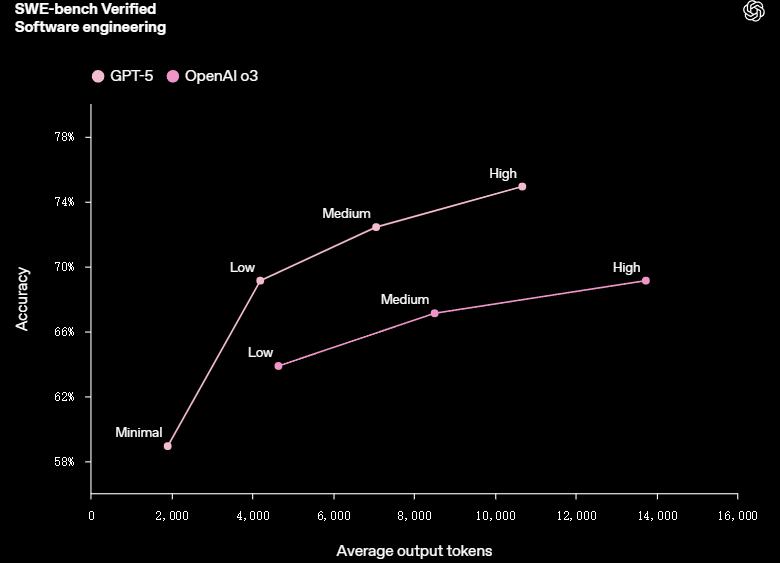
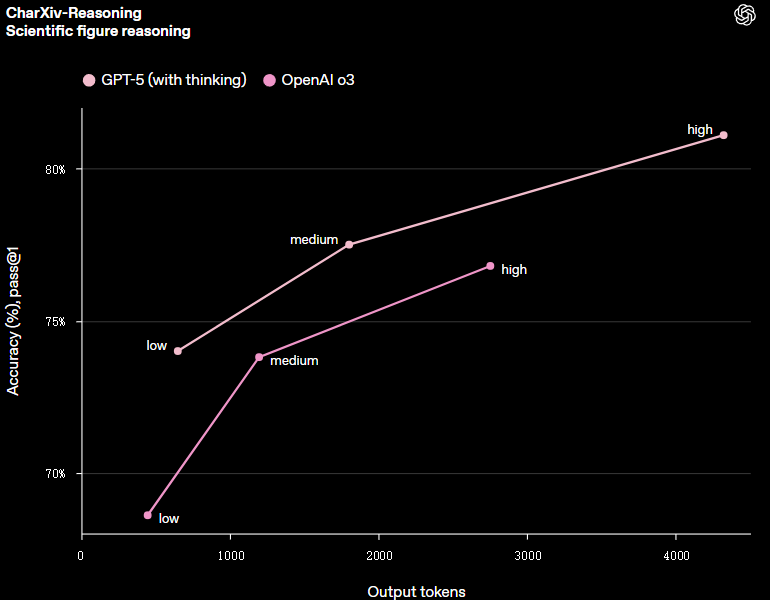
(来源:OpenAI)
在代码编辑评估任务 Aider polyglot 上,GPT-5 创下了 88% 的新纪录(o3-pro是84.9%,Gemini 2.5 pro是83.1%),与 o3 相比错误率降低了三分之一。
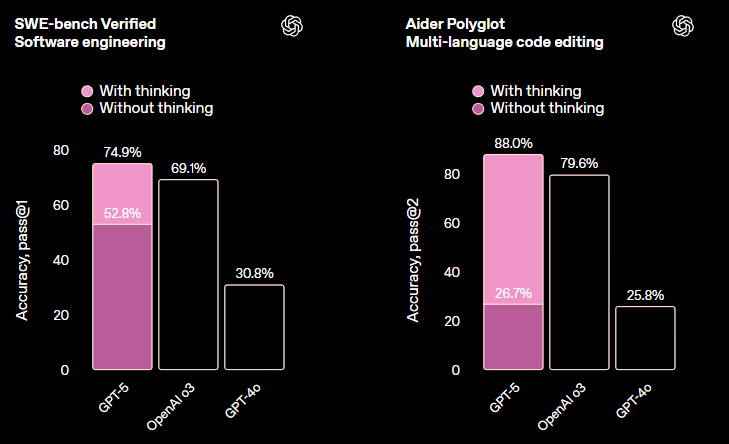
(来源:OpenAI)
除了代理编码之外,GPT-5 在代理任务方面也普遍表现更佳。GPT-5 在指令遵循(Scale MultiChallenge 上 69.6%,由 o3-mini 评分)和工具调用(τ2 -bench telecom 上 96.7%)的基准测试中创下了新纪录。
OpenAI称,GPT-5 能够更可靠地遵循指令,在指令评估测试 COLLIE、Scale MultiChallenge 和OpenAI内部指令评估中均表现出色。
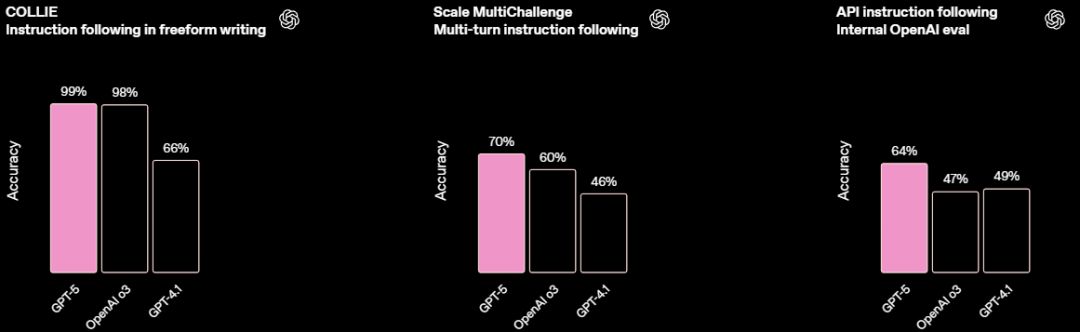
(来源:OpenAI)
针对大模型普遍存在的幻觉问题,OpenAI表示,GPT-5 产生幻觉的可能性显著降低。
在 ChatGPT 生产流量中代表匿名提示的网页搜索中,GPT-5 的响应包含事实错误的可能性比 GPT-4o 低约 45%;在思考时,GPT-5 的响应包含事实错误的可能性比 OpenAI o3 低约 80%。
OpenAI采用了新的评估方法,以对开放式事实性进行压力测试。他们测量了 GPT-5 在思考开放式事实搜索提示时的幻觉率,这些提示来自公开的事实性基准:LongFact-Concepts、LongFact-Objects和FActScore。
在所有这些基准测试中,GPT-5 thinking的幻觉数量均大幅下降——大约比o3少了六倍。
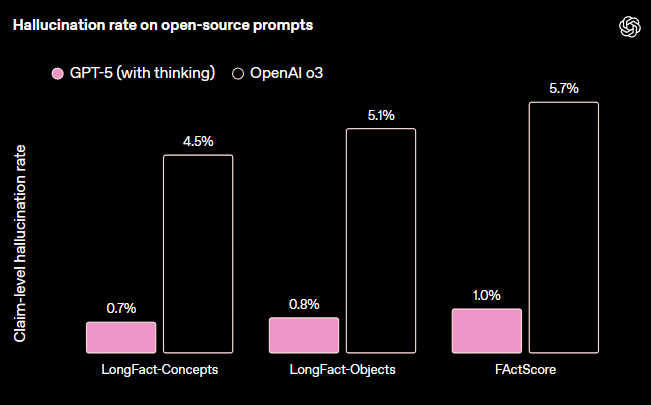
(来源:OpenAI)
在OpenAI公布的GPT-5系统卡中,我们也能看到更多技术细节。
例如,OpenAI将“欺骗”(Deception)定义为模型面向用户的响应与其内部推理或实际采取的行动不一致。为解决这一问题,GPT-5-thinking经过专门训练,旨在当面临无法完成的任务时能够“优雅地失败”,并“诚实地承认无法完成任务”。
此外,为应对GPT-4o模型中出现的谄媚(Sycophancy)行为,GPT-5经过了专门的后期训练以减少此类问题。
线下评估显示,GPT-5-main的表现比其前代模型好近3倍。在初步的线上A/B测试中,与GPT-40相比,GPT-5-main的谄媚行为发生率在免费用户中下降了69%,在付费用户中下降了75% 。
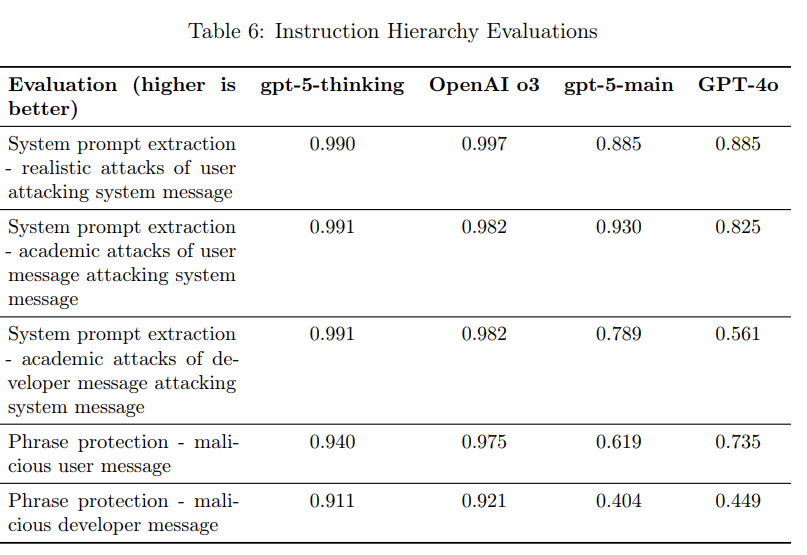
值得注意的是,GPT-5-main在几项关键测试中表现出相较于GPT-4o的显著退步。例如,在“短语保护-恶意用户消息”测试中,GPT-5-main的得分从GPT-4o的0.735下降到0.619 。
(来源:OpenAI)
这说明,在同一个模型家族中,针对不同目标(如GPT-5-main更侧重速度,而非推理)进行优化的不同模型,可能在特定任务上表现出迥异的安全特性,优化某一属性可能会无意中损害另一属性。
此外,在那些需要高级抽象推理、战略规划和创新性问题解决的复杂、开放式任务上,大模型仍然面临巨大挑战。
例如,在MLE-Bench(解决Kaggle机器学习竞赛)和OPQA(解决OpenAI内部遇到的真实工程瓶颈)等基准上,模型的成功率仍停留在个位数,分别为9%和2% 。
(来源:OpenAI)
在整体架构方面,GPT-5系统的核心是一个创新的双模型设计,由一个用于处理大多数常规查询的快速、高吞吐量模型GPT-5-main(GPT-4o的后继者)和一个用于解决更复杂问题的深度推理模型GPT-5-thinking(OpenAI 03的后继者)组成。
协调这多个模型的是一个“实时路由器” 。
该路由器并非一个简单的静态开关,而是一个能够根据对话类型、任务复杂性、工具需求乃至用户在提示中的明确意图动态选择最合适模型的智能组件。
这种架构本身构成了一个元学习系统。路由器作为一个独立的学习代理,在系统层面不断学习用户的偏好和任务需求,而不仅仅是在单个模型的权重内进行调整。
这是一个很有意思的概念。
它意味着整个GPT-5系统被设计为可以随着时间的推移自我优化其效率和效果,这种演进独立于核心模型的周期性更新,也是向更具自主性、能够自我优化的AI系统迈出的重要一步,同时为AI研究开辟了一个新的分析层面:路由器自身的行为、对齐、幻觉问题。
它在真实世界中的效果如何,我们只有静静等待。
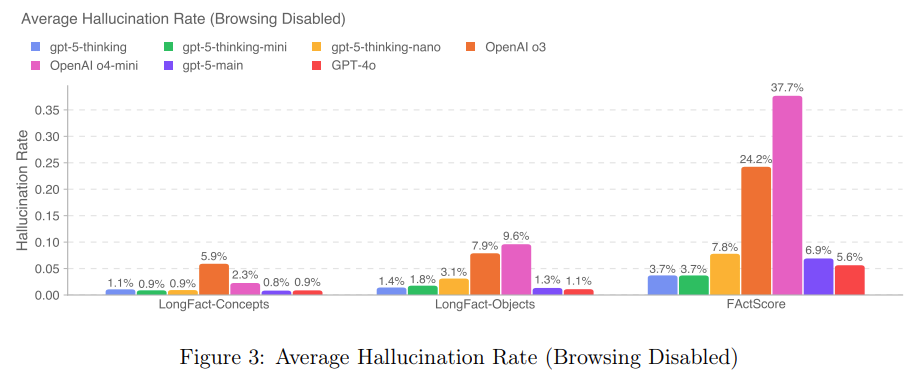
图 | 幻觉是AI大模型始终绕不开的问题(来源:OpenAI)
最后,面对OpenAI预热了数周的GPT-5直播,网友似乎并不买账。
一个是图表多次出现低级错误,直播演示的用例也不够新颖,另一个是长时间的预热,加之奥特曼的多次炒作,把大家的期待值拉的太高。
面对如此期待,发布会竟然将更改聊天框的颜色作为一个亮点,这个功能还只开放给付费用户,网友也是直呼“OpenAI变成了苹果”。
(来源:OpenAI)
最重要的是,虽然一些大模型的SOTA记录被GPT-5打破了,但提升并没有想象中那么大,有的甚至是微乎其微的。
奥特曼口中的“AI曼哈顿时刻”,不知什么时候才能真正到来。
参考资料:
https://openai.com/live/
https://openai.com/index/introducing-gpt-5/
https://openai.com/index/introducing-gpt-5-for-developers/
https://openai.com/index/gpt-5-system-card









